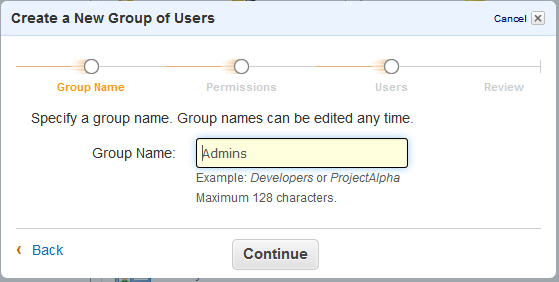
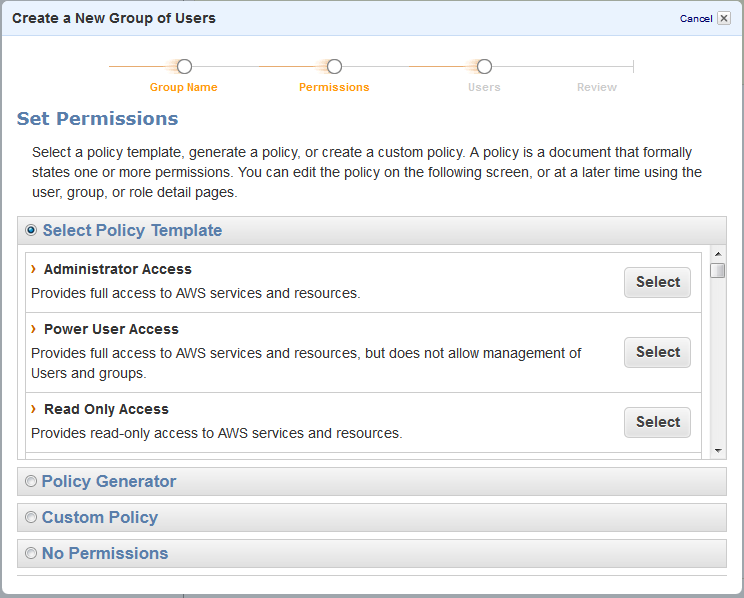
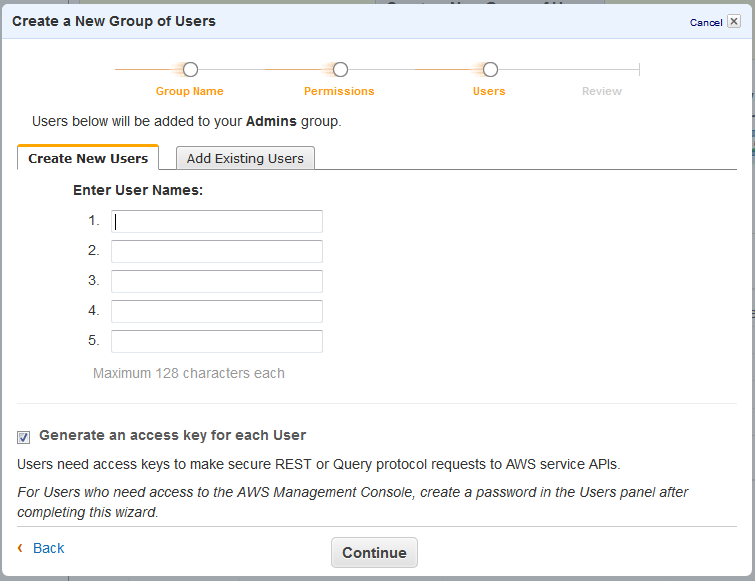
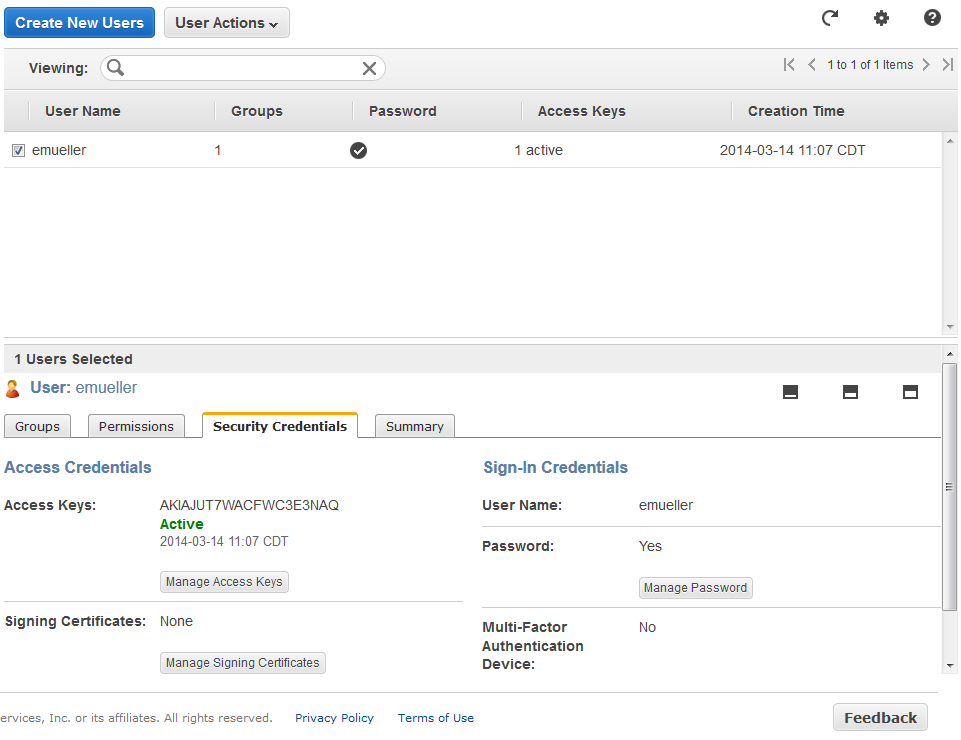
After John Allspaw and Steve Souders caper about in fake muscles, we get started with the keynotes.
Jay Parikh, Facebook, spoke about building for a billion users. Several folks yesterday warned with phrases like “if you have a billion users and hundreds of engineers then this advice may be on point…”
Today in 30 minutes, Facebook did…
- 10 TB log data into hadoop
- Scan 105 TB in Hive
- 6M photos
- 160m newsfeed stories
- 5bn realtime messages
- 10bn profile pics
- 108bn mysql queries
- 3.8 tn cache ops
Principle 1: Focus on Impact
Day one code deploys. They open sourced fabricator for code review. 30 day coder boot camp – Ops does coder boot camp, then weeks of ops boot camp. Mentorship program.
Principle 2: Move Fast
- Commits scale with people, but you have to be safe! Perflab does a performance test before every commit with log-replay. Also does checks for slow drift over time.
- Gatekeeper is the feature flag tool, A/B testing – 500M checks/sec. We have one of these at Bazaarvoice and it’s super helpful.
- Claspin is a high density heat map viewer for large services
- fast deployment technique – used shared memory segment to connect cache, so they can swap out binaries on top of it, took weeks of back end deploys down to days/hours
- Built lots of ops tools – people | tools | process
Random Bits:
- Be bold
- They use BGP in the data center
- Did we mention how cool we are?
- Capacity engineering isn’t just buying stuff, it’s APM to reduce usage
- Massive fail from gatekeeper bug. Had to pull dns to shut the site down
- Fix more, whine less
John Rauser, Amazon data scientist, on investigating anomalies. He gave a well received talk on statistics for operations last year.
He used a very long “data in the time of cholera” example. Watch the video for the long version.
You can’t just look at the summary, look at distributions, then look into the logs themselves.
Look at the extremes and you’ll find things that are broken.
Check your long tail, monitor percentiles long in the tail.
Mike Brittain, Etsy on Building Resilient User Experiences – here’s the video.
Don’t mess up a page just because one of the 14 lame back end services you compose into it is down. Distinguish critical back end service failures and just suppress other stuff when composing a product page. Consider blocking vs non-blocking ajax. Load critical stuff synchronously and noncritical async/not at all if it times out.
Google apps has the nice problem/retrying in an interval messages (use exponential back off in your ui!)
Planning for 100% availability is not enough; plan for failure. Your UI should adapt to failure. That’s usually a joint dev+ops+product call.
Do operability reviews, postmortems. Watch your page views for your error template! (use an error template)
Speeding up the web using prediction of user activity
Arvind Jain/Dominic Hamon from Google – see the video.
Why things would be so much faster if you just preload the next pages a user might go to. Sure. As long as you don’t mind accidentally triggering all kinds of shit. It’s like cross browser request forgery as a feature!
<link rel=’prerender’> to provide guidance.
Annoyed by this talk, and since I’ve read How Complex Systems Fail already, I spent rest of the morning plenary time wandering the vendor floor
From the famous and irascible Theo Schlossnagle (@postwait). Here’s the slides.
Monitor what matters! Most new big data problems are created by our own solutions in the first place, and are thus solvable despite their ROI. e.g. logs.
What’s the cost/benefit of your data?
Don’t erode granularity (as with RRD). It controls your storage but your ability to, say, do YOY black friday compares sucks.
As you zoom in you see obscured major differences and patterns.
There’s a cost/benefit curve for monitoring that goes positive but eventually goes negative.Value=benefit-cost. So you don’t go to the end of the curve, you want the max difference!
Technique 1: Text
Just store changes- be careful not to have too many changes and store them
Technique 2: Numeric
store rollups, over 1 minute min/max/avg/sttdev/covar/50/95/99%
store first order derivative and then derivative of that (jerkiness)
db replication – lag AND RATE OF LAG CHANGE
“It’s a lot easier to see change when you’re actually graphing change”
Project numbers out. Graph storage space doing down!
With simple numeric data you can do prediction (Holt-Winters) even hacked into RRD
Technique 3: Histograms
about 2k for a 1 minute histogram (5b for a single bucket)
Event correlation – change mgmt vs performance, is still human eye driven
Monitor everything.
- the business – financials, marketing, support! problems, custsat, res time
- operations! durr
- system/db/yeah
- middleware! messaging, apis, etc.
They use reconnoiter, statsd, d3, flot for graphing.
This was one of the best sessions of the day IMO.
Carlos from Facebook on routing users to the closest datacenter with Doppler. Normal DNS geo-routing depends on resolvers being near the user, etc.
They inject js into some browsers and log packet latency. Map resolver IP to user IP, datacenter, latency. Then you can cluster users to nearest data centers. They use for planning and analysis – what countries have poor latency, where do we need peering agreements
Akamai said doing it was impractical, so they did it.
Amazon has “latency based routing” but no one knows how it works.
Google as part of their standard SOP has proposed a DNS extension that will never be adopted by enough people to work.
Looking at log-normal perf data – look at the whole spread but that can be huge, so filter then analyze.
Margin of error – 1.96*sd/sqrt(num), need less than 5% error.
How does performance influence human behavior?
Very fast sessions had high bounce rates (probably errors)
Strong bounce rate to load time correlation, and esp front end speed
Toxicology has the idea of a “median lethal dose”- our LD50 is where we pass 50% bounce rate
These are: Back end 1.7s, dom load 1.8s, dom interactive 2.75s, front end 3.5s, dom complete 4.75s, load event 5.5s
by James Turnbull! Here’s the slides.
Rollback is BS. You are insane if you rely on it. It’s theoretically possible, if you apply sufficient capital, and all apps are idempotent, resources…
- Solve for availability, not rollback. Do small iterative changes instead.
- Accept that failure happens, and prevent it from happening again.
- Nobody gives a crap whose fault it was.
- Assumption is the mother of all fuckups.
- This can’t be upgraded like that because… challenge it.
by Michael Nygard (@mtnygard) – Slides are here. For more see his pragmatic programmers book Release It!
Failures come in patterns. Here’s some major ones!
Integrations are the #1 risk to stability, from both “in spec” and “out of spec” errors. Integrations are a necessary evil. To debug you have to peel back the layers of abstraction; you have to diagnose a couple levels lower than the level an error manifests. Larger systems fail faster than small ones.
Chain Reactions – #2!
Failure moves horizontally across tiers, search engines and app servers get overloaded, esp. with connection pools. Look for resource leaks.
Cascading Failure
Failure moves vertically cross tiers. Common in SOA and enterprise services. Contain the damage – decouple higher tiers with timeouts, circuit breakers.
Blocked Threads
All threads blocked = “crash”. Use java.util/concurrent or system.threading (or ruby/php, don’t do it). Hung request handlers = less capacity and frustrated users. Scrutinize resource pools. Decompile that lame ass third party code to see how it works, if you’re using it you’re responsible for it.
Attacks of Self-Denial
Making your own DoS attack, often via mass unexpected promotions. Open lines of communication with marketers
Unbalanced Capacities
Your environment scaling ratios are different dev to qa to prod. Simulate back end failures or overloading during testing!
Unbounded result sets
Dev/test have smaller data volumes and unreal relationships (what’s the max in prod?). SOA with chatty providers – client can’t trust not being hurt. Don’t trust data producers, put limits in your APIs.
Stability patterns!
Circuit Breaker
Remote call wrapped with a retry loop (always 3!)
Immediate retries are very likely to fail again – TCP fixes packet drops for you man
Makes the user wait longer for their error, and floods the servers (cascading failure)
Count failures (leaky bucket) and stop calling the back end for a cool-off period
Can critical work be queued for later, or rejected, or what?
State of circuit breakers is a good dashboard!
Bulkheads
Partition the system and allow partial failure without losing service.
Classes of customer, etc.
If foo and bar are coupled with baz, then hitting baz can bork both. Make baz pools or whatever.
Less efficient resource use but important with shared-service models
Test Harness
Real-world failures are hard to create in QA
Integration tests don’t find those out-of-spec errors unless you force them
Service acting like a back end but doing crazy shit – slow, endless, send a binary
Supplement testing methods
Ken King/James Sheridan, Yammer
They started in a colo.
Dual network, racks have 4 2U quad and 10 1Us
EC2 provides you: network, cabling, simple load balancing, geo distribution, hardware repair, network and rack diagrams (?)
There are fixed and variable costs, assume 3 year depreciation
AWS gives you 20% off for 2M/year?
Three year commit, reserve instances
one rack one year – $384k cool, $378k ec2, $199k reserved
20 racks one year – $105k colo, $158 ec2 even with reserve and 20% discount
20 racks 3 years – $50k colo, $105k ec2
But – speed (agility) of ramping up…
To me this is like cars. You build your own car, you know it. But for arbitrary small numbers of cars, you don’t have time for that crap. If you run a taxi fleet or something, then you start moving back towards specialized needs and spec/build your own.
Colo benefits – ownership and knowledge. You know it and control it.
- Load balancing (loadbalancer.com or zeus/riverbed only cloud options)
- IDS etc. (appliances)
- Choose connectivity
- know your IO, get more RAM, more cores
- Throw money at vertical scalability
- Perception of control = security
Cloud benefits – instant. Scaling.
- Forces good architecture
- Immediate replacement, no sparing etc.
- Unlimited storage, snapshots (1 TB volume limit)
- No long term commitment
- Provisioning APIs, autoscaling, EU storage, geodist
Hybrid.
- crocodoc and encoder yammer partners are good to be close to
- need to burst work
- dev servers, windows dev, demo servers banished to AWS
- moving cross connects to ec2 with vpc
Whew! Man I hope someone’s reading this because it’s a lot of work. Next, day three and bonus LSPE meeting!