 As mentioned, DevOpsDays Austin 2019 went off great! And after the event, we sent out extensive surveys to attendees, sponsors, volunteers, speakers, and even the organizers to learn and improve. (Thanks to everyone who gave their feedback, we appreciate it!)
As mentioned, DevOpsDays Austin 2019 went off great! And after the event, we sent out extensive surveys to attendees, sponsors, volunteers, speakers, and even the organizers to learn and improve. (Thanks to everyone who gave their feedback, we appreciate it!)
Last year we also did an extensive retrospective to figure out how we wanted this year to go, and this year’s event was driven by that feedback and our vision to make DoD Austin the place for practitioners to come, learn from each other, and build the local community.
Let me share this year’s retro with you – some of the numbers and sentiments are below with my thoughts. If you want the full details, sure, here you go!
Full DevOpsDays Austin 2019 Retrospective (pdf)
If you’re not familiar with a NPS score, it’s used to measure sentiment on a scale from -100 to +100. When you get asked “would you recommend” something on a 1-10 scale, generally they’re taking that number and bucketing it into 1-6 being detractors (counted as negative), 7-8 being neutral, and 9-10 being promoters (counted as positive). Above 0 is “good”, above 50 is “excellent.” See more about NPS scores here.
Sorry about the quality of the pics, these are basically ones I snapped myself on my iPhone. But hopefully they show some of what happened at the event!
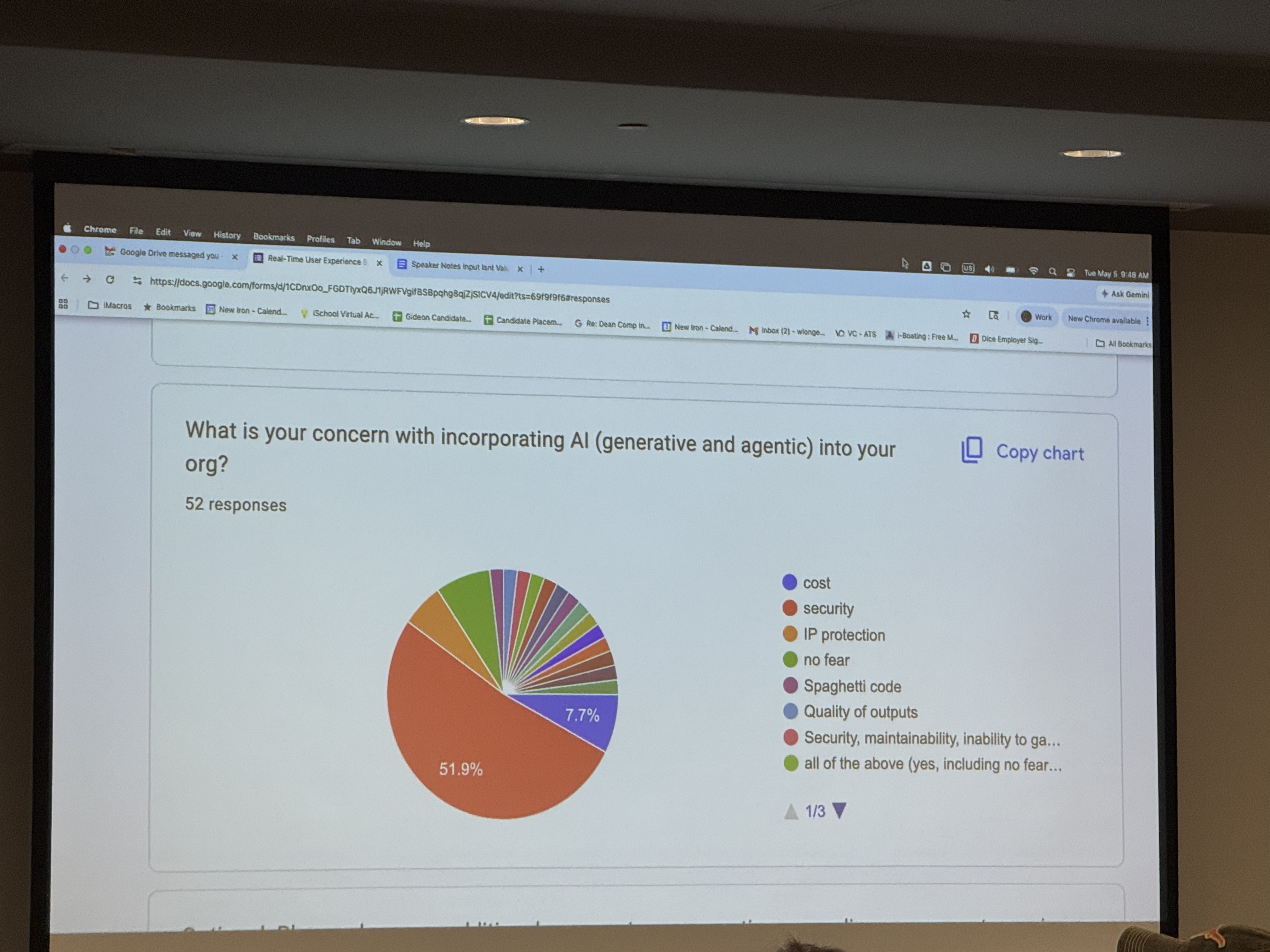
Attendee Feedback (62 NPS, 50 responses)

Damon Edwards
“Informative, laid back, friendly, humorous event. My favorite conference for a couple of years now.” 84% of attendees said they were likely to return.
The things people liked the most as measured by the freeform comments were the openspaces (9 comments), the speakers/talks, especially their diversity (8 votes), the culture/atmosphere of the event (5 votes), and the community and people (5 votes).
This makes me happy. DevOpsDays isn’t just “a conference,” it really focuses on building community – people meeting each other in a friendly and collaborative environment. The content is nice but it’s not the primary value of the event.

Mandy Whaley
Concerns people had the most were “Nothing/great job” (10 votes), difficulty with travel and parking at the venue, including handicap access (6 votes), talks (6 votes), we want better lunches (4 votes).
Read on for more but we’re probably changing venues next year and will keep access in mind. Now on the lunches – we used to have fancy lunches and they were a significant time and effort sink, with long lines, lots of time spent, and so on. We moved to box lunches and now lunch goes fast and easy and leaves everyone more time to interact with each other. We do not plan to ever change back from that, but we will see if we can get a BBQ place or something to do a nice lunch box.
(There were more likes and dislikes and we are evaluating action on all of them, but dang this post is going to be long already so I’m focusing on the top line items.)
Speaker Feedback (90 NPS, 10 responses)

Pete Cheslock
- “Everyone was really positive; welcoming, low-pressure environment.”
- Experience – 50% excellent, 50% very good
- Organization – 40% extremely, 50% very organized
- Friendliness – 90% extremely, 10% very friendly
Likes: No tech problems/helpful techs/setup organized (x4), Supportive/welcoming (x3), Engaged audience (x3). Dislikes: Chromebook support problem, schedule slippage, openspaces competing with Conversations talks.
Great overall, some things for us to tweak! After several years in the same venue and buying a lot of gear, our crack AV team have the tech end of it pretty much down pat.

Jon Loyens
Organizer Feedback (88 NPS, 8 responses)
- “Just [wanted] to say how much I enjoy working with the crew and watching it all come together to put on a great event for the community. I get a lot out of doing it each year and see my contribution as an important way to give back.”
- Time spent – 62.5% just right, 12.5% little long, 12.5% little short, 12.5% way too short
- 93% likely to return (the one that isn’t pleaded a heavy year at work coming up)
Major likes included working together (x3), inclusion (x2), and the opportunity to give back (x2). Dislikes included some stressing out and looking for problems, and speaker notification happening late. There was good discussion about explaining openspaces more especially for the newer folks.
It’s important to me that our organizers have a good time too – my assigned domain on the organizer team is “Organizers” – besides working the master budget and schedule for folks, I facilitate and try to ensure that this volunteer gig is not onerous, and I’m happy we seem to be there.

Deborah Hawkins
Volunteer Feedback (94 NPS, 17 responses)
- Experience: 72.7% excellent, 27.78% very good
- How much time you spend – 83% about right, 11% too much, 6% too little
- 93% likely to return
We have a lot of volunteers from the community that come to slave away working the event for a free ticket and a couple meals, basically. It’s very important to all of us that they have a good experience – these are the future organizers, and community members going above and beyond to give back to the community. Boyd and Daria and the other organizers did a great job both organizing the work and making sure the volunteers had time to participate in the event and have a good experience – even given the storm-nightmare loadout at the end of the event. Thanks to all our great volunteers!
Sponsor Feedback (60 NPS, 10 responses)
- “A++ highly recommend, etc. Y’all did a bang-up job putting this together, and the community is certainly a testament to your hard work and continuous efforts. I’ve told everyone at HQ that we need to learn from you.”
- Experience – 70% excellent, 20% very good, 10% good
- Liked: “Always a great event – excellent sessions, great opportunities to meet with customers and prospects.” Vendor area good. Friendly people and networking.
- Disliked: Platinum sponsors were upstairs. Water bottles ran out. We want badge scanners. No day before setup. Only 1 minute blurb. Schedule off track. When will courtesy shipping be picked up.
 So… Sponsors. For a number of years we kept expanding our sponsor offerings. Then we realized the event had become too much of a traditional conference and we were spending lots of space, time, and effort on sponsors, when to be honest we don’t really need all that much money to put on the event. Two years ago after a bunch of sponsor problems and everyone working themselves to the bone to provide professional conference services I did away with sponsor tables altogether. We let them back this year but really wanted to make the event not about that. We also warn the sponsors up front this isn’t a “churn the leads” event, we want sponsors who are going to send technical people to engage with the community.
So… Sponsors. For a number of years we kept expanding our sponsor offerings. Then we realized the event had become too much of a traditional conference and we were spending lots of space, time, and effort on sponsors, when to be honest we don’t really need all that much money to put on the event. Two years ago after a bunch of sponsor problems and everyone working themselves to the bone to provide professional conference services I did away with sponsor tables altogether. We let them back this year but really wanted to make the event not about that. We also warn the sponsors up front this isn’t a “churn the leads” event, we want sponsors who are going to send technical people to engage with the community.
Did it work out that way? Kinda. There’s too much expectation set up about what “conferences are like” and “DevOpsDays are like” and between the person purchasing the sponsorship and the people actually sent on site there’s a lot of room for expectations to drift.

Tristan Slominski
I feel like there’s plenty of big conferences for that kind of sponsor engagement. DevOpsDayses didn’t used to be like that, but as time goes on and they all grow it’s tempting to “improve” by making it more sponsor focused. We love sponsors who engage with the community but we consciously balance their participation in the event.
Funny story… Like I said we only let sponsor tables back on a limited basis this year. But there was a run on them, and we sold out of the ones we needed to fund the event quickly and had a bunch of sponsors still wanting to participate, including ones who had participated for years. So we extended the sponsor room, just to let them participate, because we felt bad about excluding them. So we always sell out, so that’s probably a sign that we’re doing fine there.
And we got to sponsor a house for the homeless with the spare money, so that’s spiffy.
Recruiter Feedback (-50 NPS, 2 responses)
This is a new addition that didn’t work out so well. We had imagined a big recruiter speed dating thing. But few recruiters and attendees signed up for it so we pivoted into a recruiter fair. It was during happy hour, but half the attendees leave before that. We had them by the bar, but the DevOps Trivia during the happy hour was also a big draw.
While all the recruiters rated their experience “good” they had low traffic.
So, sorry that didn’t work out. But I stressed to the organizers that this wasn’t a failure – if we don’t try new things that don’t work out sometimes, we’re not trying hard enough.
We’re one of the great grand-daddy DevOps events. We have years of experience, ample funding, and a big community. Smaller DoDs, especially ones getting off the ground, often need to hew close to the “standard format” for a safe launch and to pay their bills. We can afford to experiment, so I strongly urge the team every year to try different things. It’s OK if we appeal to different sets of the community each year. It’s OK to not do something again (even if it went well) and it’s OK to try new things as stretch goals. I kinda like putting how we run our event where our DevOps mouth is, so to speak.
This lets us try things out first. We were the first DoD with a multi-content track. We created the new “Conversations” talk format this year. We keep innovating, and sometimes there’s just not a fit given the constraints of venue, time, people, and so on. So this one didn’t go off great, but to me that just means we’re legitimately experimenting hard enough.
Ernest’s Retrospective Thoughts
Overall it went great! Smooth, excellent execution by everyone involved. I feel like the Austin tech community is stronger for our event existing and that’s what I want out of it.
My main challenge personally this year was with the talks.
We really went into this year with an intent to curate the talks to a pretty specific practitioner format. DoD Austin has a bunch of years behind it so we don’t necessarily need the DevOps “talk circuit” talks to fill slots. We feel like we can be very specific about the experience we want to curate – no repeat talks from other events (go watch them on the Internet, everyone posts videos!), some preference to local speakers, encourage diversity both in speakers and in content… But we didn’t execute on that well. We started using Papercall this year and it makes it easy for people to mass submit to multiple events – a great feature but somewhat antithetical to our needs. We had 200 submissions for 20 slots and had a lot of weeding to do and had to turn away a lot of folks. And while we had good talks, they didn’t fit our proposed theme necessarily.
We also just selected talks late, to where it risked people whose talks were declined not being able to attend because we sold out our attendee cap.
The second challenge was with openspaces. In general the larger the event, the harder it is to make openspaces work. Once there’s more than 25 people in an openspace the format collapses and it’s just “2-3 people talking to each other and everyone else straining to hear,” basically a super crap panel talk. Putting them in the luxury boxes in the stadium worked really well there, because only so many people can fit into one, so it was a forcing function to keep them small enough to work. So they went well overall.
But some folks didn’t like them. Each year we get some feedback from folks more used to traditional content. “Maybe we should get the openspace topics submitted before the conference so they’re already on the schedule!” No offense, but over my dead body. That’s not what openspaces are about and openspaces are the heart of DevOpsDays. They are for what the actual attendees want to talk about right then; the entire point is that they’re not programmed content. Early DevOpsDays were a couple talks and then pretty much all openspaces. My general attitude is “if you don’t want to participate in openspaces, this is not the event for you.” We need to explain openspaces more ahead of time though, to seed ideas and get new people to understand the format. Our experiment with mini-talks and then linked openspaces worked out great, I went to two of them and got high value out of them.
Next Year
A couple big changes are coming next year.
First of all, we’re probably changing venue. We’ve enjoyed the stadium a lot, and love the staff there, but we’ve probably done as much as we can with the event in that particular form factor.
We’re considering going entirely to the new 20 minute talk format. They were well received – if you really have more content than 20 minutes, a linked openspace is probably the best venue to explore it with highly engaged attendees! And it’ll prevent people just submitting their “same talk” as much. We can also get more speakers in!
Also, we know it’s a bummer that we’ve been capping attendance and sponsors and that people who want to attend get turned away. So far we’ve felt like we have had to, both because of venue capacity but also to keep openspaces good and keep the great atmosphere and community and opportunities for engagement that make our event distinct.
Now that we have enough experience, we think we might be able to go bigger and still keep the small group and one-on-one interaction. We’ve all been to a bunch of conferences and seen other things – 1-1 mentoring table signups, for example, and other formats that facilitate it. We’re also thinking about adding some “working groups” – opportunities to do something, produce position papers, whatnot, give the experts a really neat thing to do at the event.
And maybe even add on a third day, with all unstructured content. On a Saturday so people could bring their kids and stuff.
I wanted to just blaze big next year; the rest of the team loved the vision but reminded me how much burn-in there is on a new venue – getting A/V figured out, all the rough spots of a year one… So we may iterate into it, with getting a new venue and going slightly larger and trying out new engagement ideas next year, and then the year after saying “Big tent! All are welcome! Fly in for this one, no attendee or sponsor caps!” and making it a heroically sized event.
There’s no one right format for DevOpsDays – I encourage other organizers to keep experimenting as well. Your event doesn’t have to be the same year to year; you can target different goals and audiences and sizes and such each time.
If anyone read this far, feel free and comment with your thoughts below! (Obligatory disclaimer, don’t tell me “well this isn’t right for my DevOpsDays” – that’s fine, none of this is to declare the “right” way to do an event, it’s just what is working for us in our community with our particular goals.)





































 The businesses aren’t just for the residents – you can go there to the garage and pay to get your oil changed. You can go attend their movie nights (the Alamo donated a projector) that are open to the public like any movie night in any park. They do things like a trail of lights during the holidays. There’s plenty of reasons for non-residents to go there, it’s not a “camp.” It’s just a subdivision, really, like any other one you’d drive through in Austin.
The businesses aren’t just for the residents – you can go there to the garage and pay to get your oil changed. You can go attend their movie nights (the Alamo donated a projector) that are open to the public like any movie night in any park. They do things like a trail of lights during the holidays. There’s plenty of reasons for non-residents to go there, it’s not a “camp.” It’s just a subdivision, really, like any other one you’d drive through in Austin. Heck, you can go live there. 170 of the occupants are former homeless, but there are also many “
Heck, you can go live there. 170 of the occupants are former homeless, but there are also many “ You can help even by just going there, using the businesses, interacting with the residents to weave them into the fabric of Austin. Go on a tour to see what they’re doing out there. Bring your kids! We all had a great and deeply moving family outing in our visit to the Village.
You can help even by just going there, using the businesses, interacting with the residents to weave them into the fabric of Austin. Go on a tour to see what they’re doing out there. Bring your kids! We all had a great and deeply moving family outing in our visit to the Village.