
Check out agile admin James Wickett’s talk from DeliveryConf last month on adding security into your continuous software delivery pipeline!
Check out agile admin James Wickett’s talk from DeliveryConf last month on adding security into your continuous software delivery pipeline!
Filed under Conferences, DevOps, Security
The word is out, at RSA this week Shannon Lietz (@devsecops), James Wickett (@wickett), John Willis (@botchagalupe), and myself (Ernest Mueller, @ernestmueller) did a panel on our upcoming book, the DevSecOps Handbook. We’re still writing it, and we want to make you a part of it!
Like the DevOps Handbook, also from IT Revolution Press, the heart of the book is case studies from practitioners like you. Have you done something DevSecOpsey – adapted the culture of infosec/appsec to work better with your product teams, added security testing to your CI pipeline, added instrumentation and feedback loops for your security work, or other security-as-code kind of work? Well, we want to hear from you!
We are interested in successes and failures, in both advanced implementation and people taking their first step – others will benefit from your experience in any of these cases. You can be hardcore security dipping your toes into devops, hardcore dev or ops dipping into security, or someone getting started on the whole ball of wax. Don’t worry, we’re not asking you to write anything, we can interview you and do all the heavy lifting. Not sure if your company will sign off? We can anonymize it, or if it’s been published publicly as conference proceedings or whatnot then journalism rules apply, we’ll just cite prior work.
To contact us, email book@devsecops.org or go to devsecops.org and fill out the form there. Or if you already know one of us, ping your favorite!

We’re ready to believe you!
This Thursday, both myself and my boss (the SVP of Engineering at Alienvault) went to Keep Austin Agile, the annual conference that Agile Austin, the local Austin agile user group network, puts on! I used to run the Agile Austin DevOps SIG till I just ran out of time to do all the community stuff I was doing and had to cut it out.
![]()
It’s super professional for a practitioner conference, and was at the JW Marriott in downtown Austin one day only. It was sold out at 750 people. I figured I’d share my notes in case anyone’s interested. All the presentations are online here and video is coming soon.
My first session was DevOps Archaeology by Lee Fox (@foxinatx), the cloud architect for Infor. The premise is that it’s an unfortunately common task in the industry to have to “go find out how that old thing works,” whether it’s code or systems or, of course, the hybrid of the two. So he has tips and tools to help with that process. Super practical. Several of my engineers at work are working on projects that are exactly this. “Hey that critical old system someone pooped out 3 years ago and then moved on – go figure it out and operationalize it.”
And, some discussion of testing, config management, and so on. Great talk, I will look into some of these tools!
This talk, by Allison Pollard (@allison_pollard) and Barry Forrest (@bforrest30), wasn’t really my cup of tea. It did a basic 4-quadrant personality survey to break us up into 4 categories of Compliance, Dominance, Steadiness, or Influencer. Then we spent most of the time wandering the room in a giant circle doing activities that each took 10 minutes longer than they needed to.
So I’m fine with the 4 quadrant thing – but I got taught a similar thing back when starting my first job at FedEx back in 1993, so it wasn’t exactly late breaking news. (Driver, Analytical, Amiable, and Expressive were the four, IIRC.) As a new person it was illuminating and made me realize you have to think about different personalities’ approaches and not consider other approaches automatically “bad.” So yay for the concept.
But I’m not big on the time consuming agile game thing that is at lots of these conferences. “What might turn you off about a Dominant person? That they can be rude?” Ok, good mini-wisdom, should it take 10 minutes to get it? Maybe it’s just because I’m a Driver, but I get extremely restless in formats like this. A lot of people must like them because agile conferences have them a lot, but they’re not for me.
Next up was Modern Lean Leadership by Mark Spitzer (@mspitzer), an agile coach. I love me some Deming and also am always looking to improve my leadership, so this drew me in this time slot.
First, he quoted Deming’s 14 points for total quality management. For the record (quoted from asq.org:
His talk focused on #7 and #8 – instituting leadership and driving out fear.
Many organizations are fear driven. Even if it’s more subtle than the fear of being fired, the fear of being proven wrong, losing face, etc. is a very real inhibitor. Moving the organization from fear to safety to awesome is the desired trajectory.
He uses “Modern Agile” (Modernagile.org) which I hadn’t heard of before, but its principles are aligned with this:
So how do we create safety? There’s a lot to that, but he presented a quality tool to analyze fear and its sources – who cares and why – to help.
Then the next step is to determine mitigations, and how to measure their success and timebox them. I’m a big fan of timeboxing, it is critical to making deeper improvement without being stuck down the rabbit hole. I tell my engineers all the time when asked “well but how much do I go improve this code/process” to pick a reasonable time box and then do what you can in that window.
OK, but once you have safety, how do you make people awesome? Well, what is awesome about a job? Focus on those things. You can use the usual Lean techniques, like stop-work authority, making progress visible (e.g. days without an incident), using the Toyota kata for continuous improvement, using Plan-Do-Check-Act…
In terms of tangible places to start, he focused on things that disrupt people’s sleep at night, doing retros for fear/safety, and establishing metric indicators as targets for improvement.
Andy McKnight gave this interesting talk – explaining how the Marines build a culture and teamwork, so that we might adapt their approach to our organizations. I do like yelling at people, so I am all in!
Marine boot camp is partially about technical excellence, but also about steeping recruits in their organizational culture. (In business, new hire orientations have been shown to give strong benefits… And mentoring after the fact.)
What is culture? It is the shared values, beliefs, assumptions that govern how people behave.
Most organizations have microcultures at the team level. But how do you make a macroculture? Culture comes first, teambuilding second.
The 11 Marine Corps Leadership Principles:
On the scrum team – those necessary to get the work done
The two Leadership Objectives – mission accomplishment and team welfare, a balance.
Discussion of Commanders Intent and delegating decisions down to the lowest effective level.
Good discussion, loads of takeaways. At my work I would say we are working on developing a macroculture but don’t currently have one, so I’ll be interested to put some of this into practice.
And finally, Agile for Distributed Teams by Paul Brownell (@paulbaustin). At my work we have distributed teams and it’s a challenge. Lots of stuff in the slides, my takeaways are:
All right! 4 of 5 sessions made me happy, which is a good ratio. Check out these talks and more on the Keep Austin Agile 2018 Web site! It’s a large and well run conference; consider attending it even if you’re not an “agile coach”!
Filed under Agile, Conferences, Security
Well, last Thursday and Friday I went to LASCON, our local Austin application security convention! It started back in 2010; here’s the videos from previous years (the 2017 talks were all recorded and should show up there sometime soon. Some years I get a lot out of LASCON and some I don’t, this one was a good one and I took lots and lots of notes! Here they are in mildly-edited format for your edification. Here’s the full schedule, obviously I could only go to a subset of all the great content myself. They pack in about 500 people to the Norris Conference Center in Austin.
The opening keynote was Chris Nickerson, CEO of LARES, on pen testing inspired thoughts. Things I took away from his talk:



Then the first track talk I went to was on Security for DevOps, by Shannon Lietz, DevSecOps Leader at Intuit. She’s a leader in this space and I’ve seen her before at many DevOps conferences.
Interesting items from the talk:
She likes to use the killchain metaphor for intrusion and the MITRE severity definitions.
But convert those into “letter grades” for normal people to understand! Learn development-ese to communicate with devs, don’t make them learn your lingo.
Read the Google Beyondcorp white papers for newfangled security model:
1. zoning and containment
2. Asset management
3. Authentication/authorization
4. Encryption
Vendors please get to one tool per phase, it’s just too much.
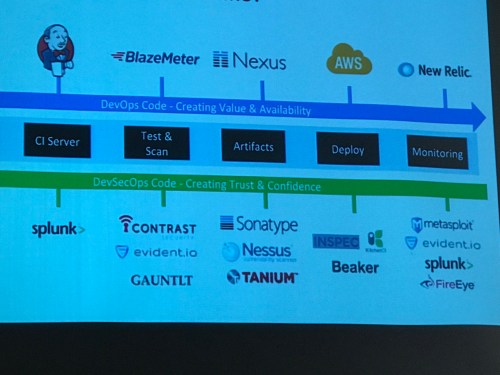
Other things to read up on…
 By Mike McCabe and Brian Henderson of Stratum Security (stratumsecurity.com, github.com/stratumsecurity), this was a great talk that reminded me of Paul Hammond’s seminal Infrastructure for Startups talk from Velocity. So you are getting started and don’t have a lot of spare time or money – what is highest leverage to ensure product security?
By Mike McCabe and Brian Henderson of Stratum Security (stratumsecurity.com, github.com/stratumsecurity), this was a great talk that reminded me of Paul Hammond’s seminal Infrastructure for Startups talk from Velocity. So you are getting started and don’t have a lot of spare time or money – what is highest leverage to ensure product security?
They are building security SaaS products (sold one off already, now making XFIL) and doing security consulting. If we get hacked no one wants our product.
The usual startup challenges – small group of devs, short timelines, new tech, AWS, secrets.
Solutions:

They use AWS, codeship, docker (benefits – dev like in prod, run tools local, test local). JavaScript, golang, no more rust (too bleeding edge). Lack of security tooling for the new stuff.
Need to not slow down CI, so they want tooling that will advise and not block the build. The highest leverage areas are:
Continuous integration – they use codeship pro and docker
Infrastructure is easy to own – many third party items, many services to secure
AWS Tips:
See also Ken Johnson’s AWS Survival Guide
Logging – centralize logs, splunk/aws splunk plugin (send both direct and to Cloudwatch for redundancy), use AWS splunk plugin.
Building the infrastructure – use a curated base image, organize security groups, infra as code, manage secrets (with IAM when you can). Base image using packer. Strip down and then add splunk, cloudwatch, ossec, duo, etc. and public keys. All custom images build off base.
Security groups – consistent naming. Don’t forget to config the default sec group even if you don’t intend to use it.
Wish we had used Terraform or some other infrastructure as code setup.
Managing secrets – don’t put them in plain test in github, docker, ami, s3. Put them into KMS, Lambda, parameter store, vault. They do lambda + KMS + ECS. The Lambda pulls encrypted secrets out of s3, pushes out container tasks to ecs with secrets. See also “The Right Way To Manage Secrets With AWS” from the Segment blog about using the new Parameter Store for that.
Next steps:
Security is hard but doesn’t have to be expensive – use what’s available, start from least privilege, iterate and review!

By fellow Agile Admin, James Wickett of Signal Sciences. Part one is introducing serverless and why it’s good, and then it segues to securing serverless apps halfway in.
Serverless enables functions as a service with less messing with infrastructure.
What is serverless? Adrian Cockroft – “if your PaaS can start instances in 20ms that run for half a second, it’s serverless.” AWS Lambda start time is 343 ms to start and 84 ms on subsequent hits, not quite the 20ms Cockroft touts but eh. Also read https://martinfowler.com/articles/serverless.html and then stop arguing about the name for God’s sake. What’s wrong with you people. [James is too polite to come out and say that last part but I’m not.]
Not good for large local disk space, long running jobs, big IO, super super latency sensitive. Serverless frameworks include serverless, apex, go sparta, kappa. A framework really helps. You get an elastic, fast API running at very low cost. But IAM is complicated.
So how to keep it secure?
And then I was drafted to be in the speed debates! Less said about that the better, but I got some free gin out of it.

By Josh Sokol, Security Spanker for National Instruments! He did a great job at explaining the basics. I didn’t write it all down because as an 3l33t Cloud Guru a lot wasn’t new to me but it was very instructive in reminding me to go back to super basics when talking to people. “Did you know you can use ssh with a public/private key and not just a password?” I had forgotten people don’t know that, but people don’t know that and it’s super important to teach those simple things!


Dr. Kelley Misata was an MBA in marketing and then got cyber stalked. This led to her getting an InfoSec Ph.D from Spaf at Purdue! Was communications director for Tor, now runs the org that manages Suricata.
Her thesis was on the gap of security in nonprofits, esp. violence victims, human trafficking. And in this talk, she shares her findings.
Non-profits are being targeted for same reasons as for-profits as well as ideology, with int’l attackers. They take money and cards and everything like other companies.
63% of nonprofits suffered a data breach in a 2016 self report survey. Enterprises vet the heck out of their suppliers… But hand over data to nonprofits that may not have much infosec at all.
ISO 27000, Cobit 5… normal people don’t understand that crap. NIST guidance is more consumable – “watered down” to the infosec elite but maps back to the more complex guidelines.
She sent out surveys to 500 nonprofits expecting the normal rate of return but got 222 replies back… That’s an extremely high response rate indicating high level of interest.
Nonprofits tend to have folks with fewer tech skills, and they more urgent needs than cyber security like “this person needs a bed tonight.” They also don’t speak techie language – when she sent out a followup a common question was “What does “inventory” mean?”
90% of nonprofits use Facebook and 53% use Twitter. They tend to have old systems. Nonprofit environments are different because what they do is based on trust. They get physical security but don’t know tech.
 They are not sure where to go for help, and don’t have much budget. Many just use PayPal, not a more general secure platform, for funds collection. And many outsource – “If we hand it off to someone it must be secure!”
They are not sure where to go for help, and don’t have much budget. Many just use PayPal, not a more general secure platform, for funds collection. And many outsource – “If we hand it off to someone it must be secure!”
The scary but true message for nonprofits is that it’s not if but when you will have a breach. Have a plan. Cybersecurity insurance passes the buck.
You can’t be effective if you can’t message effectively to your audience. She uses “tinkerer” not hacker for white hats, because you can complain all you want about “hacker not cracker blah blah” but sorry, Hollywood forms people’s views, and normal people don’t want a “hacker” touching their stuff period.
Even PGP encrypting emails, which is very high value for most nonprofits, is ridiculously complicated for norms.
What to do to improve security of nonprofits? Use an assessment tool in an engaging way. Help them prioritize.
She is starting a nonprofit, Sightline Security for this purpose. Check it out! This was a great talk and inspires me to keep working to bring security to everyone not just the elite/rich – we’re not really safe until all the services we use are secure.


By Srini (Srivathsan Srinivasagopalan), a data scientist from my team at AlienVault!
Clustering malware into groups helps you characterize how families of it work, both in general and as they develop over time.
To cluster, you need to know what behavior you want to cluster on, it’s too computationally challenging to tell the computers “You know… group this stuff similarly.”
You make signatures to match samples on that behavior. Analyzed malware (like by cuckoo) generally gives you static and dynamic sections of behavior you can use as inputs. There’s various approaches, which he sums up. If you’re not into math you should probably stop reading here so as to not hurt yourself.
To hash using shingling – concatenate a token sequence and hash them.
Jaccard similarity is computationally challenging.
Min-hashing
Locality sensitive hash based clustering
Hybrid approach: corpus vectorization

Next…Opscode clustering! Not covered here.
TL;DR, there’s a lot of data to be scienced around security data, and it takes time and experimentation to find algorithms that are useful.
 By @mosburn and @nathanwallace
By @mosburn and @nathanwallace
Trying to manage 80 teams and 20k instances in 1 account – eek! Limits even AWS didn’t know about.
They split accounts, went to bakery model. Workload isolation.
They wrote tooling to verify versions across accounts. It sucked.
Ride the rockets – leverage the speed of cloud services.
Change how the team works to scale – teach, don’t do to avoid bottlenecking. App team self serves. Cloud team teaches.
 Policies: Simple rules. Must vs should. Always exceptions.
Policies: Simple rules. Must vs should. Always exceptions.
The option requirement must be value in scope.
Learn by doing. Guardrails – detect and correct.
 Change control boards are evil – use policy not approval.
Change control boards are evil – use policy not approval.
Sharing is the devil.
Abstracting removes value – use tools natively.
He’s created Turbot to do software defined ops – https://turbot.com/features/
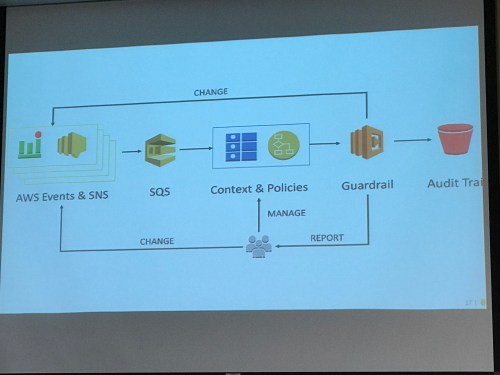
And that was my LASCON 2017! Always a good show, and it’s clear that the DevOps mentality is now the cutting edge in security.
Filed under Conferences, Security
Here’s my LASCON 2016 presentation on Lean Security, explaining how and why to apply Lean Software principles to information security!
James and I have been talking lately about the conjunction of Lean and Security. The InfoSec world is changing rapidly, and just as DevOps has incorporated Lean techniques into the systems world, we feel that security has a lot to gain from doing the same.
We did a 20 minute talk on the subject at RSA, you can check out the slides and/or watch the video:
While we were there we were interviewed by Derek Weeks. Read his blog post with a transcript of the interview, and/or watch the interview video!
Back here in Austin, I did an hour-long extended version of the talk for the local OWASP chapter. Here’s a blog writeup from Kate Brew, and the slides and video:
We’ll be writing more about it here, but we wanted to get a content dump out to those who want it!
If you remember, I (@wickett) said I would be doing more blogging for Signal Sciences in the new year. We still are in January, but I am glad to say that so far so good. Here are a couple highlights from recent posts:
What security experts need to know about DevOps and continuous delivery < This post made it on DevOps Weekly (which of course you should subscribe to) which is awesome! The article takes a few topics and breaks them down for what they mean to InfoSec. Unfortunately to many security people, devops is still Ops 2.0 and is mainly about chef/puppet or that systemic madness called Continuous Delivery. This article attempts to show how security can fit in the new world of devops.
Security Visibility: If You Can’t See ’Em, You Won’t Stop ‘Em! by @txs breaks down the three questions that should keep you up at night if you care about security. This article lays the groundwork of bridging devops and security by focusing on three pragmatic questions. This is a must read.
That’s all for now. Happy Friday everyone!
Filed under Conferences, DevOps, Security
Turns out James (@wickett) is too shy to pimp his own stuff properly here on The Agile Admin, so I’ll do it!
As you may know James is one of the core guys behind the open source tool Gauntlt that helps you add security testing to your CI/CD pipeline. He just gave this presentation yesterday at Austin DevOps, and it was originally a workshop at SXSW Interactive, which is certainly the big leagues. It’s got a huge number of slides, but also has a lab where you can download Docker containers with Gauntlt and test apps installed and learn how to use it.
277 pages, 8 labs – set aside some time! Once you’re done you’re doing thorough security testing using a bunch of tools on every code deploy.
Heartbleed is making headlines and everyone is making a mad dash to patch and rebuild. Good, you should. This is definitely a nightmare scenario but instead of using more superlatives to scare you, I thought it would be good to provide a pragmatic approach to test and detect the issue.
@FiloSottile wrote a tool in Go to check for the Heartbleed vulnerability. It was provided as a website in addition to a tool, but when I tried to use the site, it seemed over capacity. Probably because we are all rushing to find out if our systems are vulnerable. To get around this, you can build the tool locally from source using the install instructions on the repo. You need Go installed and the GOPATH environment variable set.
go get github.com/FiloSottile/Heartbleed
go install github.com/FiloSottile/Heartbleed
Once it is installed, you can easily check to see if your site is vulnerable.
Heartbleed example.com:443
Cool! But, lets do one better and implement this as a gauntlt attack so that we can make sure we don’t have regressions and so that we can automate this a bit further. Gauntlt is a rugged testing framework that I helped create. The main goal for gauntlt is to facilitate security testing early in the development lifecycle. It does so by wrapping security tools with sane defaults and uses Gherkin (Given, When, Then) syntax so it easily understood by dev, security and ops groups.
In the latest version of gauntlt (gauntlt 1.0.9) there is support for Heartbleed–it should be noted that gauntlt doesn’t install tools, so you will still have to follow the steps above if you want the gauntlt attacks to work. Lets check for Heartbleed using gauntlt.
gem install gauntlt
gauntlt --version
You should see 1.0.9. Now lets write a gauntlt attack. Create a text file called heartbleed.attack and add the following contents:
@slow
Feature: Test for the Heartbleed vulnerability
Scenario: Test my website for the Heartbleed vulnerability (see heartbleed.com for more info)
Given "Heartbleed" is installed
And the following profile:
| name | value |
| domain | example.com |
When I launch a "Heartbleed" attack with:
"""
Heartbleed <domain>:443
"""
Then the output should contain "SAFE"
You now have a working gauntlt attack that can be hooked into your CI/CD pipeline that will test for Heartbleed. To see this example attack file on github, go to https://github.com/gauntlt/gauntlt/blob/master/examples/heartbleed/heartbleed.attack.
To run the attack
$ gauntlt ./heartbleed.attack
You should see output like this
$ gauntlt ./examples/heartbleed/heartbleed.attack
Using the default profile...
@slow
Feature: Test for the Heartbleed vulnerability
Scenario: Test my website for the Heartbleed vulnerability (see heartbleed.com for more info) # ./examples/heartbleed/heartbleed.attack:4
Given "Heartbleed" is installed # lib/gauntlt/attack_adapters/heartbleed.rb:4
And the following profile: # lib/gauntlt/attack_adapters/gauntlt.rb:9
| name | value |
| domain | example.com |
When I launch a "Heartbleed" attack with: # lib/gauntlt/attack_adapters/heartbleed.rb:1
"""
Heartbleed <domain>:443
"""
Then the output should contain "SAFE" # aruba-0.5.4/lib/aruba/cucumber.rb:131
1 scenario (1 passed)
4 steps (4 passed)
0m3.223s
Good luck! Let me (@wickett) know if you have any problems.
So you’ve decided to start playing around with Amazon Web Services and are worried about doing so securely. Here’s the basics to do when you set up to ensure you’re on sound footing. In fact, I’m going to use the free tier of all these items for this walkthrough, so feel free and do it yourself if you’ve never taken the plunge into AWS!
Signing up for Amazon Web Services is as simple as going to aws.amazon.com and clicking the “Sign Up” button.
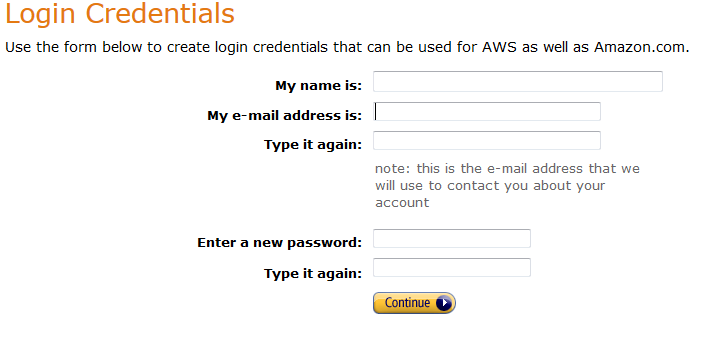
It will want a password – choose a strong one, obviously – and some credit card info for if you exceed the free tier. It’ll want a phone number for a robot to call you – they show you a PIN, the robot calls you, you give the robot the PIN, and you’re good to go.
Next, set up multifactor authentication (MFA) for your Amazon account. You should see an option like this to go directly there immediately post signup, or you can pick the “IAM” section out of the main Amazon console.
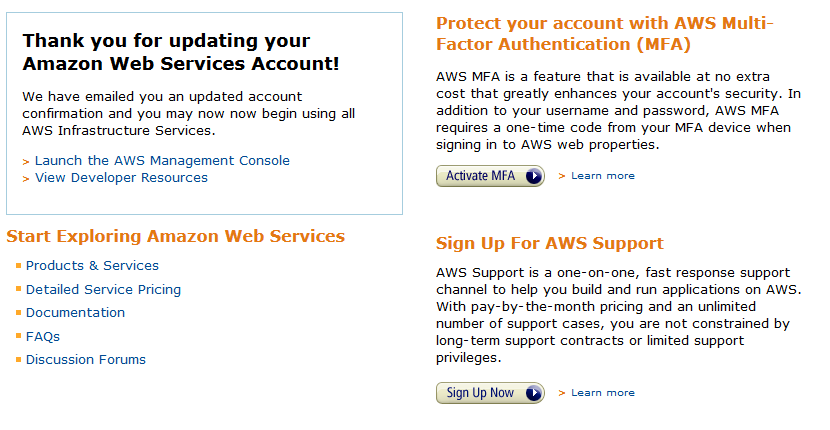
When you go to the IAM console you’ll see two options under Security Status to turn on – Root Account MFA and Password Policy. I won’t talk much about the password policy except to say “go turn it on and check all the boxes to ensure strong passwords.” To turn on MFA, you need some kind of MFA device. The Amazon docs to walk you through the process are here. Unless you have a Gemalto hardware token already your best best is to just download Google Authenticator (GA) onto your iPhone/Android from the relevant app store (other choices here).
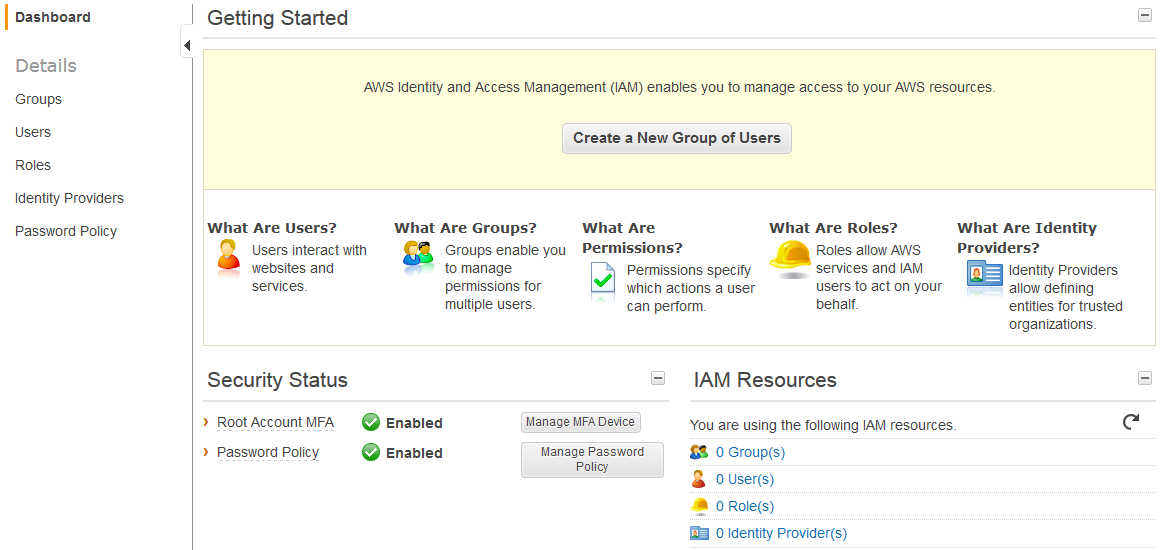
Once you’ve installed Google Authenticator, click on “Manage MFA Device” and choose virtual; it’ll show you a QR code that GA can scan to do the setup. Then you enter two tokens in a row from GA and it’s hooked up to the account. Now, to log into the console you need both your password and a MFA token. (You can also use GA for Dropbox, Evernote, Gmail, WordPress, etc. and is a good safeguard against the inevitable password losses these companies sometimes have.) Of course once you do this you need to be careful – if you lose the phone or device you can’t get in!
Now make sure and save all your credentials in a password vault. I prefer Keepass Password Safe along with MiniKeePass on the iPhone. Besides the password, you should go to your Security Credentials (off a popdown form your name in the top right) and store your AWS Account ID, Canonical User ID (used for S3), and any access keys or X.509 certificates you make – but it’s better not to make these for the main account, just for IAM accounts. Proceed onward to hear more about that!
All right – now your main login is secure. But you want to take another step past this, which is setting up an Identity and Access Management (IAM) account. IAM used to be a lot less robustly supported in AWS but they’ve gotten it to be pretty pervasive across all their services now. Here’s the grid of what services support IAM and how. You can think of this as the cloud analogy to UNIX’s “secure your root account, but still you shouldn’t log in as it but as a more restricted user.”
First, you have to set up a group. On the IAM dashboard click on the big ol’ “Create A New Group Of Users” button in the yellow box at the top.
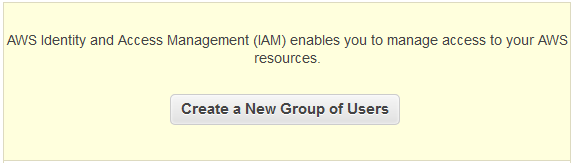
Then make a group, call it “Admins” for the sake of argument.
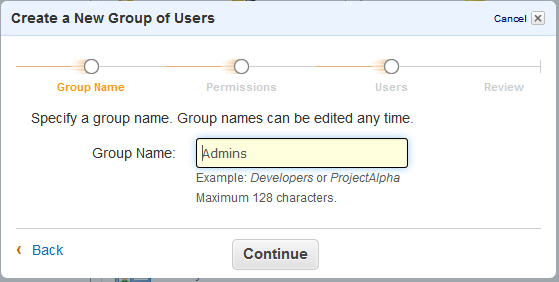
Choose the “Administrator Access” policy template. If you know what you’re doing, you can change this up extensively.
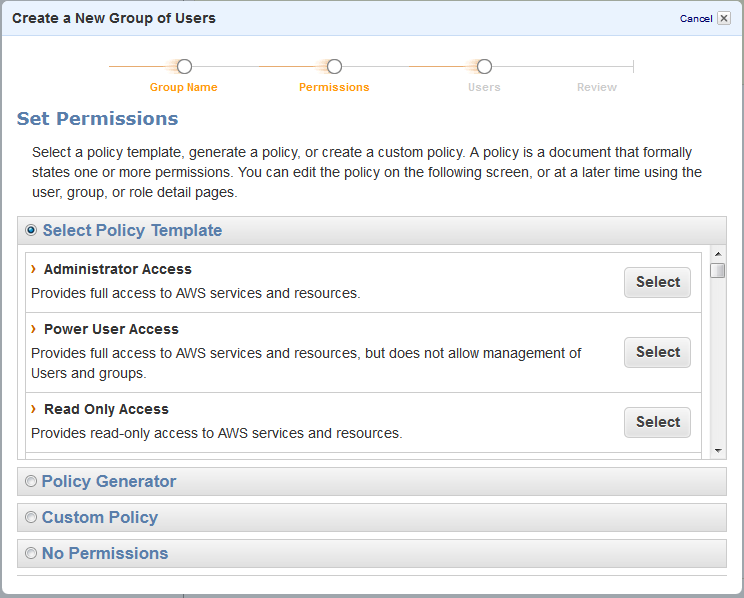
Add a username for yourself (and whatever other people or entities you want to have full admin access, ideally not a long list) to the group.
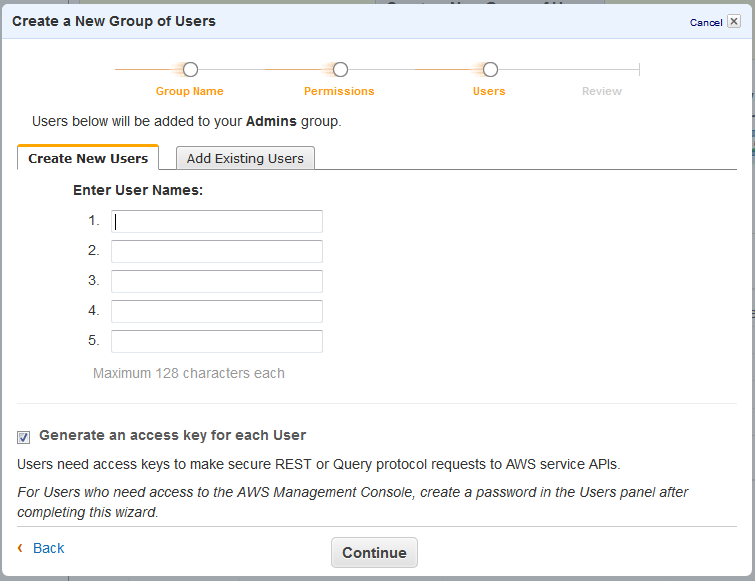
For each user it’ll give an Access Key ID and Secret Access Key – these are the private credentials for that user, they should take them and put them in whatever password vault they use.
If you want to use that account to log into the console – and for this first one, you probably do – then once this is complete you go into Users, select the user, and under Sign-In Credentials it will say Password: No. Click Manage Password and set a password for that user; they can then log into the custom IAM login URL shown on the front page of the IAM dashboard (it’ll put it in the file when you Download Credentials, too).
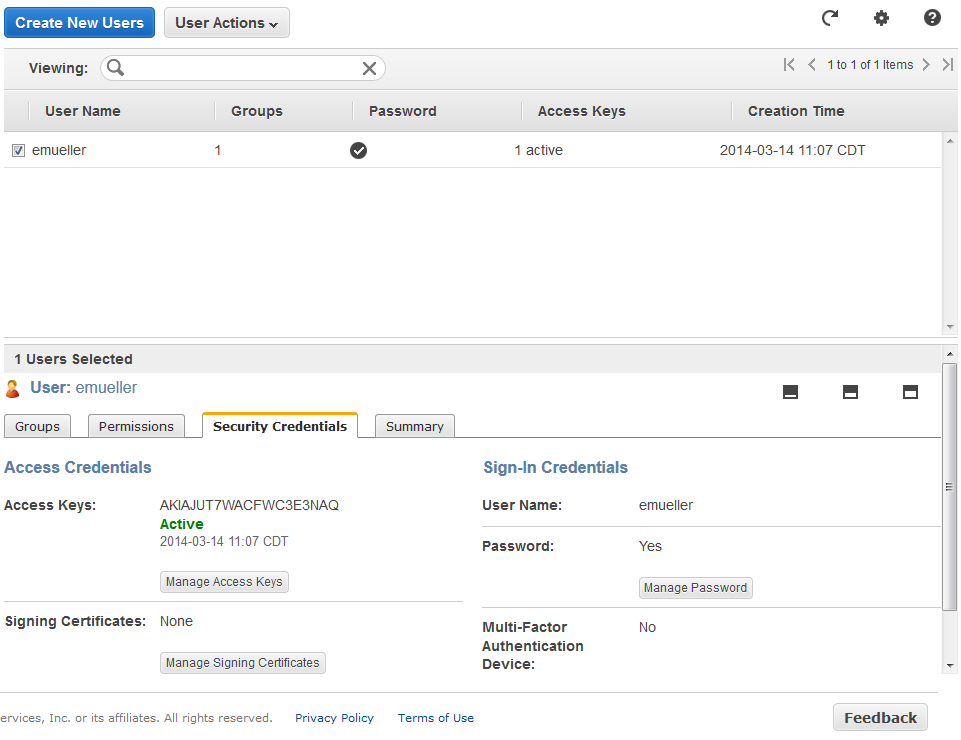
Just as with the main user, you can (and should) also set up MFA on IAM users. It’s the same process as with the main account so I won’t belabor it.
After you set up your IAM user and its MFA, you shouldn’t log in using your main AWS account credentials to do work – only if you need the enhanced access to mess with account credentials. Log out and then back in with your IAM account to proceed. If you want to take it a step farther and make an even less privileged account without admin rights, which you can use for everyday tasks like logging in and looking at state or just starting/stopping instances but not manipulating more sensitive functions, you can do that too.
Of course if you are looking to manage multiple people, or separate apps that have access to your account (many SaaS solutions that integrate with your Amazon account will ask for IAM credentials with specific access), you can set up more groups with less access and have those entities use those. In general I’d suggest using a group+user and not just a user (different SaaS monitoring services recommend different approaches, but I think a plain user is less flexible). You can also get fancy with roles (used for app access from your instances) and identity providers. Remember the principle of least privilege – give things only as much access as they need, so that if those credentials are compromised there’s a limit to what they can do. There’s an AWS IAM best practices guide with more tips.
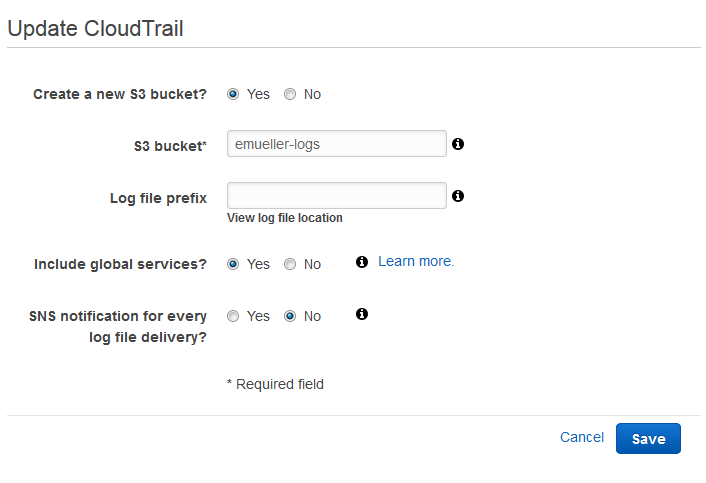
Security folks know that nothing’s complete without the ability to audit it. Well, you can turn on logging of AWS security events using CloudTrail, the AWS logging service. This will basically dump IAM (and other Amazon API events) to a JSON file in S3. This is a whole can of whupass unto itself, but the short form is to follow this guide to set up your trail, making sure to say Yes to “Include global services?”.
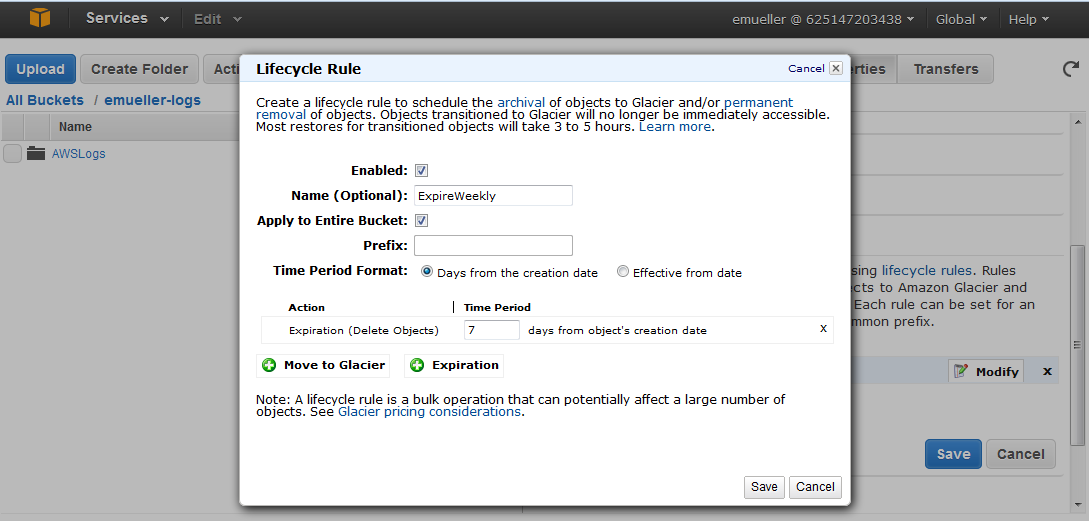
You can also go into S3 and set your bucket (properties.. lifecycle) to expire (archive, delete, etc.) the logs after a certain time.
Then you can do something like set up SumoLogic to watch it and review/alert on your logs. If you want to try that, the short HOWTO is:
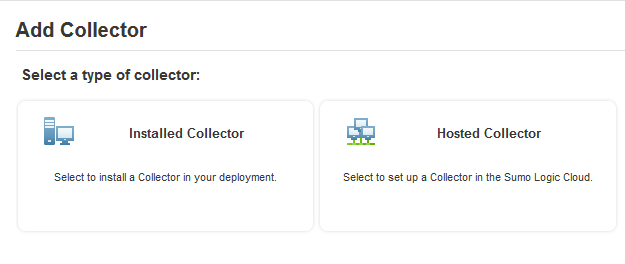
* | json “userIdentity.userName”, “eventTime”, “eventName” as username, time, action | sort by time
They also have an app specific to CloudTrail; you have to contact Sumo support to get it turned on though.
All of this, of course, is about access at the Amazon account and API level. For your actual instances, you’ll want to set up secure network access and then manage the SSH keys you use to log into them.
VPCs used to be a limited option, and mostly people just used security groups. Nowadays, VPCs are standard and an expected part of your setup. They’re like a private virtual network. When you create your account, it’ll actually create one default one for you automatically. You can see it by going to the VPC Console. This default VPC, though, is set up for convenience and back compatibility – instances you launch into it will get a public IP address, which may not be what you want, and the default security group allows all outbound traffic and all traffic from within the security group.
You should consider starting one instance this way and then using it as a bastion host to gateway into your other instances, which shouldn’t have public IPs unless you really want them to be publicly facing. It’s hard to prescribe other specifics here because it really depends on what you plan to do. At a bare minimum you need to add an inbound SSH rule from your location to the security group so you can log into your first instance when you start it below. (They have a neat new “My IP” choice that’ll detect where you’re coming from. Of course that won’t work when you drive to the Starbucks…) Consider removing the rule allowing all traffic from within a security group – even within a group it’s more secure to allow specific protocols instead of “everything from everywhere.”
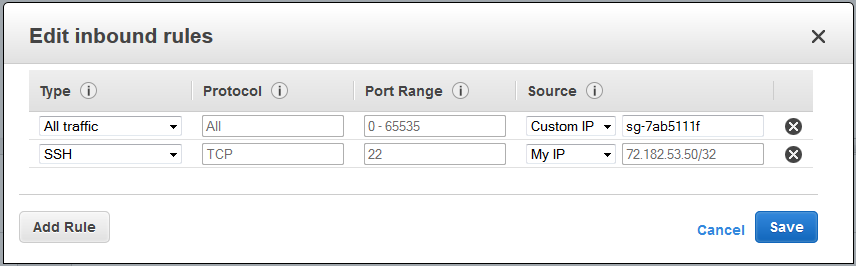
Ideally, you’d set up a VPN to the VPC’s Internet Gateway – but this requires expensive hardware or setting up your own server and is way out of scope here.
Then, of course, you finally get to starting instances! Each instance will start with a default root ssh key. Things you want to do here are:
The final step to doing all this securely is to not be making manual changes. Via the CLI or API you can automate a lot of this, but even better is using CloudFormation, maybe in conjunction with OpsWorks or another CM tool, to define in a readable config how you want your system to behave (VPCs, security groups, etc.) and instantiate off that. Nothing’s more auditable than a system that’s built automatically from a spec! You can cheat a little and set up your VPCs and all the way you want and use their CloudFormer tool to generate a CloudFormation template from your running system. Then you can edit that and tear down/restart from scratch.
The more you automate, the tighter you can make the security controls without inconveniencing yourself. A trivial example is you could have a script that uses the CLI to change the security group to allow SSH from wherever you are right now, and then close it afterwards – so there’s no SSH access from a location unless you allow it! In the same vein, allowing “all access” within a security group or from one group to another is usually done out of laziness and flexibility for manual changes – if you automate such that if you add a new set of servers, they also configure their connectivity needs specifically, you’re more secure. For defense in depth you could automatically configure the onboard firewalls on the boxes to mimic the security groups, just read the security group settings and transform into similar iptables (or whatever) settings. Voila, a HIPS. Pump those logs into Sumo too.
You could add tripwire or OSSEC for change detection, but also if you run your servers from trusted images and recreate them frequently, you can very much reduce the risk of compromise.
That’s my quick HOWTO on how to get servers running in a mode that’s likely way more secure than the average enterprise server unless you work for a bank or something, inside a couple hours. MFA, key based auth, all the network separation you could want, separation of privileges…
