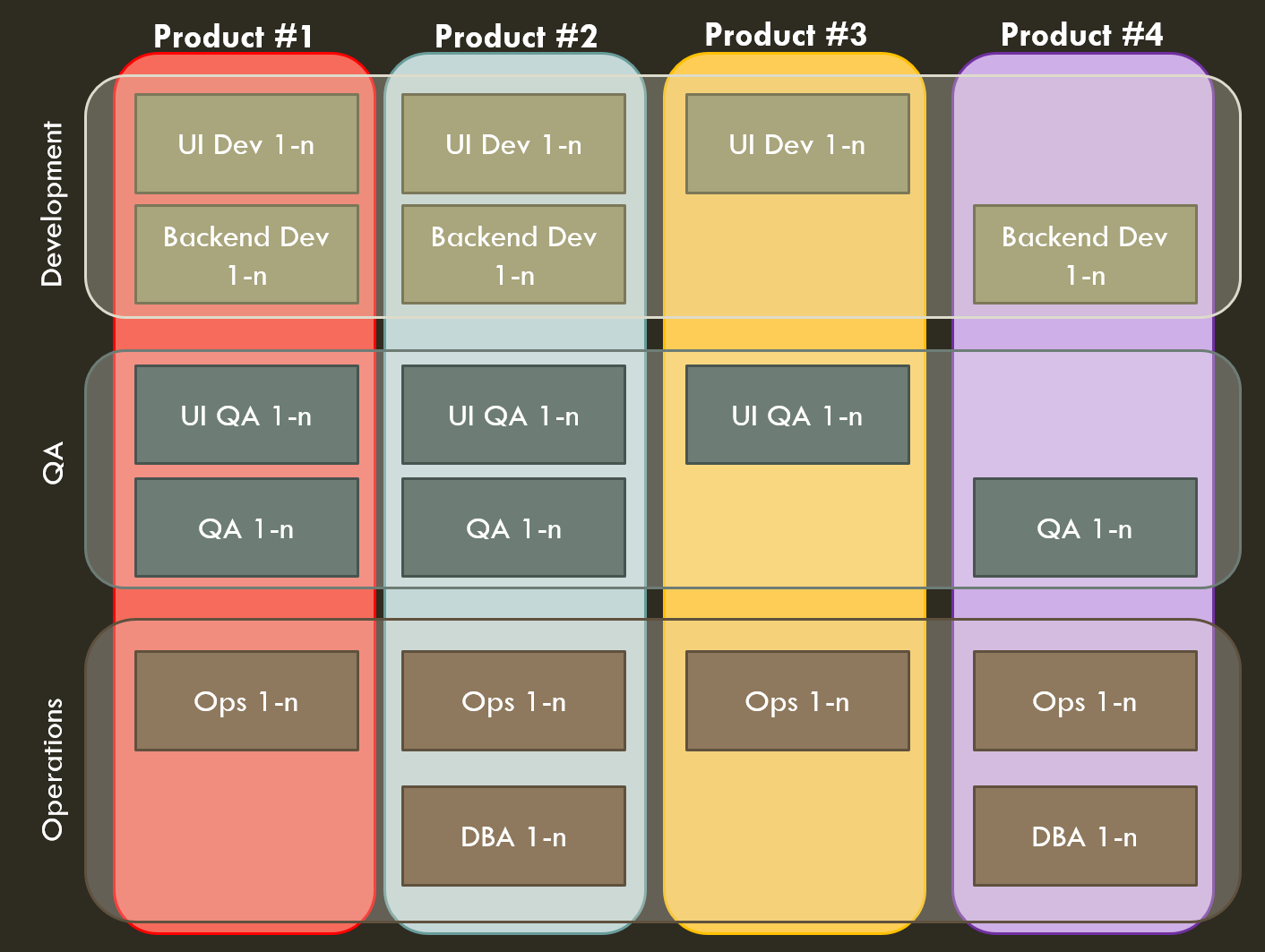
OK, so it’s been a while since the last installment in this series. I had talked about how we’d brought Scrum to our operations team, which worked fine, and then added in the developers as well, which didn’t. Our first attempt at dividing the whole product up into four integrated DevOps service teams collapsed quickly. Here’s how we got past that to do it again and succeed, with a fully integrated DevOps setup managing both proactive/project/feature work and reactive/support/tactical work in an effective way.
The first challenge we had was just that I couldn’t manage four new scrum teams totally on my own. We had gotten the ops team working well on Scrum but the development team hadn’t been. We didn’t have any scrum masters other than me, and were low on people designated as tech leads as well. So step one, we just mushed everyone into a 30+-person Scrum team, which sucked but was the least of the evils, and I immediately worked on mentoring people up as both Scrum masters and tech leads. I basically led by example and asked for volunteers for who was interested in Scrum mastering and/or being a tech lead for each of the planned sub-teams.
This was interesting – people self-selected in ways I would not have predicted. Some of the willing were employees and others were contractors – fine, as far as I’m concerned. “From each according to his ability, to each according to his need.” I then maximally had them start to lead standups and take ownership over sprints and such, coaching them in the background. In that way, it only took a little while to re-form up into those four teams. This gave some organic burn-in time as well, so that the ops folks got more used to not being “the ops team” and leaning on people that were supposed to be on other sprint teams. As I empowered the new leaders this became self-correcting (“Stop working with that other guy on their stuff, we have things that need doing for our service!”).
The second and largest problem was managing the work.
Part 1: “Planned” Work
Product Management
We had practically zero product manager support at the beginning, so it was up to us to try to balance planned work from many sectors – feature requests from PM, tooling requests from Customer Service and Technical Support, security stuff from Security, random requests from Legal and Compliance, brainwaves from other products’ engineering managers. It quickly began to take a full person worth of time to handle, because if not managed proactively it turned into attending meetings with people complaining as a reactive result. I went to the PM team and said “come on man, give us more PM support,” and once we got one, I worked with her on being able to manage the whole overall package.
One of the chronic product manager problems in a SaaS environment is the “not my domain” syndrome. PMs want to talk about features, but when it comes to balancing stakeholders like Security and internal operational projects, they wash their hands of it. At best you get a “Well… You guys get 50% of your time to figure out what to do with that stuff and then 50% of your bandwidth will be my features, OK?”
For the record, that’s not OK. As a product manager, you need to be able to balance all the work against all the work. Maybe you don’t have an ops background, that’s fine – you probably didn’t have a <business domain here> background when you came to work either. Learn. A lot of the success of a SaaS product is in the balancing of features against stability/scalability work against compliance work… If you want to take the “I’m the CEO of the product” role, then you need to step up and own all of it, otherwise you’re just that product’s Director of Wishful Thinking.
Anyway, luckily our PM, even though she didn’t have experience doing that, was willing to learn and take it on. So we could reason about spending a month putting in a new cluster versus adding a new display feature – they all went into the same roadmap.
Work Management in JIRA
We managed that in the standard, simple way of a quarterly spreadsheet roadmap correlating to epics in an Agile rapid board in JIRA; we’d do stakeholder meetings and stack rank them and then move them into the team backlogs and flesh them out when they were ready for execution. (It was important to keep the clutter out of the backlogs till then – even if it’s supposed to be future stuff, the more items sitting in a team’s backlog, the worse their focus is.)
We kept each service as one JIRA project but combined them into rapid boards as necessary – a given team might own a couple (like the “Workbench and CMS Team” had those two and a smaller tooling one). This way when we transferred a piece of tech around we could just move the JIRA project as well, and incorporate it into the target team’s rapid board.
Portfolio Management
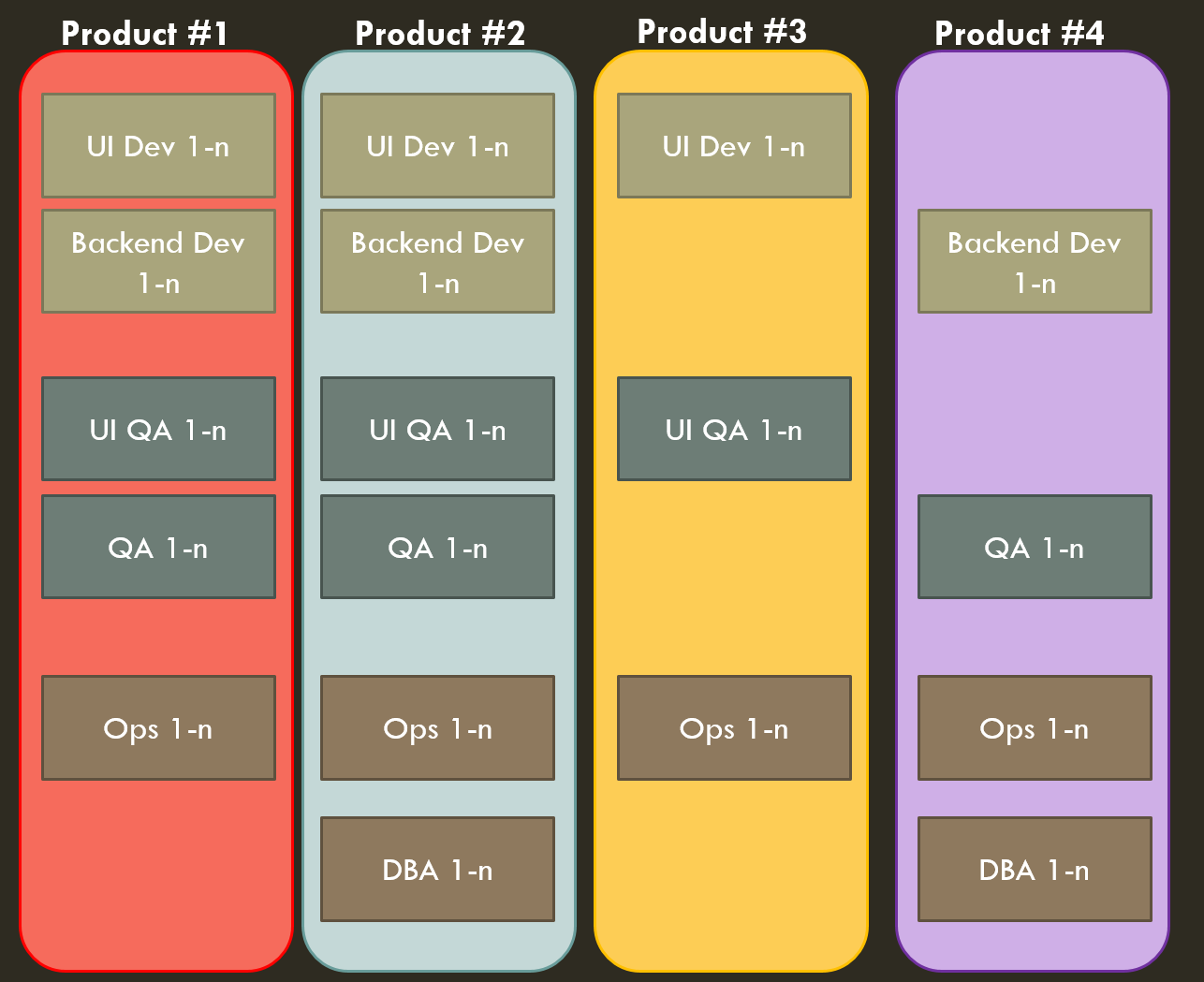
Some people say that the ideal world is each team owning one microservice. I don’t agree with this – we had a number of teams under other parts of the org that were only like 2 people because they owned some little service. This was difficult to sustain and transition; when things like Black Friday came up that required 24×7 support from each team for a week it was brutal on them, and even worse once development eased up on a service it just got orphaned.
If you don’t keep a service portfolio and tightly manage who is tasked with supporting each one, you are opening yourself up to a world of hurt. And that’s where we started. Departmentwide, we’d have teams work on something and then wander off and if there was a problem they’d call on the dev who was somewhere working on some other deadline now. This worked terribly. I got the brunt of this earlier when I had joined the company as a release manager and asked “So, those core services, who owns those?” “Well… No one. I mean everyone!”
So for my teams, we put together a tracking list, used both as a service registry but also for cross-training. It was a simple three-level outline, with major services, service components, and low level elements. We had the whole team work together on filling out the list – since we were managing a 7-year-old legacy system we ended up with a list of 275 or so leaf items. Every one had to have an owning team (team, not individual), and unless you retired a service, there was no dropping it on the floor. You owned it, you retired or transitioned it, and I didn’t care if “the dev that worked on that moved to some other team.” Everything was included, from end user facing services like “the user portal” to internal services like our CI servers.
Team Management
This transitions into how we managed the teams. Teams were standard “two-pizza size” – a team of 5-7 people is optimal and we would combine services up till there was enough work for a team of that size. This avoided the poor coverage of mini-teams for micro-services.
Knowledge Management
Then we also used the service registry as the “merit badge system.” We had a simple qualification procedure – to get qualified in an element, you had to roll out code on it and you could sign off for yourself to say that you were qualified on one of those leaf elements. To get your “merit badge” in a service component, you needed an existing subject matter expert (SME) to sign off that you knew what you were doing, and you needed to understand how the service was written, deployed, tested, monitored. To become a SME in a service, the existing SMEs would have a board of review. SMEs were then understood to be qualified to make architectural changes on their own initiative, those with merit badges were understood to be qualified to make code changes with nothing more than the usual code review and CI testing.
This was very important for us because we were starting in a place where people had been allowed to specialize too much. Only one person was the SME on any given service and if the person who didn’t understand the Workbench was out, or quit, or whatever, suddenly no one knew a whole lot about it. That’s a terrible velocity burden even without attrition and it’s a clear and present danger to your service’s viability when there is. We started tracking the “merit badges” and had engineers set goals around how many they’d earn (or how many they’d review, for the more experienced). We used a lot of contract programmers and I told the contractor manager that I wanted to use that to rate the expertise of people on our account and that I wanted to see the numbers rise on each person over time.
Part 2 – “Unplanned” Work
Our team was only doing planned work 40% of the time, however. Since we were integrated DevOps teams working on a service with thousands of paying end customers, and that service was custom-integrated with customer Web sites and import/export of customer data, there was a continuous load of work coming in from Customer Support and from our own operations (alerts, etc.). All this “flow” work was interrupt-driven, and urgent to one degree or another.
The usual techniques for handling this have a lot of problems. “Let’s make a separate sustaining team!” Well, this turns into a set of second class developers. Thus you get worse devs there on that team. And those devs are more utilized one week, less the next; when things are quiet they get seconded to other efforts by people that haven’t read the Principles of Product Development Flow and think having everyone highly utilized is valuable, and then the load ramps up and something gives… Plans emerge to make it a training ground for new devs, till you realize that even new devs don’t want to put up with that and just quit… I’ve seen this happen in several places. I am a firm believer in dog fooding – if you are writing a service, you need to handle its problems. If there are a lot of problems, fix it!!! If you are writing the next version of the service – well, doing that in isolation from the previous service dooms you to making the same errors, adding in some new ones as well. No sustaining teams, only evergreen teams.
So we had the rule that each integrated team of devs and ops handled their own dirty laundry. And at 60% of the workload, that was a lot of laundry. How did we do it? Everyone was worried about how we could deliver decent feature velocity while overwhelmed by flow work. Therefore…
Triage
In addition to the teams’ daily standups, we had a daily triage meeting where the engineering manager, team leads, PM, and representatives from Support, Sales, and whoever had a crisis item that they felt needed to be handled on an expedited basis (not waiting on the next sprint, in other words) would come to. Each new intake would be reviewed. In the beginning we had to kick a lot of requests back for insufficient detail, but that corrected itself fast. We’d all agree on priority – “that’s affecting one customer but they’re one of our top customers, we’ll work it as P2” or the like.
For customer reported issues, we had SLAs we committed to in contracts (1 day for P1, etc). Ops issues could be super urgent – “P1, one of our services is down!” – or doable later on. So what we did was to create a separate Kanban board in JIRA for all these kinds of issues. Anything that really could wait or was large/long term would get migrated into the Scrum backlogs, but anything where “we need someone to do this stat” went in here. It served the same purpose as an “expedite lane,” it was just a jumbo four-lane highway of an expedite lane because so much of the work was interrupt driven.
But does this mean “give up on Scrum?” No. Without the sprint cadence it was hard to hit a release cadence, and also it was easy for engineers to just get lost in the soup and stop delivering at a good rate, frankly. So we still ran sprints, and here was the rules of engagement we provided the engineers.
Need More Work?
- Pull things for your team/service off the triage queue
- If there’s nothing in the triage queue, pull the next item from the sprint backlog
- If there’s nothing in the sprint backlog or the triage queue, pull something off the top of the backlog. Or relax, either one.
Then for standups, we had a master Agile board that contained everything – all projects, the triage board, everything. So when you looked at a given engineer’s swimlane, you could see the sprint work they had, the flow work they had, and anything they were working on from someone else’s project (“Hey, why are you doing that?”). Again, via JIRA agile board composition that’s easy to do. Sometimes teams would try to do standups just looking at swimlanes containing “their” projects and it always ended up with things falling in the gap, so each time that happened I reiterated the value of seeing everything that person is assigned, not just what you think/hope they are assigned, since they are exclusively attached to that one team.
At first, everyone fretted about the conflict between the flow work and the sprint work. “What if there’s a lot of support work today?!?” But as we went on sprint by sprint, it became evident that over the course of a two week sprint, the amount of support and operations work evened out. Sprint velocity was regular despite the team working flow work as well. Having full-sized sprint teams and two-week iterations meant that even if one day there was a big production issue and whoever grabbed it was slammed – over the rest of the time and people it evened out. This shouldn’t be too surprising, it’s called “flow” for a reason – there are small ebbs and surges but in general the amount over time at scale is the same. Was it as perfectly “efficient” as having some people working flow and others working sprints? No, there is definitely a % overhead that incurs. But maximum utilization of each person’s time, as I mentioned before, is a golden calf. Lean principles show us that we want the best overall outcome – and this worked.
Flow work was addressed quickly, and our customer ticket SLA attainment percentage whipped up from a starting level of less than 50% over several quarters to sit at 100%, meaning every single support ticket that came in was addressed within its advertised SLA. Once that number hit 100% the support ticket time to live started to fall as well.
At the same time, sprint velocity for each of the four sprint teams went up over time – that is, just the story points they were delivering out of the feature backlog improved, in addition to the improvements in flow work. We’d modify the process based on engineer feedback and try alterations for a sprint to see how they panned out, but in general by keeping the overall frame in place long enough that people got used to it, they became more and more productive. Flow work and planned work both improved at the same time, not at each others’ expense.
The Dynamic Duo
This scheme had two issues. One was that engineers were sometimes confused about what they should be working on, flow tickets with SLAs or their sprint tasks. Our Scrum masters were engineers on the teams too, they weren’t full time PMs that could afford to be manually managing everyone’s work. The second was that operational issues that came in and required sub-day response time couldn’t wait for triage and ended up with either frantic searches for anyone who could help (which often became “everyone sitting in the team area”) or missed items.
I have always been inspired by Tom Limoncelli’s Time Management for System Administrators. He advocates an “interrupt shield” where someone is designated as the person to handle walkups and crises. At NI I had instituted this in process, at BV in the previous Ops team there had been a “The Dude” role (complete with Jeff Bridges bobblehead) that had been that. Thus the Dynamic Duo were born.
The teams each had one dev and one DevOps on call at a given time; we managed the schedule in PagerDuty. Whoever was on call that week became “on the Dynamic Duo” during the days as well. When we went into a sprint, they would not pull sprint tasks and would be dedicated to operational and urgent support issues. It was the Dynamic Duo because we needed someone with ops and someone with dev expertise on this – one without the other meant problems were not effectively solved. I even made a cool wiki page with Batman and Robin stuff all over it and we got Bat-phones painted red. I evangelized this inside the company. “Don’t walk up and grab a dev with your question. Don’t chat your favorite engineer to get them to work on something. Come turn on the Bat-signal, or call the Bat-phone, and the Dynamic Duo will come help you.”
This was good because it blunted the sharp tip of very urgent requests. The remaining flow work (2 people couldn’t handle the 60% of the load that was interrupt driven) was easier for the sprinting devs to pull in as they finished sprint tasks without worrying about timeliness – the real crises were handled by the Dynamic Duo. The Duo also ran the triage meeting and even if they weren’t working on all the triage work, they bird dogged it as a kind of scrum/kanban/project manager over the flow work. In the rare case there wasn’t anything for them to jump on, they could slack – time to read, learn, etc. both as compensation for the oncall and adrenaline rushes that week but also because it’s hard to fit time for that into sprints… And as we know from the Principles of Product Development Flow, running teams at too high of a utilization is actually counterproductive.
Conclusion
That’s the short form of how we did it – I wanted to do a lot more but I realized that since it’s been a year since I intended to write this, I’d better shake and bake and get it out and then I’m happy to follow up with stuff any of you are curious about!
This got us to a pretty happy place. As time went on we tweaked the sprint process, the triage process, and the oncall/Duo process but for a set of teams of our size with our kind of workload it was close to an optimal solution. With largely the same team on the same product, the results of these process changes were:
- Flow work improved as measured by customer ticket SLA attainment and other metrics
- Sprint work velocity improved as measured by JIRA reports
- Engineering satisfaction improved as measured by internal NPS surveys
Improvement of all these factors was not slight, but was instead 50% or more in all cases.
Feel free and ask me about parts of this you find interesting and I’ll try to expand on them. It wasn’t as simple as “add Agile” or “add DevOps,” it definitely took some custom wrangling to balance our specific SaaS service’s needs in the best manner.