
How I use AI as a sounding board for home organization, while keeping every decision mine.
I work in internal developer relations at Google, which means I spend most of my time thinking about how engineers adopt AI tools. Prompting, delegation, workflow integration. It’s the job. So it was probably inevitable that I’d eventually turn that lens on my own garage.
My tool shed had gotten out of hand. Rakes leaning in a pile, a Greenworks mower blocking everything, an orange leaf blower that lives on a shelf for no particular reason, clear bins I can’t see into, Amazon boxes I kept meaning to break down. The usual. I knew what needed to happen, I just didn’t want to think through it.
So I tried something. Here’s what the process looked like.
Stage 1: The visual brain dump. I took a few pictures of the shed from different angles and dropped them straight into a chat with the Gemini app. No cleanup, no staging. The whole point is to let the AI actually see what you’re dealing with. It inventoried the space better than I could have described it in words: spotted the tool categories, flagged the wasted vertical space, noticed the empty wire shelving unit sitting in the foreground. That last one was a little embarrassing, since that was the thing I had bought to fix the problem and then just put in the shed. It made a few mistakes too (“I see grill equipment” when there is no grill equipment), but you can correct those. That’s fine.
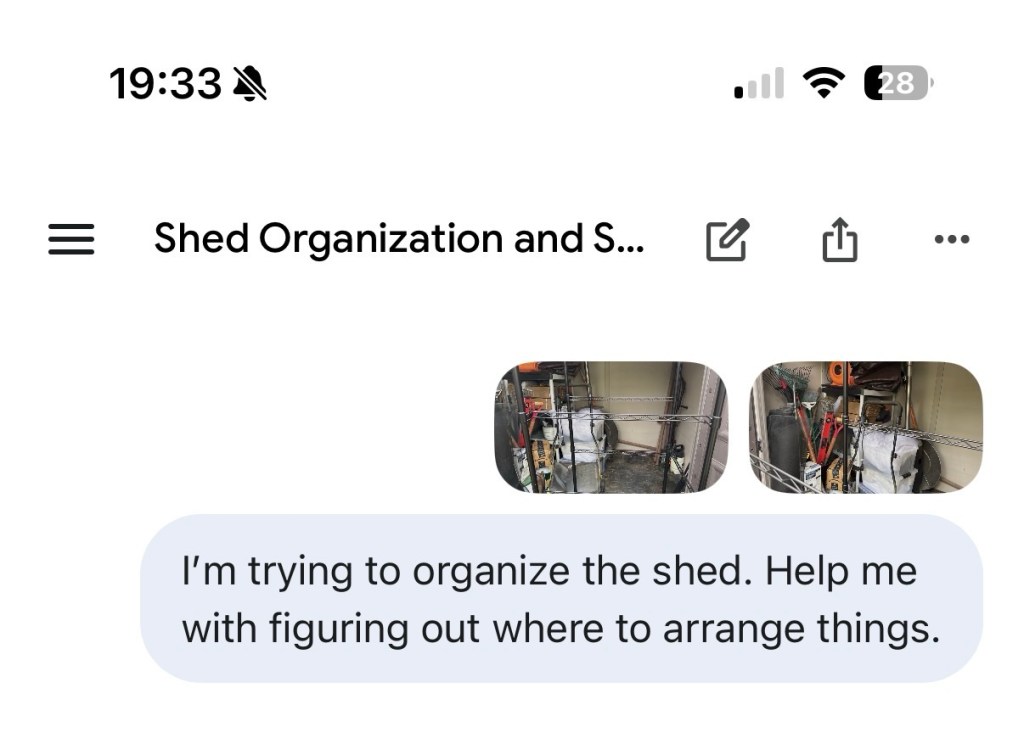
Stage 2: Adding constraints. My first prompt was basically nothing: “I’m trying to organize the shed. Help me figure out where to put things.” The response was reasonable: wall-mounted racks, hooks for the long-handled tools, zone everything by frequency of use. Also useless, because it’s a plastic vinyl shed and you can’t mount anything to the walls.
So I said: “I can’t hang anything.” One constraint. The whole response shifted. Suddenly we were talking about freestanding tool corrals, using 5-gallon buckets to hold rakes upright, putting the mower at the back as an anchor and working forward from there. Things I could actually do.
The difference between the first response and the second taught me something I keep relearning at work too. Telling the AI what you cannot do gets you further than telling it what you want. Open-ended questions produce options. Constraints produce a plan.
Stage 3: Iterative refinement. I kept going. What’s the single first move? What goes on the floor versus the shelf? If I only had 20 minutes, where do I start? Each answer gave me something to react to, agree with, push back on. I wasn’t taking orders. I was pressure-testing ideas faster than I could generate them on my own.

That’s the distinction I’d draw for anyone trying this at home: the AI isn’t making decisions. You are. It’s doing the legwork of mapping out the options so you spend less time staring at a cluttered shed wondering where to begin. The judgment is still yours. You’re just not doing the combinatorics by hand.
One more thing worth knowing: you don’t have to type. I did most of this by talking into my phone while standing in the shed looking at the actual problem. It kept me in the space instead of retreating to a screen. The model doesn’t care how it gets the input.
The shed isn’t finished. But I know exactly what the next step is, which is more than I could say before I started.
If you want to try this: start with a photo, not a description. Then as soon as the first answer doesn’t fit your situation, say why. That’s where the useful conversation begins.


