
Check out agile admin James Wickett’s talk from DeliveryConf last month on adding security into your continuous software delivery pipeline!
Check out agile admin James Wickett’s talk from DeliveryConf last month on adding security into your continuous software delivery pipeline!
Filed under Conferences, DevOps, Security
Recently I reported, and I quote, “Bah!” from trying a bunch of record and playback cross browser testing options. To recap, we’re a startup, our devs are writing UI tests but we don’t have cross-browser testing, so I tried to find something where I could record and replay our pretty simple Angular UI flow and get some cross-browser testing on it without needing code. And I didn’t find anything that worked. But I got a bit more traction after that first run at it, so here’s part 2.
The EndTest support folks looked into it and fixed my test so it worked. Some were alternate locator schemes. Some were advanced options I am not sure how I would have figured out (to close those pesky multiselect dropdowns, you can’t just click on the overlay backdrop that comes up, you have to offset by some pixels…). I am not a front end guy, I just fake it, so this is a little daunting, but their support seems able to help with tests so it’s doable.
I now have a working test, somewhat generated from the recording and somewhat generated by programming. The trial doesn’t allow other browsers by default but they turned them on for me. With some light fiddling I got them all running, and the only issue was IE not running because it didn’t like that pixel-offset workaround from the above and EndTest fixed it by changing my test to hit “enter” instead – fair enough.
I then also made a test for the second part of our flow that has a PDF that needs validation, you can do it with a screenshot comparison.
So after help from their support, I have a working test suite – it’s a stretch to say it’s pure record and replay; it’s record, edit the locators a bunch, and replay, but since my last iteration on this was “none of these solutions work and do crossbrowser”, that’s a big win.
Last time I had been trying to use the Selenium IDE for record/replay and integrate with Sauce for the crossbrowser testing. They got back to me and extended my trial minutes and gave me some tips on how to get some of the tests working. They don’t support the Selenium IDE however so they don’t really help with the tests per se.
I had a weird experience, there were intermittent (but frequent) timeouts from running tests against Sauce with selenium-side-runner, just at some point 0-4 minutes into the test it’d hang and time out and give me a “ETIMEDOUT connect ETIMEDOUT 66.85.49.22:443″.
And then I got into the lovely rich set of test things that don’t work the same across the browsers. Oh, in Edge “the element isn’t clickable because it’s obscured.” In Firefox on Mac “that radio button isn’t clickable because the inner part of the radio button obscures it.” All different elements. The problem is, fiddling with the locators to get something that browser likes breaks it in the other browsers. But the app works in those browsers, just not the tests.
Anyway, Sauce support said “we can’t support Selenium IDE questions” so I guess that’s it. (I don’t know that those timeouts when running tests on their service count as selenium IDE questions but whatever). I had hope when I found Selenium IDE that a record and replay with Sauce was feasible but it seems like it’s a starting point to seed your own Selenium code at best.
A sales rep from mabl wouldn’t let go of me till I tried their solution. So I did and it has a lot of promise. It tries a bunch of different methods to find a locator automatically and self-heals the tests, which is great. On the one hand the tests are slow; a 4 minute selenium test is a 6-8 minute mabl test. On the other hand it works!
It worked the first time in fact (Well… second, but it was because I went into a click frenzy trying to get the mabl trainer window and our Hubspot popup out of my way). I now have a working mabl test, though it is having one-minute timeouts and confusion on that same “click on the backdrop to get out of the multiselect dropdown” issue that’s a pain in all the other solutions as well, it does it but after a long timeout and it doesn’t self heal it for the next test run so it works but is slow. I hate multiselect dropdowns. Anyway, after a discussion with mabl support it turns out that it tries a bunch of ways to find a locator and then self heals if it found a better one, and then tries a bunch of ways to click/exercise that locator but doesn’t self heal from that hence the long timeout in my test. I gave them the feedback “self heal that too, yo!”
OK so it’s working, how about cross-browser? I add Firefox – it works. IE and Edge are only on the “enterprise plan” but I ask them to add them to the trial, they do, I run them, and… They work! Safari… Well, a problem there, but mabl looks at it and thinks it may be them. I’m super impressed, of all the stuff I’ve tried only GhostInspector actually recorded and replayed without significant recoding and that was only Chrome/Firefox. They’re still working on a fix as of “press time.” They also do PDF testing, which we need..
So it works great and looks good! And they have a lot of cool dev integration and stuff to get into, it uses a branching model for the tests, you can run the tests locally… Great looking ecosystem. You can’t choose like OS platform though, the Chrome and Firefox are just on Linux. At our current level of detail that’s fine.
Next step is discussing pricing (Web site just says “contact us”)… And unfortunately it’s way, way out of reach of a 10-person startup. The cross-browser and PDF testing are part of the “Enterprise plan” but even if I sweet talk them into putting those features in their lowest cost plan it’s still cost prohibitive for us while we’re in seed round. I mean, it’s totally worth it because it works out of the box without fiddling around, if I were still at AT&T Cybersecurity I’d make someone spring for it for sure, but it’s an extremely significant pricing step above these other solutions and not at the value point for where we are right now. Dang.
OK so my new bottom line is this.
So for us being on a seed round budget, EndTest is probably the best compromise of functionality and price at this point, YMMV of course.
I’m working for a startup right now and we don’t have a huge excess of development staff. Our devs have been implementing UI testing in Cypress, but we also need some wide cross-browser testing of our front end Angular apps – we’d already found a couple blocker bugs on Edge and IE largely by accident. The devs are all busy devving, so I figured I’d take that on. I said, “Well, there’s products where you can just click to record a UI session and replay it in other browsers without writing a bunch of code, let’s try that out.” Most everyone has a free trial nowadays so I could see which ones were best. Then the pain began.
I had used Sauce in a previous life, when we had a bunch of Robot Framework/Selenium tests and I liked it. So I went there first. Unfortunately, they have no record/replay capability, verified by their support, so I moved on.
But I came back later because I had found that there was a Selenium IDE that’s a record and playback tester that you can integrate with Sauce by using selenium-side-runner.
Selenium IDE is very cool, its killer feature is that as it records it copies various ways to address an item on the screen – css, xpath, full xpath – and when it replays if the first one doesn’t work it tries the next one and if that works tells you “hey you should update this test.” That’s great because UI testing is shitty and unreliable at best, and once you have Angular generating ever-changing ids for elements it is even worse. The only bad thing is you have to go add assertions in manually afterwards.
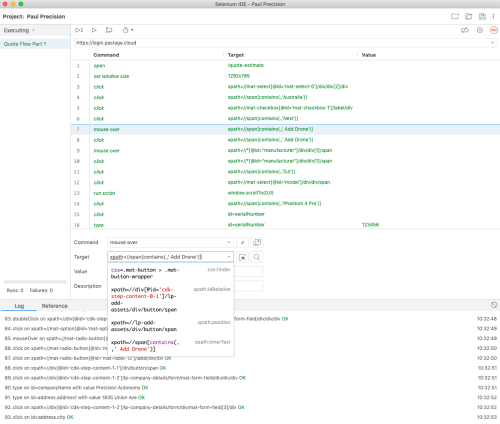
So in fairly short order, I managed to get a reproducible Selenium IDE script that exercised our Angular app and works. The app’s just like 7 screens of form fill, it’s not crazy.
Well, then I tried to save it as a “.side” project and feed it through Sauce by using selenium-side-runner, which is just:
npm install -g selenium-side-runner
selenium-side-runner –server <sauce-url> -c “browserName=’chrome’ version=’latest’ platform=’macOS 10.14′” ‘Paul Precision.side’
You get that sauce URL that has credentials embedded under User Settings/Driver Creation in their UI.
Unfortunately once I push it to sauce (starting on the same OS/browser, which you go get the tokens for from their Platform Configurator) – problems. The player is great, it shows the video (even live while testing) synced to the step taking place (unfortunately since I’m piping it in, it’s not showing the steps in the test syntax, but in raw Selenium execution syntax).
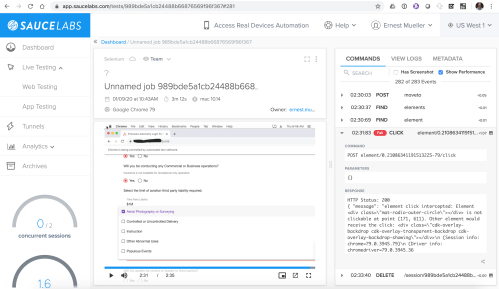
I fixed most of them by going and changing selectors away from CSS to xpath, then sitting there iterating with chrome dev tools and the IDE trying new ways to use an item that works in chrome then works in selenium IDE and then… Doesn’t work on Sauce. I have gotten it 90% working but the last 10% is blocking me.
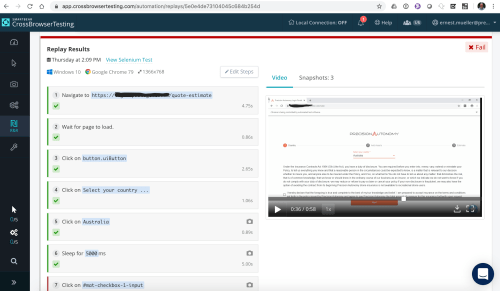
Next I tried SmartBear’s CrossBrowserTesting.com. An all-in-browser recorder that worked great! And then the replays didn’t work. I messed with it a while and contacted their support, who said “Oh yeah it doesn’t do angular, it’s for static pages.” So on to the next one. Who uses static pages, this is 2020?
The interface is nice enough, editable steps next to a running video (though not synced up).
Actually looking at it closer I bet I could do the same “edit all the locators” deal and try to get it to work but… My 7 day trial is over (a week shorter than the other options) so I guess I can’t try. It didn’t do the nice multi-locator guessing Selenium IDE did but it does seem to have several options in a dropdown while I edit the tests, and the recorder is integrated into the offering so that’s nice – the UI was good overall. Unfortunately the super short trial and the presales support saying “Angular? Go away!” prevented me from really seeing if it can work for us.
Demoralized, I head to Twitter, and someone recommends GhostInspector. You record it with a Chrome plugin and then replay in the browser – video, but then it shows the editable steps next to a screenshot showing % change from the last screenshot (the steps aren’t synced to the video, which would be better) . You can do assertions while you’re recording. And the replay works the first time and every time – Hallelujah!
And then I look to set up cross-browser and discover they only support Chrome and Firefox, and to even do that in an automated manner you have to duplicate the entire test suite. I was so disappointed, it worked perfectly otherwise.
Seriously y’all if you add more browsers I’ll pay you immediately for this.
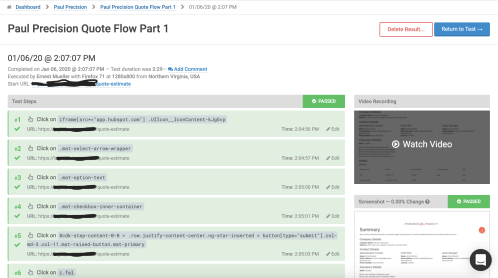
Determined to make this happen I find EndTest and, after verifying they support a full OS/browser matrix, try them. They also use a browser plugin recorder like GhostInspector.
I’ll be honest, the UX is terrible. Besides the 1990s colored icons, everything is always a click away – you have to watch the replay video separately from looking at the logs from looking at the steps from editing the steps. Everyone, the magic combination is editable steps to the left, running video and logs to the right, highlight the step you’re on as it plays. Anything else harms your usability. And also while editing steps you can’t add a step in just anywhere, you have to add it at the end of your 100 steps and then drag it up page by page… And often when you do that you just get “error saving test” messages for no reason. Argh.
But… The recording is quick and then it is semi working. Tempting. Now I start the iterative edit-replay-debug cycle. It is slow. You get to give your steps a name but those names don’t show up in the test output, because why would they. After an afternoon of fiddling, I’m halfway through a 7 screen flow. Their support was nicely proactive and reached out to me about an error (I was looking for text with a $ in it and you can’t do that, but you can define a variable and then use that…)
It’s at this point I also find the Selenium IDE and bring Sauce back into the mix.
Next, what I was doing was fiddling with the steps in the Selenium IDE, then pumping those changes both into Sauce via CLI and manually editing them into EndTest’s UI, desperately hoping to get one to pass (they don’t act the same under the same inputs for whatever reason).
Locator by locator I grind through making the test work. I have a lot of trouble where we use multiple option mat-selects, because they “stay open” while you select items and I can’t get them to close. I try sending ESCAPE keys but can’t get that to work, I try double clicking on other things… One of our devs figured out the magical thing to click on was the overlay backdrop (css=.cdk-overlay-backdrop) to close the damn multiselect box.
This takes several grueling days. I ask support folks for help but don’t really get any useful traction. Finally, I get a magic combination in the Selenium IDE that also works in Sauce! I try the same ones in EndTest and they don’t work.


It’s super frustrating. The same locator doesn’t work in all 3 tools, often forcing me to choose a less portable option – instead of something resilient to change like “xpath=//span[contains(.,’Visual Line of Sight’)]” – which works in some cases – I end up having to use something like like xpath=//mat-option[@id=’mat-option-87′]/mat-pseudo-checkbox (and sadly in angular material those IDs randomize unpredictably). Like, there will literally be two identical-except-for-the-text-and-ids-in-them widgets one after the another and one kind of locator works on the first one and not on the second. No idea why.
OK, so of all the options the only one that actually works for me and will allegedly do crossbrowser testing is an unsupported combo of Selenium IDE and Sauce run off the command line. A couple sources I found over the course of this:
Not optimal, but at this point I’m a week in and taking what I can get. Let’s try an actual crossbrowser matrix now. Bonus hacky Bash script:
#!/usr/bin/env bash tests=("Paul Precision.side") platforms=("browserName='chrome' version='latest' platform='macOS 10.14'" "browserName='chrome' version='latest' platform='Windows 10'" "browserName='chrome' version='latest' platform='Linux'" "browserName='MicrosoftEdge' version='latest' platform='Windows 10'" "browserName='safari' version='latest' platform='macOS 10.14'" "browserName='firefox' version='latest' platform='macOS 10.14'" "browserName='internet explorer' version='latest' platform='Windows 10'") for test in "${tests[@]}" do for platform in "${platforms[@]}" do echo Running "${test}" "${platform}" echo selenium-side-runner --server https://<secrets>@ondemand.saucelabs.com:443/wd/hub -c "${platform}" "${test}" done done
Chrome on MacOS – works. Chrome on Windows – works. Chrome on Linux – for some reason can’t find a selector early on. Edge on Windows – weird proxy 400 error, won’t even load the page. Pretty sure that’s not my fault. Safari on MacOS – can’t click on the first things it needs to click on. Firefox on MacOS – same error? Really? Now IE… Out of minutes (despite the UI telling me .6 automated hours remain).
I have tried all these os/browser combos manually and they work.
So my conclusion is all these suck and I guess I just need to pay manual QA people to click on our app. Great. Or for Cypress to get off their butts and add cross-browser support, which they say “is coming” for three years now.
We’re a startup and time is money, so in the end cross-browser testing is not worth the hassle in all these solutions. But it is important and I’d love someone to make a solution that actually works for it.
P.S. Please do not suggest another solution unless it has a) UI record and replay capability and b) is cross browser (Chrome/Firefox/Safari/IE/Edge on Windows/MacOS/Linux). I know there’s a million browser automation testing tools out there, that’s not what I need.
I put some more time into this and got some working options – see Record and Replay Browser Testing, Take 2!
Filed under DevOps
As a follow-on to Why Your Monitoring Is Lying To You. How is it that you can have an application go through a whole test phase, with two-day-long load tests, and have surprising errors when you go to production? Well, here’s how… The same application I describe in the case study part of the monitoring article slipped through testing as well and almost went live with some issues. How, oh how could this happen…
Our developers quite reasonably said “But we’ve been developing and using this app in dev and test for months and haven’t seen this problem!” But consider the effects at work in But, You See, Your Other Customers Are Dumber Than We Are. There are a variety of levels of effect that prevent you from seeing intermittent problems, and confirmation bias ends up taking care of the rest.
The only fix here is rigor. If you hit your application and test and it errors, you can’t just ignore it. “I hit reload, it worked. Maybe they were redeploying. On with life!” Maybe it’s your layer, maybe it’s another layer, it doesn’t matter, you have to log that as a bug and follow up and not just cancel the bug as “not reproducible” if you don’t see it yourself in 5 minutes of trying. Devs sometimes get frustrated with us when we won’t let up on occurrences of transient errors, but if you don’t know why they happened and haven’t done anything to fix it, then it’s just a matter of time before it happens again, right?
We have a strict policy that every error is a bug, and if the error wasn’t detected it is multiple bugs – a bug with the monitoring, a bug with the testing, etc. If there was an error but “you don’t know why” – you aren’t logging enough or don’t have appropriate tools in place, and THAT’s a bug.
I’ll be honest, we don’t have much in the way of automated testing in place. So there’s that. But we have long load tests we run. “If there are intermittent failures they would have turned up over a two day load test right?” Well, not so fast. How confident are you this error is visible to and detected by your load test? I have seen MANY load test results in my lifetime where someone was happily measuring the response time of what turned out to be 500 errors. “Man, my app is a lot faster this time! The numbers look great! Wait… It’s not even deployed. I hit it manually and I get a Tomcat page.”
Often we build deliberate “lies” into our software. We throw “pretty” error pages that aren’t basic errors. We are trying not to leak information to customers so we bowderlize failures on the front end. We retry maniacally in the face of failed connections, but don’t log it. We have to use constrained sets of return codes because the client consuming our services (like, say, Silverlight) is lobotomized and doesn’t savvy HTTP 401 or other such fancy schmancy codes.
Be careful that load tests and automated tests are correctly interpreting responses. Look at your responses in Fiddler – we had what looked to the eye to be a 401 page that was actually passing back a 200 HTTP return code.
The best fix to this is test driven development. Run the tests first so you see them fail, then write the code so you see them work! Tests are code, and if you just write them on your working code then you’re not really sure if they’ll fail if somethings bad!
Also, you need to perform positive and negative fault testing. Test failures end to end, including monitoring and logging and scaling and other management stuff. At the far end of this you have the cool if a little crazy Chaos Monkey. Most of us aren’t ready or willing to jack up our production systems regularly, but you should at least do it in test and verify both that things work when they should and that they fail and you get proper notification and information if they do.
Try this. Have someone Chaos Monkey you by turning off something random – a database, making a file system read only, a back end Web service call. If you have redundancy built in to counter this, great, try it with one and see the failover, but then have them break “all of it” to provoke a failure. Do you see the failure and get alerted? More importantly, do you have enough information to tell what they broke? “One of the four databases we connect to” is NOT an adequate answer. Have someone break it, send you all the available logs and info, and if you can’t immediately pinpoint the problem, fix that.
In the end, a lot of this boils down to How Complex Systems Fail. You can have failures at multiple levels – and not really failures, just assumptions – that stack on top of each other to both generate failures and prevent you from easily detecting those failures.
Also consider that you should be able to see those “short of failure” errors. If you’re failing over, or retrying, or whatnot – well it’s great that you’re not down, but don’t you think you should know if you’re having to fail over 100x more this week? Log it and turn it into a metric. On our corporate Web site, there’s hundreds of thousands of Web pages, so a certain level of 404s is expected. We don’t alert anyone on a 404. But we do metricize it and trend it and take notice if the number spikes up (or down – where’d all that bad content go?).
Whoelsale failures are easy to detect and mitigate. It’s the mini-failures, or things that someone would argue are not a failure, on a given level that line up with the same kinds of things on all the other layers and those lined up holes start letting problems slip through.
http://www.codinghorror.com/blog/2011/04/working-with-the-chaos-monkey.html
Filed under DevOps
Welcome to the second installment in Scrum for Operations, a series where I talk about (and go through) the process of doing systems work as part of a DevOps team according to the Scrum methodology. Last time, I introduced the basics of Scrum as it generally is used, and its key benefit of frequently delivering useful functionality. But I already hear the objections – “How can that turn out all right?” It is so light on process that one’s initial inclination is to dismiss it as “cowboy coding”, and we already know not to be “cowboy sysadmins,” right? One’s intuition might be (and mine was in the beginning, I’ll be honest) that this would lead to a metastable process that could not be sustainable without fundamental fatal flaws overtaking it.
Well, as I learned after trying to learn more and kicking the tires with our dev team here, there are several core disciplines that are agile’s saving graces.
We ops guys are used to testing being a neglected afterthought in the development process, often tossed over the wall to a QA team that isn’t well integrated into the product. Therefore we have a hard time trusting code that’s being handed over to us given our experience – we get it handed to us and it doesn’t work!
Well, agile pretty much understands that without pervasive testing, this kind of fast cycle process is doomed. At its extreme, some practitioners use Test Driven, aka Test First, development where failing tests must be written first and then code filled in behind it till the test passes. This creates a large inherent test framework.
Even agile groups that don’t do this almost always have metrics on unit test coverage and a required bar devs must hit. Here, our desktop software group that’s newly using Scrum has the mandate that “there must be XX% unit test code coverage or you’re not ready to ship.”
Similarly, acceptance testing (automated continuous testing of user stories vs the code) is a common part of agile. Continuous ongoing testing ensures quality through the dev cycle and reduces the need for time-intensive, and mysteriously always insufficient, big-cycle regression testing.
This is a great culture. And there’s all kinds of different tests – unit test, integration/functional/regression testing, performance testing, fault testing… Starting to get interesting to you? How about monitoring? In reality application monitoring is a special case of testing – it’s a “lightweight integration regression test.” Our initial approach to DevOps includes making test coverage goals for things like monitors and performance testing, because that plugs into the existing agile mindset well.
Bonus new terminology thing – the quick acceptance test you do upon release, which we always called “critical path testing,” is now being called “smoke testing” by the hip. Update your dictionaries!
A side note on formal QA groups. Just as we are working on DevOps, there has been previous work on how QA teams interact with agile dev teams, and there are a variety of different doctrines on how to split the work – often, it’s devs that are responsible for a lot of the testing. It’s a hard balance – you want the devs to be responsible for some of the testing because the best testing is “close to the code,” but just like with Ops, a real QA team has expertise beyond what a developer can just bolt in with 10% of their attention. Here, we have a dev team and also a remote QA team; devs test their own code on the daily build and then there’s a weekly push to a more stable environment where the QA team does acceptance testing and is moving into performance testing and the like.
Anyway, this endemic focus on testing and automation of testing and testing metrics is the pin that makes this agile flywheel actually turn without just flying off. (You are correct, some agile teams don’t do this – we call those “the unsuccessful ones.”)
And this is for you to do as well! There’s a whole post or series of posts in the topic “What does a unit test mean for something infrastructurey” – it is incumbent on you to figure it out and also have high test coverage with your work.
In general, agile dev is the epitome of horizon planning. You know you can’t get all the requirements ahead of time (or if you do get them all ahead of time, what you come out with won’t serve any real human’s need) and similarly preplanned architecture and design often doesn’t survive contact with the scrum. So it’s not “don’t plan or design,” but it’s “plan and design in an ongoing manner.”
This is one of the scariest parts for an ops person – we assume that we get one “bite at the apple”, and once we’ve set up the systems and let in the developers, we’ll never be allowed to change anything without a fight. But developers have this problem internally all the time – one dev is working on a core library or API that other developers are using, and they don’t wait for core guy to get done before they start. Instead, they have adopted a concept they call refactoring. Refactoring just means that each sprint, you are open to redoing fundamental stuff that needs to change (or that you realize you did kinda ghetto in the first place).
Because this is an accepted part of the iterative approach, you get to leverage this as well.First iteration they get the basic Tomcat and mySQL install out of the repo, and they can get started – and then in the second iteration you front it with Apache, or tune the DB for security, or whatnot and they have to make some changes to fit. I’m not promising no one will ever cry about this, but it’s a part of what makes the culture successful so it’s there for you to leverage.
And for you to adhere to! Be open to refactoring your infrastructure based on the emerging project needs.
A developer might not even mention this, and most books on agile don’t, because to them it’s so fundamental a discipline that it’s like breathing air. Sadly the same can not be said of Ops folks, so I’m mentioning it. When code is changed, it is in a shared source control repository – which gives other people on the group visibility into it (a collaboration touchpoint), is a common place to source it from (a deployment touchpoint), and can be used to easily manage multiple versions, even experimental ones, and merge or roll back changes.
This is the most fundamental empowering technology of modern software development (not just agile) and you must uptake it immediately or you have lost. Fair warning. It is the stepping stone that will allow subsequent Cool DevOps Automation to happen.
These three disciplines convert agile/Scrum from dangerous free-for-all to a new technique that gets your product done both more quickly and with higher quality than a waterfall method. I’ll talk further next time about how Ops slots into all this, and how you can fit your systems admin work into a Scrum mindset.
Also note, there’s some other agile disciplines surrounding agile design and encapsulation and patterns and whatnot, which I don’t understand well enough yet to speak authoritatively on. Feel free and chime in with other core disciplines if you are!
Filed under DevOps
Everyone thinks they know how to test… Most people don’t. And most people think they know what automated testing is, it’s just that they never have time for it.
Into this gap steps an interesting white paper, The Automated Testing Handbook, from Software Test Professionals, an online SW test community. You have to register for a free community account to download it, but I did and it’s A great 100-page conceptual introduction to automated testing. We’re trying to figure out testing right now – it’s for our first SaaS product so that’s a challenge, and also because of the devops angle we’re trying to figure out “what does ‘unit test’ mean regarding an OS build or a Tomcat server before it gets apps deployed?'” So I was interested in reading a basic theory paper to give me some grounding; I like doing that when engaging in a new field rather than just hopping from specific to specific.
Some takeaways from the paper:
Your tests should be version controlled, change controlled, etc. just like software (testware?).
Great quote from p.47:
A thorough test exercises more than just the application itself: it ultimately tests the entire environment, including all of the supporting hardware and surrounding software.
We are having issues with that right now and our larval SaaS implementation – our traditional software R&D folks historically can just do their own narrow scope tests, and say “we’re done.” Now that we’re running this as a big system in the cloud, we need to run integration tests including the real target environment, and we’re trying to convince them that’s something they need to spend effort in.
They go on to mention major test automation approaches, including capture/replay, data-driven, and table-driven – their pros and cons and even implementation tips.
I guess writing pure code to test is an unspoken #4, but unspoken because she (the author) doesn’t think that’s a real good option.
There’s a bunch of other stuff in there too, it’s a great introduction to the hows and whys and gotchas of test automation. Give it a read!
Filed under DevOps
