
Well, last Thursday and Friday I went to LASCON, our local Austin application security convention! It started back in 2010; here’s the videos from previous years (the 2017 talks were all recorded and should show up there sometime soon. Some years I get a lot out of LASCON and some I don’t, this one was a good one and I took lots and lots of notes! Here they are in mildly-edited format for your edification. Here’s the full schedule, obviously I could only go to a subset of all the great content myself. They pack in about 500 people to the Norris Conference Center in Austin.
Day 1 Keynote
The opening keynote was Chris Nickerson, CEO of LARES, on pen testing inspired thoughts. Things I took away from his talk:
- We need more mentorships/internships to get the skills we need, assuming someone else is going to prep them for us (school?) is risible
- Automate and simplify to scale and enable lower skill folks to do the job – if you need all security geniuses to do anything that’s your fault
- There’s a lack of non made up measurements – most of the threat severities etc. are in the end pure judgement calls only loosely based on objective measures
- Testing – how do we know it’s working?
- How do all the tools fit together? Only ops knows…

- Use an attack inventory and continually test your systems
- Red team automation plus blue team analytics gives you telemetry
- Awareness of ego:

Security for DevOps

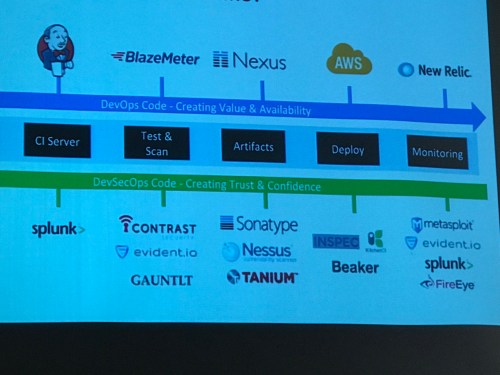
Then the first track talk I went to was on Security for DevOps, by Shannon Lietz, DevSecOps Leader at Intuit. She’s a leader in this space and I’ve seen her before at many DevOps conferences.
Interesting items from the talk:
- Give security defects to your devs, but characterize adversary interest so they can prioritize.
- Reduce waste in providing info to devs.
- 70-80% of bad guys return in 7 days – but 20% wait 30d till your logs roll
She likes to use the killchain metaphor for intrusion and the MITRE severity definitions.
But convert those into “letter grades” for normal people to understand! Learn development-ese to communicate with devs, don’t make them learn your lingo.
Read the Google Beyondcorp white papers for newfangled security model:
1. zoning and containment
2. Asset management
3. Authentication/authorization
4. Encryption
Vendors please get to one tool per phase, it’s just too much.
Other things to read up on…
- Devsecops playbook at SANS
- Go to Devsecops symposiums from IANS
- Devsecops lessons at OWASP
- Full stack attack at RSA
Startup Security: Making Everyone Happy
 By Mike McCabe and Brian Henderson of Stratum Security (stratumsecurity.com, github.com/stratumsecurity), this was a great talk that reminded me of Paul Hammond’s seminal Infrastructure for Startups talk from Velocity. So you are getting started and don’t have a lot of spare time or money – what is highest leverage to ensure product security?
By Mike McCabe and Brian Henderson of Stratum Security (stratumsecurity.com, github.com/stratumsecurity), this was a great talk that reminded me of Paul Hammond’s seminal Infrastructure for Startups talk from Velocity. So you are getting started and don’t have a lot of spare time or money – what is highest leverage to ensure product security?
They are building security SaaS products (sold one off already, now making XFIL) and doing security consulting. If we get hacked no one wants our product.
The usual startup challenges – small group of devs, short timelines, new tech, AWS, secrets.
Solutions:
- Build security in and automate it
- Make use of available tools, linters, SCA tools, fuzzing
- Continuous testing
- AWS hardening
- Alerting
- Not covering host security, office security, incident response here

They use AWS, codeship, docker (benefits – dev like in prod, run tools local, test local). JavaScript, golang, no more rust (too bleeding edge). Lack of security tooling for the new stuff.
Need to not slow down CI, so they want tooling that will advise and not block the build. The highest leverage areas are:
- Linting – better than nothing. ESLint with detect-unsafe-regex and detect-child-process. Breaks build. High false positives, have to tweak your rules. Want a better FOSS tool.
- Fuzzing – gofuzz based on AFL fuzz, sends random data at function, use on custom network protocols
- Source code analysis – HP Gas
- Automated dynamic testing – Burp/ZIP
- Dependency checking. Dependencies should be somewhat researched – stats, sec issues (open/closed and how their process works)
- Pull requests – let people learn from each other
Continuous integration – they use codeship pro and docker
Infrastructure is easy to own – many third party items, many services to secure
AWS Tips:
- Separate environments into AWS accounts
- Don’t use root creds ever
- Alert on root access and failed logins with cloudwatch. [Ed. Or AlienVault!]
- All users should use MFA
- Rigorous password policy
- Use groups and roles (not direct policy assignment to user)
- Leverage policy conditions to limit console access to a single IP/range so you know you’re coming in via VPN
- Bastion host – alert on access in Slack
- Duo on SSH via PAM plugin
- Must be on VPN
- Use plenty of security groups
- AWS alering on failed logins, root account usage, send to slack
See also Ken Johnson’s AWS Survival Guide
Logging – centralize logs, splunk/aws splunk plugin (send both direct and to Cloudwatch for redundancy), use AWS splunk plugin.
Building the infrastructure – use a curated base image, organize security groups, infra as code, manage secrets (with IAM when you can). Base image using packer. Strip down and then add splunk, cloudwatch, ossec, duo, etc. and public keys. All custom images build off base.
Security groups – consistent naming. Don’t forget to config the default sec group even if you don’t intend to use it.
Wish we had used Terraform or some other infrastructure as code setup.
Managing secrets – don’t put them in plain test in github, docker, ami, s3. Put them into KMS, Lambda, parameter store, vault. They do lambda + KMS + ECS. The Lambda pulls encrypted secrets out of s3, pushes out container tasks to ecs with secrets. See also “The Right Way To Manage Secrets With AWS” from the Segment blog about using the new Parameter Store for that.
Next steps:
- more alerting esp. from the apps (failed logins, priv escalation)
- terraform
- custom sca (static analysis)
- automate and scale fuzzing maybe with spot instances
Security is hard but doesn’t have to be expensive – use what’s available, start from least privilege, iterate and review!
Serverless Security

By fellow Agile Admin, James Wickett of Signal Sciences. Part one is introducing serverless and why it’s good, and then it segues to securing serverless apps halfway in.
Serverless enables functions as a service with less messing with infrastructure.
What is serverless? Adrian Cockroft – “if your PaaS can start instances in 20ms that run for half a second, it’s serverless.” AWS Lambda start time is 343 ms to start and 84 ms on subsequent hits, not quite the 20ms Cockroft touts but eh. Also read https://martinfowler.com/articles/serverless.html and then stop arguing about the name for God’s sake. What’s wrong with you people. [James is too polite to come out and say that last part but I’m not.]
Not good for large local disk space, long running jobs, big IO, super super latency sensitive. Serverless frameworks include serverless, apex, go sparta, kappa. A framework really helps. You get an elastic, fast API running at very low cost. But IAM is complicated.
So how to keep it secure?
- Externalize stuff out of the app/infra levels – do TLS in API gateway not the app, routing in API gateway not the app.
- There’s stack element proliferation – tends to be “lambda+s3+kinesis+auth0+s3+…”
- Good talk on bad IAM roles – “Gone in 60 seconds: Intrusion and Exfiltration in Serverless Architectures” – https://www.youtube.com/watch?v=YZ058hmLuv0
- good security pipeline hygeine
- security testing in CI w/gauntlt
- DoS challenges including attack detection…
- github/wickett/lambhack is a vulnerable lambda+api gateway stack like webgoat. you can use it to poke around with command execution in lambda… including making a temp file that persists across invocations
- need to monitor longer run times, higher error rate occurrences, data ingestion (size), log actions of lambdas
- For defense: vandium (sqli wrapper), content security policies
And then I was drafted to be in the speed debates! Less said about that the better, but I got some free gin out of it.
Architecting for Security in the Cloud

By Josh Sokol, Security Spanker for National Instruments! He did a great job at explaining the basics. I didn’t write it all down because as an 3l33t Cloud Guru a lot wasn’t new to me but it was very instructive in reminding me to go back to super basics when talking to people. “Did you know you can use ssh with a public/private key and not just a password?” I had forgotten people don’t know that, but people don’t know that and it’s super important to teach those simple things!
- Code in private GitHub repo
- Automation tool to check updates and deploy
- Use a bastion to ssh in
- Good db passwords
- Wrap everything in security groups
- Use vpcs
- Understand your attack surfaces – console, github, public ports
- Analyze attack vectors from these (plus insiders)
- Background checks for employees
- Use IAM, MFA, password policies
- Audit changes
- The apps are the big one
- Https, properly configured
- Use an IPS/WAF
- Keys not just passwords for SSH
- Encrypt data before storing in db
Digital Security For Nonprofits


Dr. Kelley Misata was an MBA in marketing and then got cyber stalked. This led to her getting an InfoSec Ph.D from Spaf at Purdue! Was communications director for Tor, now runs the org that manages Suricata.
Her thesis was on the gap of security in nonprofits, esp. violence victims, human trafficking. And in this talk, she shares her findings.
Non-profits are being targeted for same reasons as for-profits as well as ideology, with int’l attackers. They take money and cards and everything like other companies.
63% of nonprofits suffered a data breach in a 2016 self report survey. Enterprises vet the heck out of their suppliers… But hand over data to nonprofits that may not have much infosec at all.
ISO 27000, Cobit 5… normal people don’t understand that crap. NIST guidance is more consumable – “watered down” to the infosec elite but maps back to the more complex guidelines.
She sent out surveys to 500 nonprofits expecting the normal rate of return but got 222 replies back… That’s an extremely high response rate indicating high level of interest.
Nonprofits tend to have folks with fewer tech skills, and they more urgent needs than cyber security like “this person needs a bed tonight.” They also don’t speak techie language – when she sent out a followup a common question was “What does “inventory” mean?”
90% of nonprofits use Facebook and 53% use Twitter. They tend to have old systems. Nonprofit environments are different because what they do is based on trust. They get physical security but don’t know tech.
 They are not sure where to go for help, and don’t have much budget. Many just use PayPal, not a more general secure platform, for funds collection. And many outsource – “If we hand it off to someone it must be secure!”
They are not sure where to go for help, and don’t have much budget. Many just use PayPal, not a more general secure platform, for funds collection. And many outsource – “If we hand it off to someone it must be secure!”
The scary but true message for nonprofits is that it’s not if but when you will have a breach. Have a plan. Cybersecurity insurance passes the buck.
You can’t be effective if you can’t message effectively to your audience. She uses “tinkerer” not hacker for white hats, because you can complain all you want about “hacker not cracker blah blah” but sorry, Hollywood forms people’s views, and normal people don’t want a “hacker” touching their stuff period.
Even PGP encrypting emails, which is very high value for most nonprofits, is ridiculously complicated for norms.
What to do to improve security of nonprofits? Use an assessment tool in an engaging way. Help them prioritize.
She is starting a nonprofit, Sightline Security for this purpose. Check it out! This was a great talk and inspires me to keep working to bring security to everyone not just the elite/rich – we’re not really safe until all the services we use are secure.

Malware Clustering

By Srini (Srivathsan Srinivasagopalan), a data scientist from my team at AlienVault!
Clustering malware into groups helps you characterize how families of it work, both in general and as they develop over time.
To cluster, you need to know what behavior you want to cluster on, it’s too computationally challenging to tell the computers “You know… group this stuff similarly.”
You make signatures to match samples on that behavior. Analyzed malware (like by cuckoo) generally gives you static and dynamic sections of behavior you can use as inputs. There’s various approaches, which he sums up. If you’re not into math you should probably stop reading here so as to not hurt yourself.
To hash using shingling – concatenate a token sequence and hash them.
Jaccard similarity is computationally challenging.
Min-hashing
Locality sensitive hash based clustering
Hybrid approach: corpus vectorization

Next…Opscode clustering! Not covered here.
TL;DR, there’s a lot of data to be scienced around security data, and it takes time and experimentation to find algorithms that are useful.
Cloud Ops Master Class
 By @mosburn and @nathanwallace
By @mosburn and @nathanwallace
Trying to manage 80 teams and 20k instances in 1 account – eek! Limits even AWS didn’t know about.
They split accounts, went to bakery model. Workload isolation.
They wrote tooling to verify versions across accounts. It sucked.
Ride the rockets – leverage the speed of cloud services.
Change how the team works to scale – teach, don’t do to avoid bottlenecking. App team self serves. Cloud team teaches.
 Policies: Simple rules. Must vs should. Always exceptions.
Policies: Simple rules. Must vs should. Always exceptions.
The option requirement must be value in scope.
Learn by doing. Guardrails – detect and correct.
 Change control boards are evil – use policy not approval.
Change control boards are evil – use policy not approval.
Sharing is the devil.
Abstracting removes value – use tools natively.
- Patterns at scale
- Common language and models
- Automate and repeat patterns
- Avoid custom central services
- Accelerate don’t constrain
- Slice up example repos
- Visibility
- Audit trail
- Git style diff of infra changes
- Automate extremely – tickets and l1-2 go away
- All ops automated, all alerts go to apps so things get fixed fast
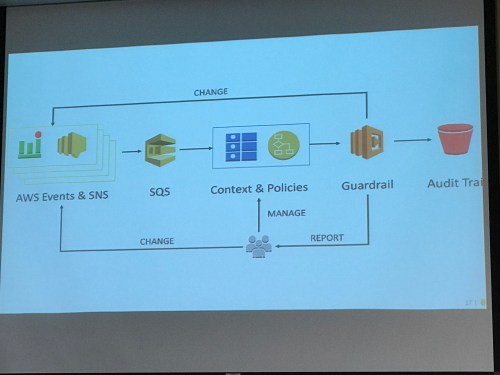
He’s created Turbot to do software defined ops – https://turbot.com/features/
- Cross account visibility
- Make a thing in the console… then it applies all the policies. Use native tools, don’t wrap.
- Use resource groups for rolling out policies
- Keep execution mostly out of the loop
And that was my LASCON 2017! Always a good show, and it’s clear that the DevOps mentality is now the cutting edge in security.
