I just got back from DevOpsDays Austin, and it’s always great to go out and talk with a wide array of folks from the tech community to see what’s up.
The takeaways were interesting. Austin is an advanced tech hub, but hasn’t been bitten by the AI bug as hard as SFO. On the one hand that worries me that our community might be getting behind, but there’s some justified bubble avoidance too.
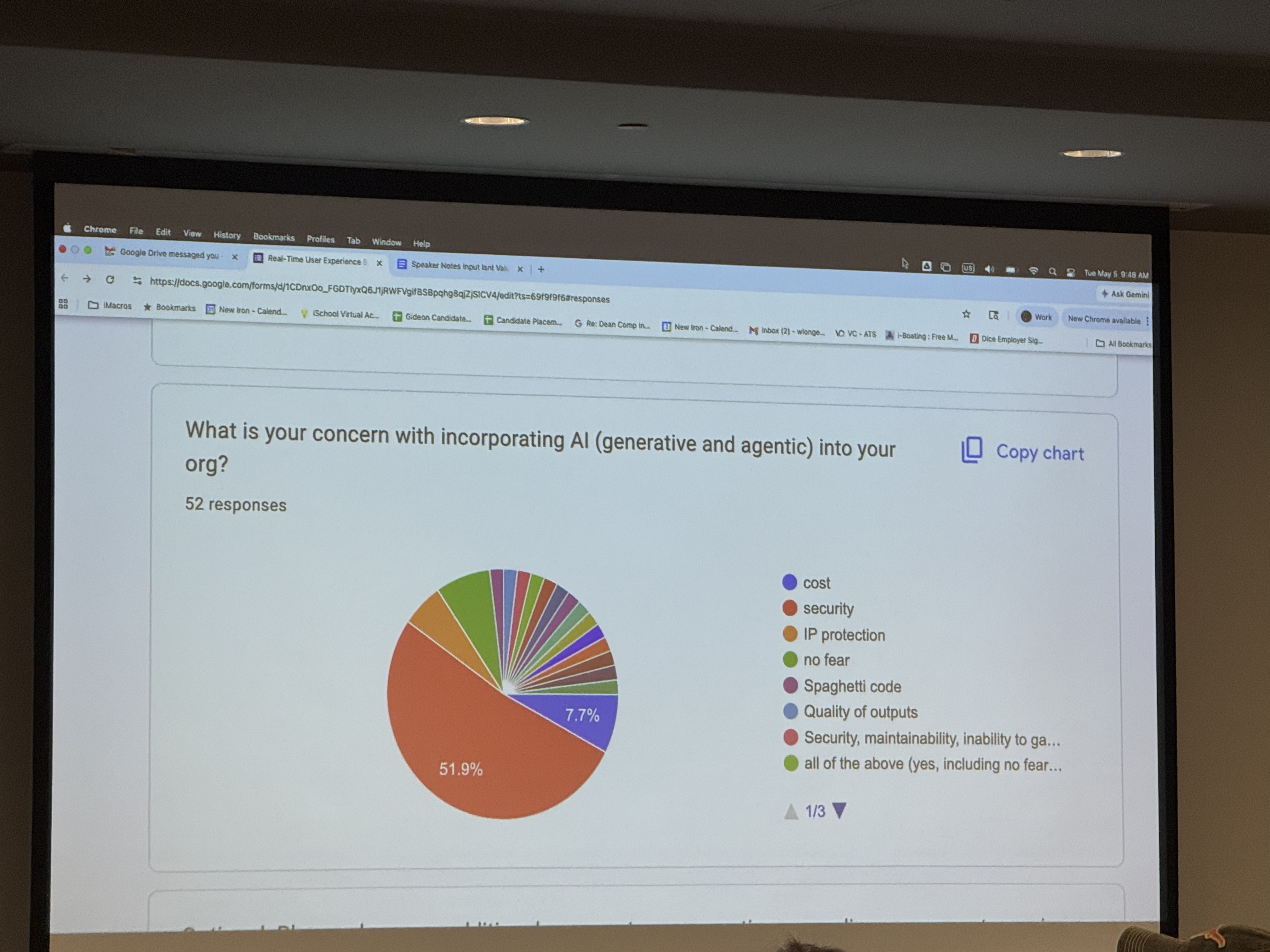
Takeaway One: AI adoption is on a curve like everything else. It is a sharp curve, but out in real businesses there’s still a sharp divide between AI’ers and non-AIers. Will Longenecker from elite tech recruiting firm New Iron shared some data from their work and it provides a much more moderate view of AI and the workforce. There’s some shops pro, some shops anti, some shops going nuts with tokenmaxxing, some shops containing costs, and so on.
from Will Longenecker of New Iron
Takeaway Two: Attitudes to AI are maturing. It’s been a rough road with AI in that there’s a lot of real awesome tech there, but the oligarch set has been blowing it into a bunch of ridiculous claims, so it’s a giant spike that’s 50% real value but 50% bubble. I found that the group was in general very AI forward and most people were using it in some way, but that there’s a real appreciation for the challenges and ROI evaluation and not just bandwagon hype.
Will did a flash survey of the group, and the interesting takeaway is that over 50% of the respondents felt security was the #1 concern with using AI agents. Other speakers and groups of practitioners at the conference talked about cost, quality, and so on.
But they weren’t just talking about it in terms of “it means it’s bad,” these folks are already trying to develop practices and tooling to mitigate it.
From a DevOps perspective, the basic description of what’s been going on in the industry it that for a long time, the technology value chain had one big, long, expensive link – software development – and a bunch of smaller links like product, testing, operations, and so on. It’s been 100 devs to a handful of SREs, security pros, and so on. Which worked when it took a long time to produce software. So companies hired up truckfuls of devs, and paid them whatever they wanted, because that’s what made the value flow.
Now producing software is much faster and less expensive, and more can be done by Product and those other links in the chain. So you see developer layoffs. But even if you lay off 20% of your devs, they are all suddenly generating code at 10x the rate. The ratio in the chain of security, quality, operations, and so on was not great in the first place but now it’s completely untenable. This is forcing an evening out of that value chain, both with more tools but also the staffing and focus has to step up. AI is not generating secure, quality, performant software – the models are trained on all the crappy software out there in the wild!
So the talks and startup tools were on how do you test more effectively,
from Daniel Ward of Lean TECHniques
How do you secure more effectively.
from James Wickett of Dry Run Security
operate more effectively.
from Peco Karayanev of Autoptic
Build more effectively,
from Sam Alba of Mendral
Manage your cost effectively.
from Ian Littman
And so on. Basically the good old rugged software model.
from Wickett again
The “tokenmaxxing” and “it must be alive” hype cycle is running out and companies and tech practitioners are buckling down to the realities of “OK, so this will get me a 20% overall advantage. Great!” 10x speed is 10x slop speed and is expensive once the token subsidies end and puts your company at risk. But, smart orgs will use the resources freed up by the “faster typing” part of the benefit to find much better solutions than they’ve had so far in these areas – to be honest the hard part has always been making software enterprise ready and many orgs have suffered calamity from not doing it well. With software now pouring out of every open faucet, leveling up in these disciplines is the new path to success.
That’s not a surprise, it’s the same “Operations is the new secret sauce” message from the Web growth era, but is forcing advances in thesse other fields as well – security, ops, etc. had to adapt to keep pace in Web 2.0 but they are still slower and more manual than is needed in this new world.
I think of it like the transition from servers to virtual servers to cloud servers to containers to kubernetes – it pushed the entire industry from manual config and runbooks to configuration management to declarative infrastructure to pervasive orchestration. AI is that same forcing function – it’s not eliminating net tech jobs or anything like that, it’s just moving them around in an inevitable way. And sure, half the silly chatbots added to every product will eventually fade away as adding no value, but AI as a ubiquitous system component is here to stay.
There’s a new DORA report out from Google, but it’s not the usual DevOps one we’ve come to expect – this one is entirely focused on the state of AI-assisted software development.
That’s not too surprising, straight up DevOps is last decade’s news – Gene Kim rebranded the DevOps Enterprise Summit and is publishing vibe coding books, the DevOps OGs like Patrick Debois and John Willis have been focusing on AI building, and so it makes sense that the DORA crew are also poking in that direction.
A lot of the shift in DevOps in recent years has been towards focusing on developer productivity. Whether that’s the rise of platforms to take burden and complexity away from devs, to Nicole Forsgren’s new SPACE metrics that extended her previous Accelerate/DORA metrics that were focused just on software delivery, everyone is keenly aware that unlocking the developers’ ability to create is important.
Companies I work with are really prioritizing that. At ServiceNow, they got Windsurf licenses for all and report a 10% productivity boost from it. And just “we have some AI” isn’t enough, Meta just cut one of their major AI teams because they had “gotten too bureaucratic” and slow so they wanted to move people to a newer team where they could get more done. So companies are taking developer productivity very seriously and spending real money and making big changes to get it.
Understanding Your Software Delivery Performance
As you read the report, you’ll notice that large chunks of it are NOT about AI directly. This first chapter, for example, recaps the important areas from previous DORA reports. It talks about metrics for software delivery and characterizes kinds of teams you see in the wild and their clusters of function and dysfunction. You don’t really get to AI till page 23.
Is this “AI-washing”? If so, it’s justified. People want “AI” to be the solution when they don’t understand their problem, or how to measure whether their problem is solved – AI can help with software engineering and DevOps but it does nothing to change the fundamental nature of any of it, so if you don’t understand the non-AI basics, if you’re handed AI to loose on your company you may as well be an armed toddler.
AI Adoption and Use
The report has good stats that dig deeper than news reports – while 90% of people are “using AI”, in general they use it maybe 1-2 hours out of their day and don’t go to it first all the time.
The thing I found the most surprising was what people were using it for. In my experience folks are using AI for the lighter work more often than actually writing code, but their research showed writing code was by far the most common use case (60%) and stuff like internal communication the least common task (48%) (outside calendar management at 25%, but the tools for that are terrible IMO).
Chatbots and IDEs are the vast majority of how people interact with AI still, integrated tool platforms only have 18% traction.
People do in general believe they’re being more productive from using AI, by a wide margin, and also believe their code quality has gone up! Pure vibe coding makes terrible quality code, I believe this is because how real coders are using AI is more thoughtful than just “write this for me.” And this is borne out in their trust metrics – most people do NOT trust AI output. 76% of respondents trust AI somewhat, a little, or not at all – despite 84% believing it has increased their productivity.
I think that’s super healthy – you should not trust AI output, but if you keep that in mind, it lets you use it and be more productive. You just have to double check and not expect magic. Consider that ServiceNow article I linked above about their Windsurf adoption, it’s not reastic to think AI is going to give you orders of magnitude of coding productivity increase – 10% is great though, more of an improvement than most other things you can do!
AI and Key Outcomes
That leads us into the meatier portion of the report, which is taking the research past “what people think” and trying to correlate real outcomes to these factors. Which is a little ticky, because developer morale is a part of what contributes to delivery and there may be a “placebo factor” where believing AI tools are making you better, makes you better whether or not the tool is contributing!
What they found is that while AI use does really improve individual effectiveness, code quality, and valuable work, it doesn’t help with friction and burnout, and has a significant negative effect on software delivery instability.
So what do we make of increased software delivery instability when we think we’re generating more and better code? And we think the org performance is still doing better? The report doesn’t know either.
My theory is similar to the answer to “why doesn’t everyone run multi-region systems when AWS us-east goes down from time to time?” Just to refresh you on the answer to that one, “it’s more expensive to do it right than to have an outage from time to time.” If you can cram more code down the pipe, you get more changes and therefore more instability. But just like companies gave up on shipping bug-free code long ago, some degree of failure with the tradeoff of shipping more stuff is a net financial win.
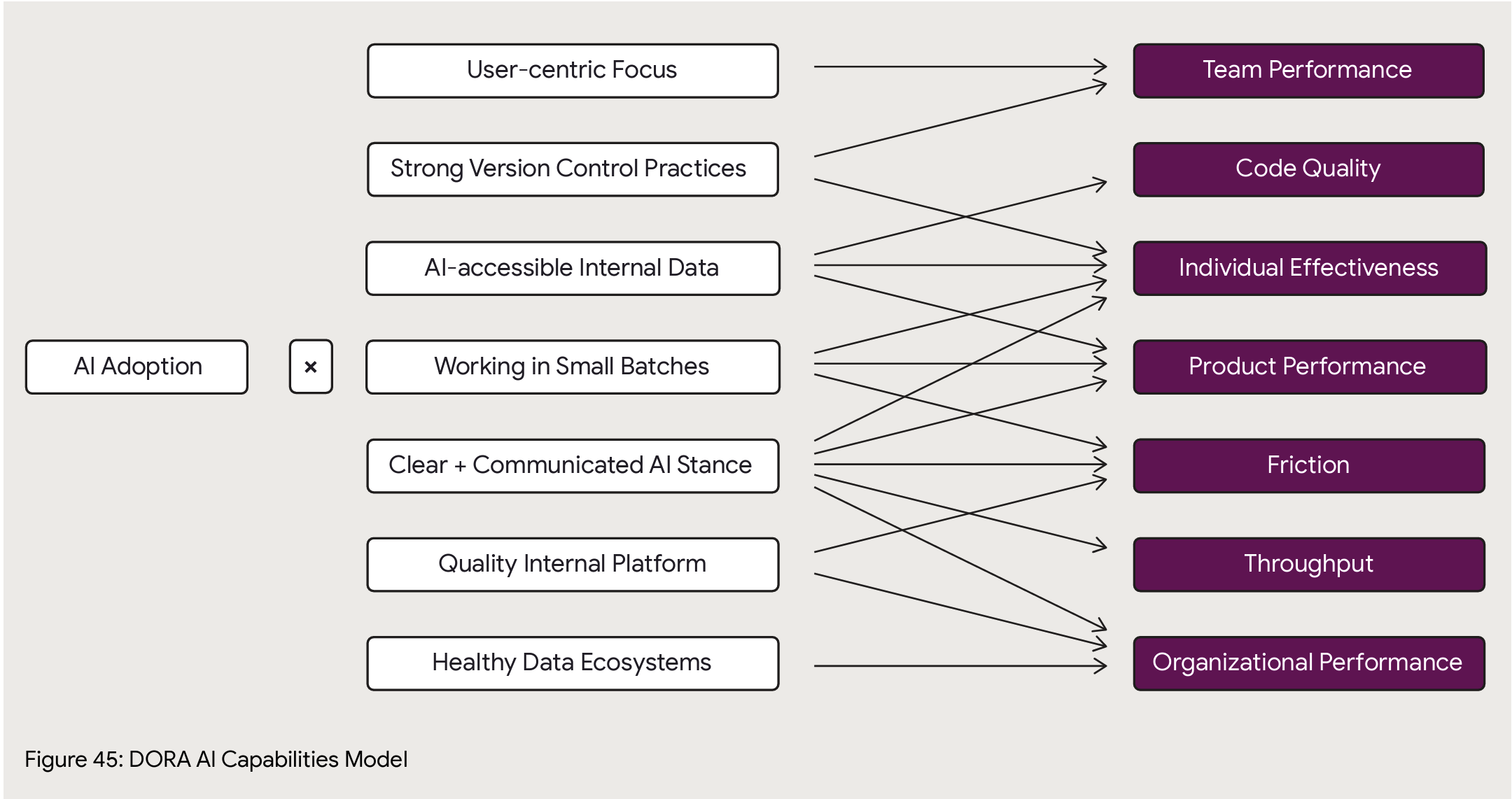
AI Capabilities Model
The reason I love DORA is they go deep and try to establish correlation of AI adoption best practices to outcomes. At page 49 is their big new framework for analysis of AI impact on an org. Here’s what they have so far on how specific practices correlate to specific outcomes, with caveats that it’ll take another year of data to know for sure (though AI innovation cycles are month by month, I hope they’ll find a way to get more data more quickly than a yearly cadence).
Platform Engineering
The report then takes another turn back to earlier DORA topics and talks about platform engineering, the benefits, and how to not suck at it.
For those who are unclear on that, you get wins from a platform that is user centric. So many organizations don’t – or deliberately mis- – understand that. You could call all the old centralized IT solutions from previous decades a “platform” – Tivoli, HP WhateverCenter, and so on – but they were universally hateful and got in the way of progress in the name of optimizing the work of some commodity team behind a ticket barrier. (I’ll be honest, there’s a lot of that at my current employer.)
I’m going to go a step farther than the report – if you don’t have a product manager guidlign your platform based on its end users’ needs, your platform is not really a platform, it’s a terrible efficiency play that is penny wise but pound foolish. Fight me.
Anyway, they then say “platforms, you know, it’s the place you can plug in AI.” Which is fine but a little basic.
Value Stream Management
Is important. The premise here is that given the basic premise of value flow (if you don’t know about lean and value streams and stuff, I’ve got a LinkedIn Learning course for you: DevOps Foundations: Lean and Agile), systems thinking dictates that if you accelerate pieces in your workflow you can actually harm your overall throughput, so major changes mean you need to revisit the overall value stream to make sure it’s still the right flow, and measure so you understand how speeding up pieces (like oh say making code) affects other pieces (like oh say release stability).
They find that AI adoption gets you a lot more net benefit in organizations that understand and engineer their value stream.
The AI Mirror
This section tries to address the mix of benefits and detriments we’ve already talked about with AI. It basically just says hey, rethink how you do stuff and see if you can use AI in a more targeted way to improve the bad pieces, so for software delivery try using it more for code reviews and in your delivery pipelines. It’s fine but pretty handwavey.
That’s understandable, I don’t think anyone’s meaningfully figured out how to bring AI to bear on the post-code writing part of the software delivery pipeline. There’s a bunch of hopefuls in this space but everything I’ve kicked the tires on seems still pretty sketch.
Metrics Frameworks
You need metrics to figure out if what you’re doing is helping or not. They mention frameworks like SPACE, DevEx, HEART, and DORA’s software delivery metrics, and note that you should be looking at developer experience, product excellence, and organizational effectiveness. “Does AI change this?” Maybe, probably not as much as you think.
And that’s the end at page 96, there’s 50 pages of credits and references and data and methodology if you want to get into it.
Those last 4 chapters feel more like an appendix, they don’t really flow with the rest of the report. The AI methodology talks about things to do specifically boost your AI capabilities (Clear and communicated AI stance… Working in small batches) which somewhat overlap (Quality internal platforms, User-centric focus) with these later chapters but to a degree don’t. If value stream management is shown to improve your AI outcomes then – why’s it not in the capability model?
I assume the answer is, to a degree, “Hey man this is a work in progress” which is fair enough.
Conclusion
I find two major benefits from reports like this, and judge their success based on how well they achieve them.
Showing clear benefits of something, so you can use it to influence others to adopt it. This report does very well there. One of my complaints about the DORA reports is that in recent years they’d become more about the “next big thing” than about demonstrating the clear benefits of core DevOps practices, so I’d often go back and refer to older reports instead of the newer ones. But here – are people getting benefit from AI? Yes, and here’s what, and here’s what not. Very cleaar and well supported.
Telling you how to best go about doing something, so you can adopt it more effectively. The report also does well here, with the caveat of “so much of this is still emerging and moving at hyperspeed that it’s hard to know.” They’ve identified practices within AI adoption and in the larger organization that are correlated to better outcomes, and that’s great.
And I do like the mix of old and new in this report. You have to wave the new shiny at people to get them to pay attention, but in the end there are core truths about running a company and a technology organization within a company – value streams, metrics, developer experience, release cadence and quality – that AI or any new silver bullet may change the implementation of, but does not change fundamentally, and it’s a good reminder that adopting sound business basics is the best way to take advantage of any new opportunity, in this case AI.
TL;DR – Good report, use it to learn how people are benefitting from AI and to understand specific things you can do to make your organization benefit the most from it!
This came up today at work and I realized that over my now-decades of cloud engineering, I have developed a very specific way of using tags that sets both infra dev teams and SRE teams up for success, and I wanted to share it.
Who cares about tags? I do. They are the only persistent source of information you can trust (as much as you can trust anything in this fallen world) to communicate information about an infrastructure asset beyond what the cloud or virtualization fabric it’s running in knows. You may have a terraform state, you may have a database or etcd or something that knows what things are – but those systems can go down or get corrupted. Tags are the one thing that if someone can see the infrastructure – via console or CLI or API or integrated tool – that they can always see. Server names are notoriously unreliable – ideally in a modern infrastructure you don’t reuse servers from one task to another or put multiple workloads on one, but that’s a historical practice that pops up all to often, and server names have character limits (even if they don’t, the management systems around them usually enforce one).
Many powerful tools like Datadog work by exclusively relying on tags. It simplifies operation and prevents errors if, when you add a new production app server, that automatically gets pulled into the right monitoring dashboards and alerting schemes because it is tagged right.
I’ve run very large complex cloud environments using this scheme as the primary means to drive operations.
Top level tag rules:
Tag everything. Tagging’s not just for servers. Every cloud element that can take a tag, tag. Network, disk images, snapshots, lambdas, cloud services, weird little cloud widgets (“S3 VPC endpoint!”).
Use uniform tags. It’s best to specify “all lower case, no spaces” and so on. If people decide to word a tag slightly differently in two places, the value is lost. Both the key and the value, but especially the key – teach people that if you say “owner” that means “owner” not “Owner” and “owning party” and whatever else.
Don’t overtag with attributes you can easily see. Instance size, what AZ it’s in, and so on is already part of the cloud metadata so it’s inefficient to add tags for it.
Use standard tags. This is what I’ll cover in the rest of this article.
At the risk of oversimplifying, you need two things out of your systems environment – compliance and management. And tags are a great way to get it.
Compliance
Attribution! Cost! Security! You need to know where infrastructure came from, who owns it, who’s paying for it, and if it’s even supposed to be there in the first place.
Who owns it?
Tag all cloud assets with an owner (email address) basically whatever is required to uniquely identify who owns an asset. Should be a team email for persistent assets, if it’s a personal email then the assumption should be if that person leaves the company those assets get deleted (good for sandboxes etc).
The amount of highly paid engineer time I’ve seen wasted over the last decade of people having to go out and do cattle calls of “Hey who owns these… we need to turn some off for cost or patch them for security or explain them for compliance… No really, who owns these…” is shocking.
owner:myteam@mycompany.com
Who’s paying for it
This varies but it’s important. “Owner” might not be sufficient in an environment – often some kind of cost allocation code is required based on how your company does finances. Is it a centralized expense or does it get allocated to a client? Is it a production or development expense, those are often handled differently from a finance perspective. At scale you may need a several-parter – in my current consulting job there’s a contract number but also a specific cost code inside that contract number that we need all expenses divvied up between.
billing:CUCT30001
Where did it come from
Traceability both “up” and “down” the chain. When you go look at a random cloud instance, even if you know who it belongs to you can’t tell how it got there. Was it created by Terraform? If so where’s the state file? Was it created via some other automation system you have? Github? Rundeck? Custom python app #25?
Some tools like Cloudformation do this automatically. Otherwise, consider adding a source tag or set of tags with sufficient information to trace the live system back to the automation. Developers love tagging git commits and branches with versions and JIRA tickets and release dates and such, same concept applies here. Different things make sense depending on your tech stack – if you GitOps everything then the source might be a specific build, or you want to say which s3 bucket your tfstate is in… Here as an example, I’m working with a system that is terraform instantiated from a gitops pipeline so I’ve made a source tag that says github and then the repo name and then the action name. And for the tfstate I have it saved in an s3 bucket named “mystatebucket.”
OK, I know the last two sound like the lyrics to “Cotton-Eyed Joe”, which is a bonus. But a major source of cost creep is infrastructure that was intended to be there for a short time – a demo, a dev cycle – that ends up just living forever. And sure, you can just send nag-o-grams to the owner list, but it’s better to tag systems with an expires tag in date format (ideally YYYY-MM-DD-HH-MM as God intended). “expires:never” is acceptable for production infrastructure, though I’ve even used it on autoscaling prod infrastructure to make sure systems get turned over and don’t live too long.
expires:2025-02-01-00-00-00 or expires:never
Management
Operations! Incidents! Cost and security again! Keep the entire operational cycle, including “during bad production incidents”, in mind when designing tags. People tear down stacks/clusters, or go into the console and “kill servers”, and accidentally leave other infrastructure – you need to be able to identify and clean up orphaned assets. Hackers get your AWS key and spin up a huge volume of bitcoin miners. Identifying and actioning on infrastructure accurately and efficiently is the goal.
As in any healthy system, the “compliance” tags above aren’t just useful to the beancounters, they’re helpful to you as a cloud engineer or SRE. But beyond that, you want a taxonomy of your systems to use to manage them by grouping operations, monitoring, and so on.
This scheme may differ based on your system’s needs, but I’ve found a general formula that fits in most cases I come across. Again, it assumes virtual systems where servers have one purpose – that’s modern best practice. “Sharing is the devil.”
EARFI
I like to pronounce this “errr-feee.” It’s a hierarchy to group your systems.
environment – What environment does this represent to you, e.g. dev, test, production, as this is usually the primary element of concern to an operator. “environment:uat” vs “environment:prod”.
application – What application or system is this hosting? The online banking app? The reporting system? The security monitoring server? The mobile game backend? GenAI training? “application:banking”.
role – What function does this specific server perform? Webserver dbserver, appserver, kafka – systems in an identical role should have identical loadouts. “role:apiserver” vs “role:dbserver”. Keep in mind this is a hierarchy and you won’t have guaranteed uniqueness across it – for example, “application:banking,role:dbserver” may be quite different from “application:mobilegame,role:dbserver” so you would usually never refer to just “role:dbserver.”
flavor – Optional, but useful in case you need to differentiate something special in your org that is a primary lever of operation (Windows vs Linux? CPU vs GPU nodes in the same k8s cluster? v2 vs v2?). I usually find there’s only one of these (besides of course region and things you shouldn’t tag because they are in other metadata). For our apiserver example, consider that maybe we have the same code running on all our api servers but via load balancer we send REST queries to one set and SOAP queries to another set for caching and performance reasons. “flavor:rest” vs “flavor:soap”.
instance – A unique identifier among identical boxes in a specific EARF set, most commonly just an integer. “instance:2”. You could use a GUID if you really need it but that’s a pain to type for an operator.
This then allows you to target specific groups of your infrastructure, down to a single element or up to entire products.
“Run this week’s security patches on all the environment:uat, application:banking, role:apiserver, flavor:rest servers.” Once you verify, you can do the same on environment:prod.”
“The second of the three servers in that autoscaling group is locked up. Terminate environment:uat, application:banking, role:apiserver, flavor:rest, instance:2“
“We seem to be having memory problems on the apiservers. Is it one or all of the boxes? Check the average of environment:prod, application:banking, role:apiserver, flavor:rest and then also show it broken down by instance tag. It’s high on just some of the servers but not all? Try flavor:rest vs flavor:soap to see if it’s dependent on that functionality. Is it load do you think? Compare to the aggregate of environment:uat to see if it’s the same in an idle system.”
“Set up an alert for any environment:prod server that goes down. And one for any environment:prod, application:banking, role:apiserver that throws 500 errors.”
“Security demands we check all our DB servers for a new vulnerability. Try sending this curl payload to all role:dbservers, doesn’t matter what application. They say it won’t hurt anything but do it to environment:uat before environment:prod for safety.”
So now a random new operator gets an alert about a system outage and logs into the AWS console and sees not just “i-123456 started 2 days ago,” they see
That operator now has a huge amount of information to contextualize their work, that at best they’d have to go look up in docs or systems and at worst they’d have to just start serially spamming. They know who owns it, what generates it, what it does and has hints at how important it is. (prod – probably important. A duplicate read secondary – could be worse.) And then runbooks can be very crisp about what to do in what situation by also using the tags. “If the server is environment:prod then you must initiate an incident <here>… If the server is a role:dbserver and a role:read-only it is OK to terminate it and bring up a new one but then you have to go run runbook <X> and run job <y> to set it up as a read secondary…”
Feel free and let me know how you use tags and what you can’t live without!
Hey all! James and I are preparing to revise our LinkedIn Learning course, DevOps Foundations, a three hour set of videos designed to orient beginners in the whole scope of DevOps.
We created the course in 2016 primarily because at the time there were no good introductions to DevOps. You needed to know what blogs to follow and what events to go to and that was it. Even the DevOps Handbook hadn’t come out yet. And this provided a very high barrier to entry to the field. And we believe in learning and collaboration so we knew what we had to do!
Since then, it’s been one of the top tech courses on LinkedIn Learning with over 400,000 learners so far and has generated a dozen other courses drilling down into detail in specific areas. The things that make it worth it to me is the people we run across who say “this helped me improve my career.” My favorite was one gentleman who pulled me aside at the Aqua Security booth at RSA back before the pandemic and said “Hey, I had just gotten out of the Army and was trying to get a good job, and so was looking at tech. Your course oriented me enough that I got a sales job here!” Being able to help people like that is a rare privilege and we really value it.
Please fill out our survey to let us know what you think are the key things someone needs to learn about DevOps – whether they have some existing dev or ops knowledge or are just getting into it!
Here’s the old table of contents for reference… A lot of this hasn’t changed, the basics are still the basics, but it has been 7 years and a lot has changed, some things to add, some things to change, some things to cut. Let us know your opinion!
DevOps Basics
What Is DevOps? – Understand the meaning of DevOps and why you might care about it.
DevOps Core Values: CAMS – Culture, Automation, Measurement, and Sharing are the core values of DevOps.
DevOps Principles: The Three Ways – The Three Ways can guide your strategic approach to DevOps.
Your DevOps Playbook – There’s a developing list of patterns and methodologies that can help you transition to DevOps.
Ten Practices for DevOps Success: 10 through 6 – Tactical, pragmatic tips for DevOps success in your organization
Ten Practices for DevOps Success: 5 through 1 – Tactical, pragmatic tips for DevOps success in your organization
DevOps Tools – the Cart Or The Horse? – The role of tools in DevOps and tips for selecting and using tooling to achieve your end goal.
DevOps: A Culture Problem
The IT Crowd and the Coming Storm – Existing IT culture has both internal and external problems. Meanwhile, new challenges of scale and business cadence are pressing technology departments to change.
Use Your Words – Communication is the key to collaboration and solving problems when the stakes are high.
Do Unto Others – Build trust and respect and eliminate blame and hostility in your teams.
Throwing Things Over Walls – Break down the silos and establish a culture of responsibility and ownership, and align your teams to support the flow of concept to cash.
Kaizen: Continuous Improvement – Everything can be iterated upon to make it better – even yourself!
The Building Blocks of DevOps
DevOps Building Block: Agile – DevOps extends Agile principles to include deployment and operations.
DevOps Building Block: Lean – Understanding Lean can be the difference between a DevOps implementation that helps you achieve your company’s goals and one that’s just “the same but different.”
ITIL, ITSM, and the SDLC – Where does the “old school” fit in to a DevOps world?
Infrastructure Automation
Infrastructure As Code – Take a fundamentally different approach to building distributed systems whether in the datacenter or in the cloud.
Golden Image to Foil Ball – Learn about configuration mangement, automated provisioning, deployment and orchestration.
Immutable Deployment – With the rise of containers, different CM patterns are gaining currency.
Your Infrastructure Toolchain – Common tools in this space include Chef, Puppet, and Ansible but new container-based approaches like docker are on the rise. [Yes, this was before terraform and kubernetes, definitely places to update]
Continuous Delivery
Small + Fast = Better – Delivering small batches of change quickly reduces risk, improves quality, and restricts technical debt.
Continuous Integration Practices – Learn about Continuous Integration, Delivery, and Deployment, which you need and how to get there.
The Continuous Delivery Pipeline
The Role Of QA – Move from manual testing to automated with Test Driven Development (TDD) and Behavior Driven Development (BDD).
Your CI Toolchain – From Github to Jenkins, your code pipeline consists of many different parts with specific functions.
Reliability Engineering
Engineering Doesn’t End With Deployment – If you build it, you run it and other patterns for reliability engineering.
Design For Operation – Theory – Building a system to be resilient is the highest leverage step in ensuring high uptime and low MTTR.
Design For Operation – Practice – Ops has learned hard lessons about resiliency over the years – take it into account when building your applications.
Operate For Design: Metrics and Monitoring – Operational support isn’t just keeping the systems up, it provides crucial feedback back into the development cycle. {Yes, the kids call this observability now]
Operate for Design: Logging
Your SRE Toolchain – Monitoring, troubleshooting, and metrics are a vital space in your tooling strategy.
Additional DevOps Resources
Unicorns, Horses, and Donkeys, Oh My – In an emerging discipline, going to events to learn from other expert practitioners is your fastest route to success.
Ten Best DevOps Books You Need to Read – There’s a growing number of books on DevOps, here’s our top 10 reading list.
Navigating The Series of Tubes – DevOps information on the Web is fragmented and hard to find sometimes; here’s some of the best places to watch.
The Future of DevOps
Cloud to Containers to Serverless – Profound changes to our computing model have arrived to challenge many of our established practices.
The Rugged Frontier of DevOps: Security – Security is changing and is rapidly uptaking the DevOps movement, we cover the major implications here. {Yes. the kids call this DevSecOps now]
Conclusion
Next Steps: Am I a DevOp now? – Learn what next steps you should pursue for growing in DevOps understanding and practice.
James and I were revising one of our LinkedIn Learning courses, DevOps Foundations: Infrastructure as Code to keep up with the times, and while we were out there filming we knocked out some new courses as well!
DevOps for Managers talks about DevOps from the management perspective. What do you need to know, and how can you best unlock the success of the teams you’re working with when they are – or want to – excel at DevOps?
DevOps Antipatterns explores some common pitfalls that people fall into when starting out (or, even, later…)
Check them out! For reference here’s our whole curriculum that the agile admins have put out to help you in your path to thriving in tech.
DevOps Foundations: Lean and Agile (Karthik, Ernest) – Lean and Agile inform DevOps at a fundamental level, and adopting their methods will contribute to your success.
James and I are working on a LinkedIn Learning course entitled “DevOps for Managers” and I wanted to share some of the books we love that we’ve found helpful in preparing it! We’d love to hear books you think are indispensable for DevOps managers. We’ve generally omitted general management books like First, Break All The Rules and DevOps non-management-specific books like Continuous Delivery, trying to focus on the specific intersection of tech and management.
The Lean Mindset: Ask The Right Questions by Mary and Tom Poppendieck shows how to focus your thoughts and iterate towards good products, including your internal products and services.
I’ve heard about Camille Fournier’s The Manager’s Path, Julie Zhuo’s The Making of a Manager, and Lara Hogan’s Resilient Management but haven’t read any of them yet so can’t vouch.
We also send out retrospective surveys to our attendees, speakers, sponsors, volunteers, and even our fellow organizers to find out how we’re doing and get an idea of what we should do better on (or keep doing) in the future!
To sum up, however, it’s looking good! Our last surveys were from 2019, from our last pre-pandemic DevOpsDays Austin, so we have a previous number to compare to.
Our attendee NPS was up to 77 (44 responses) from 62 (50 responses). And the things people loved were, basically, the personal interaction. Community, people, discussions, and openspaces were the most cited positives by far. We knew people had been missing that for a couple years now so our retrospective format and event plan were specifically designed to promote small group interactions.
The gripes were more varied. Primary was the food, which is fair enough. While we don’t intend to change from a boxed lunch format – it leaves so much more time for the actual conference, so we left fancy catered lunches behind long ago – we were forced to use the venue caterer and they ran out of food especially veggie options, and we had asked for breakfast tacos both mornings and on day two the breakfast was what I can only call “leftover meat bits.” So room for improvement, with the understanding that boxed lunches are here to stay, but we’ll definitely see what we can do about better options and especially making sure there’s not shortages of anyone’s dietary needs.
The other leading concern we’re just plain going to ignore, and here’s why. It was “the retro format – but what about technical talks, what about content for newbies?”
At DevOpsDays Austin we explicitly reject the assumption that all events must be the same generic thing every time. We specifically change our format every year. We’ve had the Monsters of DevOps where we went for flying in big keynoters (including all the authors of the DevOps Handbook) and doing everything up huge; we’ve had DevOps Unplugged where talks were voted in on site and there were no sponsor tables. This year we had a “class reunion” format with talks only being 20 minute “retrospectives” from what the speaker’s learned over their time in DevOps (some speakers were experienced, others were new voices). We very, very clearly talked about this format on our website, social media, and emails to attendees and sponsors. In the end, people just don’t read, and there’s nothing really to do about that. And we won’t be doing the retro format two years in a row, we’ll keep mixing it up!
Organizer feedback was good (we have 20 organizers), up slightly, with everyone enjoying working with the group, and some concerns about unclear roles and roles already taken. That’s always a challenge – we have a lot of organizers but not all of them are up to actually leading something. We have people volunteer to own roles and then encourage them to reach out to the others/the others to chip in when we need something, but that doesn’t always go well, which is frustrating for everyone. In the end, most roles need someone who can commit to consistent participation over the planning period (there’s a couple specialty roles like making signage that can be backloaded, but not many). But we want to be inclusive and not tell people “no, take the year off if you can’t be putting in a couple hours a week including making the organizer calls, and truly own something.” We’ve wrestled with this for 10 years, no clear answer is in sight.
Speakers love speaking at the event. NPS was 92, slightly up from 90 in 2019. They love the audience, how supportive and welcoming they are, and how low stress and chill the experience is. There’s always some AV issues as a fly in the ointment – we do AV checks but not everyone shows up for them.
Volunteers have a good experience too. NPS was 88, slightly down from 94 but still good; we try to make sure that the load isn’t too much on any given volunteer so they can also enjoy the event. Posting the openspace topics is always a challenge each year; we tweet out photos and then desperately type them into the sessionize, but a bunch of attendees are social media impaired I guess and it’s hard to get the schedule to everyone, but there’s not a lot of options given that openspaces are predicated on doing the agenda immediately previous; I’m not sure more time would help short of printing out copies or having live monitors everywhere.
Sponsor feedback was down from 60 to 50 NPS. They do like the audience and authentic content. The main problem was the new venue and unclear flow meant that the platinum sponsor rooms were more out of the way than we’d planned (we gave them tables in the gold area as well once this became clear). And then the general sponsor gripes about it not being a good lead gen event. We always tell sponsors this is a good participation event, not a good lead gen event, no badge scanners, no sponsor list, etc., but a previously mentioned people don’t read, plus the teams being sent out aren’t the people buying the sponsorships and often just assume they’ll be getting a standard conference experience. We sell out every year so I’ll worry about it when that stops.
There’s one other thing worth mentioning, which is that we did require masking at the event and asked people to either be vaccinated or test prior to the event.
One the one hand, a couple sponsors and attendees griped about the masking.
On the other hand, despite other events resulting in superspreading (Kubecon EU, RSA, even some DevOpsDays events):
So, with all due respect, we are very happy with our choice and that we had a safe event. No one likes wearing masks. If you don’t like it enough to not come – don’t come. Hopefully it won’t be necessary next year.
Everything was pretty good! There was one issue, though – in all the survey sub-questions, there was a drop in the perceived friendliness of the organizer team, so we’re going to make some changes there – stay tuned to hear what!
We were psyched to be back and meeting in person for DevOpsDays Austin 2022 this year! Charitable donation is a part of our Austin tech culture and very important to us, and since it was our 10th anniversary we aimed to hit a total of $100,000 in charitable donations since we started the event in 2012. And we did it! We’re happy to have $28,000 to give to local charities after our event this year.
That left us with the question of who to donate to. We like to choose things that fill the greatest need in our community at the time, and strongly bias towards supporting Austin area charities. Our state government decided to help us make our decision by starting a pogrom of discrimination against LGBTQ+ Texans.
Many of our colleagues in the Austin technology community are gay, lesbian, transgender, nonbinary, or identify with other nontraditional gender identities and sexual preferences, or have family members that are. I myself have a transgender son who I’ve loved and supported through his transition, and now he’s a happy, healthy adult. We find the attempts of the Texas government to institutionalize hostile behavior towards them deeply unacceptable and want to find ways to support them.
We looked initially at charities like Equality Texas that are working to ensure the rights of LGBTQ+ Texans, but as we discussed we wanted our funds to go directly to the benefit of people in need, and not all go to the lawyers fighting the long fight.
Since $28,000 is a lot, we decided to split it up into two $14,000 donations. After some research we nominated two recipients, Out Youth and The Trevor Project, and brought them to the DoDA organizer team for a vote, which they enthusiastically approved.
We selected Out Youth for our first donation as a deeply local Austin organization directly supporting LGBT youth.
For 32 years, Out Youth has supported Central Texas LGBTQIA+ youth and young adults by providing safe places where they are loved, acknowledged, and accepted for exactly who they are. Their life-saving and life-changing programs and services ensure these promising young people develop into happy, healthy, successful adults. Out Youth hosts a variety of programs to keep their youth mentally and physically safe such as drop-in times at their youth community center, by offering free individual counseling and group therapy sessions, and through their in-school-support services. To find out more information about ways to get involved and about their services, please visit outyouth.org today.
It’s funny that our relationships with these charities usually start with us showing up with a big surprise donation and then after that getting deeply involved with the organization; we plan to go tour their house and spread the word about volunteer opportunities with them to the Austin technology community.
Not only do I have a transgender son, but also fellow Agile Admin and conference organizer James lost a brother to suicide. So while The Trevor Project isn’t Austin based per se, it does help many Austinites, and its mission of suicide prevention among LGBTQ+ youth is deeply and personally meaningful to us both. Therefore we chose them for our second donation this year.
The Trevor Project has worked to save young lives by providing support through our free and confidential crisis programs on platforms where young people spend their time — online and on the phone: TrevorLifeline, TrevorChat and TrevorText. We also run TrevorSpace, the world’s largest safe space social networking site for LGBTQ youth, and operate innovative education, research, and advocacy programs.
The Trevor Project’s research has found that having at least one accepting adult in an LGBTQ young person’s life reduces their risk of suicide by 40%.
Transgender and nonbinary youth who reported having pronouns respected by all of the people they lived with attempted suicide at half the rate of those who did not have their pronouns respected by anyone with whom they lived.
“You are lovable” – this is one of the most common phrases The Trevor Project’s crisis counselors share with youth in crisis.
According to Trevor’s research 42% of LGBTQ youth seriously considered attempting suicide in the past year, including more than half of transgender and nonbinary youth.
You can sign up to become a volunteer counselor on their site; there’s extensive training and it requires a year commitment.
In closing, we appreciate the work Out Youth and The Trevor Project are doing and hope that others will look into finding ways to support them as well.
To the LBGTQ+ technologists in Austin, you are welcome, and both DevOpsDays Austin and other user groups we run like CloudAustin have published codes of conduct that don’t allow any hostile behavior towards you at our events, and we look forward to interacting with you there. Happy Pride Month!
DevOpsDays Austin believes in supporting the local community that supports us, the techies of Austin. As we’ve grown and we’ve been able to end some of our years with extra money from our sponsors. We are careful to be thrifty with the event and rely on our volunteers to do a lot, and all DevOpsDays events run on a nonprofit basis; one of the few core rules of all DevOpsDays is that the events are not for individual or corporate profit.
The Austin technical community is a cross-section of, and part of, our community. We have a diverse set of individuals from many backgrounds and neighborhoods all around the area. As technologists we are largely blessed with decent salaries and technology companies have lots of money, and many of the keenest needs in the area need relatively little funding to make a real difference. We believe it’s our responsibility as a part of the community to use part of what we make to give back to support the most vulnerable among us. Therefore we’ve made it a point to use our excess funds to give back to charities that directly help those most in need.
We started DevOpsDays Austin in 2012 from nothing, and relied on a free venue (courtesy of my employer at the time, National Instruments). We made enough to make a down payment on a venue in 2014, and by 2015 we were confident enough of our finances that we considered our first charitable donation.
The Charity Page In Our 2022 Yearbook
The natural choice was the Central Texas Food Bank (at the time, known as the Capital Area Food Bank), a well known long time Austin charity that combats hunger in the area. We gave $5000, and we also did a charity drive at the event, handing out leftover t-shirts and swag from the previous two years to those who made a donation of their own, which sent another $2600 to the food bank.
In 2016 we moved to a new, larger, much more expensive venue (the Darrell K. Royal Texas Memorial Stadium out at UT Austin) so we could let more people attend DevOpsDays. That put us at the limit of our finances for a couple years, especially with our 2017 “Monsters of DevOps” blowout conference with many international speakers and great fun events. But by 2018 we had that venue dialed in as well and had $20,000 left over that we decided to donate to charity. That year, instead of sending all the donation to one charity, we let each of our 20 organizers send $1000 to a charity of their choice. This ended up driving our helpful accountant Laura at ConferenceOps batty trying to get proper tax receipts from everyone, however, and we promised her we wouldn’t do that again.
Then in 2019 we had a great event, sponsors were in a right frenzy to get in and we had to add more sponsor booths to accommodate them – which was a lot of work, but left us also with a lot of leftover money ($25,000, off a conference with only a $200k total budget). We weren’t sure how we could be the most effective with a gift like this, and one of our organizers said “Did you know… There’s a new project here in Austin that builds miniature houses for the homeless in a beautiful community?” And that’s how we were introduced to the Community First! Village, a quickly growing and very effective outgrowth of Mobile Loaves and Fishes to house the homeless. And it turns out $25,000 is exactly how much it takes to build one of those homes. Our organizers enthusiastically approved the donation and we went out and did a great tour of the site, and many of us have returned as volunteers since.
And then the hard times came. During the pandemic, DevOpsDays Austin was on ice. In fact, we had planned on moving to an even more expensive hotel venue and had a down payment in place when the lockdown came, and we had to get a lawyer into play to get our deposit back.
But the needs of the community weren’t on hold. We have many Black and brown technologists in our community, and the high profile brutality directed at them was completely unacceptable. Long time friend of DevOpsDays Austin, John Wills, started a fundraiser for Black Lives Matter around making a quilt with all his DevOpsDays shirts (many of which were from Austin) in 2020, and we felt compelled to donate $2000 of the more than $12,000 he raised.
DevOpsDays Shirt Quilt
Then we were in the long night of lockdown. We weren’t doing anything from a DevOpsDays Austin perspective in 2021, though there was a virtual DevOpsDays Texas conference to fill in some of the gap. But as jobs and aid dried up, hunger became a critical need again in Austin. Fellow organizer Boyd Hemphill encouraged people to help out and volunteer during a virtual meetup, and his words made my conscience burn till I brought it to my fellow DevOpsDays Austin organizers to see if we could dip into our reserves and help. They all enthusiastically approved a $10,000 donation to our old friends the Central Texas Food Bank again.
Two donations without any revenue, that’s good enough till we can have an event again, right? Well, you’d think, and then Russia went and invaded Ukraine.
While we’re an Austin organization and we’ve always given to help out in Austin directly, we have many Ukrainians as part of our local tech community. I worked with many of them hand in hand while I was running teams at Bazaarvoice, as we had a great relationship with the Ukrainian consulting company Softserve. We brought many of them here to Austin to work with us, we went out together, I had toasted them with “Slava Ukraini!” Many of our organizers had similar experiences. And since we don’t like bullies around here, that riled us up. After a discussion along the lines of “well, we started from nothing once, we can do it again if we have to,” we donated $10,000 to Ukrainian relief organizations Razom for Ukraine and Nova Ukraine.
And that brings us up to date with the past, but we finally managed to have DevOpsDays Austin again! In May, we got a great venue (the University of Texas Alumni Center, at half price courtesy of Bill our venue lead being an UT alum) and planned for a slightly smaller than usual (350 masked attendees, to hedge against super-spreading) conference on our 10 year anniversary – the DevOpsDays Austin 10 Year Class Reunion.
Since it was our 10th anniversary, we did a yearbook. And when I put the charitable donation page together for the yearbook, I realized we’d given $72,000 to charity over the years. 10 years and an even $100,000 sounded mighty nice.
The conference went great, and all those sponsors have been saving up their marketing money wondering what to do with it. After some laborious running of numbers I realized we could free up the $28,000 donation to get to that bar and leave enough for us to make a venue down payment the next year.
As we contemplated this year’s donation our Texas state government decided to openly attack the LGBT+ citizens of our state. Many of those in our technical community we meet with every month in user groups are gay, lesbian, transgender, binary, and so on, and this is a direct attack on many of our coworkers, colleagues, and friends. And not just them, but their children.
As a result we gave $14,000 to The Trevor Project, a national service that provides suicide prevention hotlines for LGBT+ youth, $14,000 to Out Austin, a local place for youth of all sexual orientations and gender identities. I’ll write a separate post about those organizations and why them, and more importantly how you can help.
But in the end we’ve been very happy that we’ve been able to use our position as techies in the tech hotspot of Austin to consistently give back. We’d challenge other conferences, tech companies, and individual technologists to do so as well – especially to reputable charities that directly help those who need it.
I hope that DevOpsDays Austin can continue to give back in this way over the next ten years too!
Well, we had to skip 2 years in a row due to the pandemic, but we were finally able to have DevOpsDays Austin in person again in 2022! It’s our tenth anniversary of DoD Austin, we had the first one at National Instruments back in 2012, one of the early DevOpsDays in the US.
We had to move to a new venue, and used the beautiful University of Texas Etter-Harbin Alumni Center (our site lead Bill is a UT alum which makes it half price!). The Etter-Harbin Center is right across from the stadium where we had DoDA in the years leading up to the hiatus. It has plenty of great outdoor spaces, which we used for lunches and happy hours, as well as a great main ballroom with views of the outside. It worked great for our target of 350 attendees, and we think we could make it work for more in the future.
Etter-Harbin Alumni Center
We were thinking and came across the perfect theme – it’s our tenth anniversary, and we’re just back from the pandemic, and DevOps is also just a little more than ten years old and at a weird inflection point that has people asking “is DevOps dead? Where does DevOps go from here?” So we decided that since we were also in the Alumni Center, the obvious theme was our 10 Year Class Reunion!
We don’t take our themes lightly at DevOpsDays Austin. We settled on a new theme for our talks – instead of the normal RFC for whatever technical and culture topics, we required all talks to be a retrospective format – reflecting on what you’ve learned over the years of DevOps and what you think the future holds. We had lots of great speakers, many of whom are long time parts of the DoD Austin community, both locals like Rob Hirschfeld, Christa Meck, Ross Dickey, and Victor Trac, as well as folks from other parts of the Earth like Patrick Debois, Damon Edwards, J. Paul Reed, Pete Cheslock, and Michael Cote, who all frequently come to Austin to share with us.
And we printed a yearbook, with pics of speakers from all the events, our tshirts over the years, and more! Very snazzy, and we had people sign each others’ yearbooks to add some fun to the hallway track. In fact, you can view the yearbook online and buy a hardcopy here if you want!
The DevOpsDays 2022 Yearbook
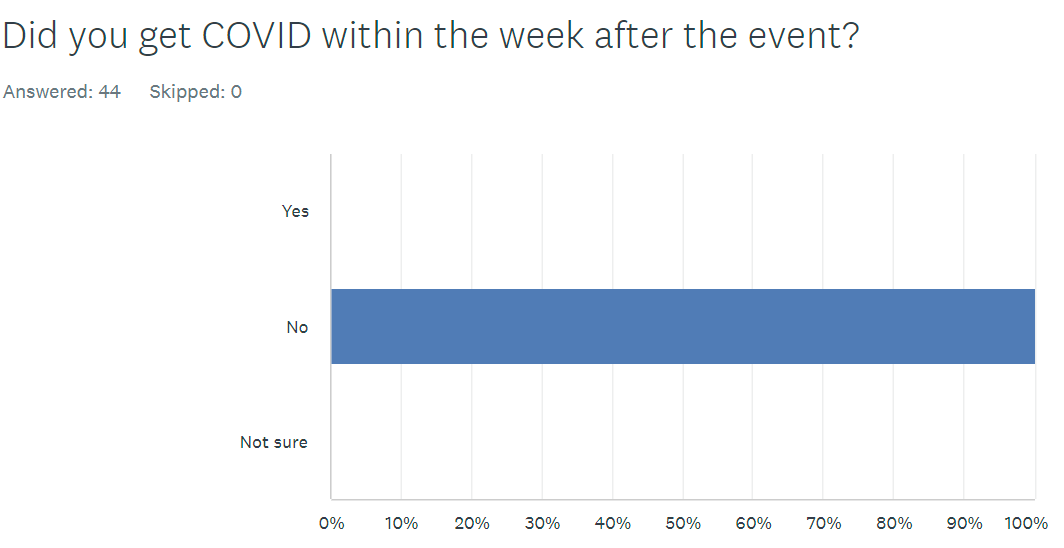
We did require COVID protocols – masking inside and (honor system) vaccine or test, and while it is a bummer to not see each others’ faces, it also resulted in only one person I know of getting COVID the week after, so well worth it.
We didn’t have to worry about sponsor interest! We sold out quickly. Here’s the ones I got snaps of!
Our Sponsors
Everything went great, and it was super to finally get back together and interact with our local DevOps community. J. Paul Reed led a great session where a retro was done on DevOps in general!
And one of the best things is that we managed to carry on our tradition of giving our excess proceeds to charity! I’ll do a separate post on that, but the short form is that we contributed $28,000 to LGBT-supporting charities, half to The Trevor Project and half to Out Youth here in Austin, bringing us to $100,000 given to charity over our 10 years in existence! Stay tuned for more details on that…