
Welcome to the newest article in Scrum for Operations. I started this series when I was working for NI. But now I’m going through the same process at BV so time to pick it back up again! Like my previous post on Speeding Up Releases, I’m going to go light on theory and heavy on the details, good and bad, of how exactly we implemented Agile and DevOps and where we are with it.
Here at BV (Bazaarvoice), the org had adopted Agile wholesale just a couple months before I started. We also adopted DevOps shortly after I joined by embedding ops folks in the product teams. Before the Agile/DevOps implementation there was a traditional organization consisting of many dev teams and one ops team, with all the bottlenecking and siloing and stuff that’s traditional in that kind of setup. Newer teams (often made up of newly hired engineers, since we were growing quickly) that started out on the new DevOps model picked it up fine, but in at least one case we had a lot of culture change to do with an existing team.
Our primary large legacy team is called the PRR team (Product Ratings and Reviews) after the name of their product, which now does lots more than just ratings and reviews, but naturally marketing rebranding does little to change what all the engineers know an app is called. Many of the teams working on emerging greenfield products that were still in development had just one embedded ops engineer, but on our primary production software stack, we had a bunch. PRR serves content into many Internet retailer’s pages; 450 million people see our reviews and such. So for us scalability, performance, monitoring, etc. aren’t a sideline, they’re at least half of the work of an engineering team!
This had previously been cast as “a separate PRR operations team.” The devs were used to tossing things over the wall to ops and punting on the responsibility even if it was their product, and the ops were used to a mix of firefighting and doing whatever they wanted when not doing manual work the devs probably should have automated.
I started at BV as Release Manager, but after we got our releases in hand, I was asked to move over to lead the PRR team and take all these guys and achieve a couple major goals, so I dug in.
Moving Ops to Agile
I actually started implementing Agile with the PRR Ops team because I managed just them for a couple months before being given ownership of the whole department. I had worked closely with many of them before in my release manager role so I knew how they did things already. The Ops team consisted of 15 engineers, 2/3 of which were in Ukraine, outsourced contractors from our partner Softserve.
At start, there was no real team process. There were tickets in JIRA and some bigger things that were lightly project managed. There was frustration with Austin management about the outsourcers’ performance, but I saw that there was not a lot of communication between the two parts of the team. “A lot of what’s going bad is our fault and we can fix it,” I told my boss.
Standups
A the first process improvement step, I introduced daily standups (in Sep 2012). These were made more complicated by the fact that we have half of our large team in Ukraine; as a result we used Webex to conduct them. “Let’s do one Austin standup and one Ukraine standup” was suggested – but I vetoed that since many of the key problems we were facing were specifically because of poor communication between Austin and Ukraine. After the initial adjustment period, everyone saw the value of the visibility it was giving us and it became self-sustaining. (With any of these changes, you just have to explain the value and then make them do it a little while “as a pilot” to get it rolling. Once they see how it works in practice and realize the value it’s bringing, the team internalizes it and you’re ready for the next step.) Also because of the large size and international distribution I did the “no-no” of writing up the standup and sending the notes out in email. It wasn’t really that hard, here’s an example standup email from early on:
Subject: PRR Infrastructure Daily Standup Notes 11/05/2012
Individual Standups
(what you did since last standup, what you will do by the next standup, blockers if any)Alexander C – did: AVI-93 dev deploy testing of c2, release activity training; will do: finish dev c2, start other clusters
Anton P – did: review AVI-271 sharded solr in AWS proxy, AVI-282 migrating AWS to solr sharding; will do: finish and test
Bryan D – did: Hosted SEO 2.0 discussion may require Akamai SSL, Tim’s puppet/vserver training, DOS-2149 BA upgrade problems, document surgical deploy safety, HOST-71 lab2 ssh timeout, AVI-790, 793 lab monitoring, nexus errors; will do: finish prep Magpie retro, PRR sprint planning, Akamai tickets for hosted SEO, backlog task creation.
Larry B – did: MONO-107,109 7.3 release branch cut, release training; will do: AVI-311 dereg in DNS (maybe monitoring too?)
Lev P – did: deploy script change testing AVI-771; will do: more of that
Oleg K – did: review AVI-676 changes, investigate deployment runbooks/scripts for solr sharding AVI-773; to do: testing that, AVI-774 new solr slaves
Oleksandr M – did: out Friday after taking solr sharding live; will do: prod cleanup AVI-768, search_engine.xml AVI-594
Oleksandr Y – did: AVI-789 BF monitoring, had to fix PDX2 zabbix; will do: finish it and move to AVI-585 visualization
Robby M – did: testing AVI-676 and communicating about AWS sharding; will do: work with Alex and do AVI-698 c7 db patches for solr sharding
Sergii V – did: AVI-703 histograms, AVI-763 combining graphs; will do: continue that and close AVI-781 metrics deck
Serhiy S – did: tested aws solr puppet config AVI-271, CMOD stuff AVI-798, AVI-234
Taras U – did: tested BVC-126599 data deletion. Will do: pick up more tickets for testing
Taras Y – did: AVI-776 black Friday scale up plan, AVI-762 testing BF scale up; will do: more scale up testing
Vasyl B – did: MONO-94 GTM automation to test; will do: AVI-770 ftp/zabbix thing
Artur P – did: AVI-234 remove altstg environment, AVI-86 zabbix monitoring of db performance “mikumi”; will do: more on those
For context, while this was going on we were planning for Black Friday (BF) and executing on a large project to shard our Solr indexes for scaling purposes. The standup itself brought loads of visibility to both sides of the team and having the emails brought a lot of visibility to managers and stakeholders too. It also helped us manage what all the outsourcers were doing (I’ll be honest, before that sometimes we didn’t know what a given guy in Ukraine was doing that week – we’d get reports in code later on, but…).
I took the notes in the standup straight into an email and it didn’t really slow us down (I cheated by having the JIRA project up so I could copy over the ticket numbers). Because of the number of people, the Webex, and the language barrier the standups took 30 minutes. Not the fastest, but not bad.
Backlog
After everyone got used to the standups, I introduced a backlog (maybe 2 weeks after we started the standups). We had JIRA tickets with priorities before, but I added a Greenhopper Scrum style backlog. Everyone got the value of that immediately, since “we have 200 P2 tickets!” is obviously Orwellian at best. When stakeholders (my boss, other folks) had opinions on priorities we were able to bring up the stack-ranked backlog and have a very clear discussion about what it was more or less urgent/important than. (Yes, there were a couple yelling matches about “it’s meaningless to have five ‘top priorities!'” before we had this.) Interrupt tickets would just come in at the top.
Here’s a clip of our backlog just to get the gist of it…
 All the usual work… just in a list. “Work it from the top!” We still had people cherry-picking things from farther down because “I usually work on builds” or “I usually work on metrics” but I evangelized not doing that.
All the usual work… just in a list. “Work it from the top!” We still had people cherry-picking things from farther down because “I usually work on builds” or “I usually work on metrics” but I evangelized not doing that.
Swimlanes
Using this format also gave me insight into who was doing what via the swimlanes view in JIRA. When we’d do the standup we started going down in swimlane order and I could ask “why I don’t see that ticket” or see other warning signs like lots of work in progress. An example swimlane:
This helped engineers focus on what they were supposed to be doing, and encouraged them to put interrupts into the queue instead of thrashing around.
Sprints
Once we had the backlog, it was time to start sprinting! We had our first sprint planning meeting in October and I explained the process. They actually wanted to start with one week sprints, which was interesting – in the dev world often times you start in with really long (4-6 week) sprints and try to get them shorter as you get more mature. In the ops world, since things are faster paced, we actually started at a week and then lengthened it out later once we got used to it.
The main issue that troubled people was the conjunction of “interrupt” tickets with proactive implementation tickets. This kind of work is why lots of people like to say “Ops should use kanban.”
However, I learned two things doing all this. The first is that for our team at least, the lion’s share of the work was proactive, not reactive, especially if you use a 1-2 week lookahead. “Do they really need that NOW, or just by next sprint?” Work that used to look interrupt driven under a “chaos plus big projects” process started to look plannable. That helped us control the thrash of “here’s a new urgent request” and resist it breaking the current sprint where possible.
Also, the amount of interrupt work varies from day to day but not significantly for a large team over a 1-2 week period. This means that after a couple sprints, people could reliably predict how many points of stories they could pull because they knew how much time got pulled to interrupt work on average. This was the biggest fear of the team in doing sprint planning – that interrupt work would make it impossible to plan – and there was no way to bust through it except for me to insist that we do a couple sprints and reevaluate. Once we’d done some, and people learned to estimate, they got comfortable with it and we’ve been scrumming away since.
And the third thing – kanban is harder to do correctly than Scrum. Scrum enforces some structure. I’ve seen a lot of teams that “use kanban” and by that they mean “they do whatever comes to mind, in a completely uncontrolled manner,” indistinguishable from how Ops used to do things. Real kanban is subtle and powerful, and requires a good bit of high level understanding to do correctly. Having a structure helped teach my team how to be agile – they may be ready for kanban in another 6 months or so, perhaps, but right now some guard rails while they learn a lot of other best practices are serving us well.
Poker Planning
After the traditional explanation (several times) about what story points are, people started to get it. We used planningpoker.com for the actual voting – it’s a bit buggy but free, and since sprint planning was also 15 people on both (or more) sides of a Webex, it was invaluable.
Velocity
It’s hard to argue with success. We watched the team velocity, and it basically doubled sprint to sprint for the first 4 sprints; by the end of November we were hitting 150 story points per sprint. I wish I had a screen cap of the velocity from those original sprints; Greenhopper is a little cussed and refuses to show you more than 7 sprints back, but it was impressive and everyone got to see how much more work they were completing (as opposed to ‘doing’). I do have one interesting one though:
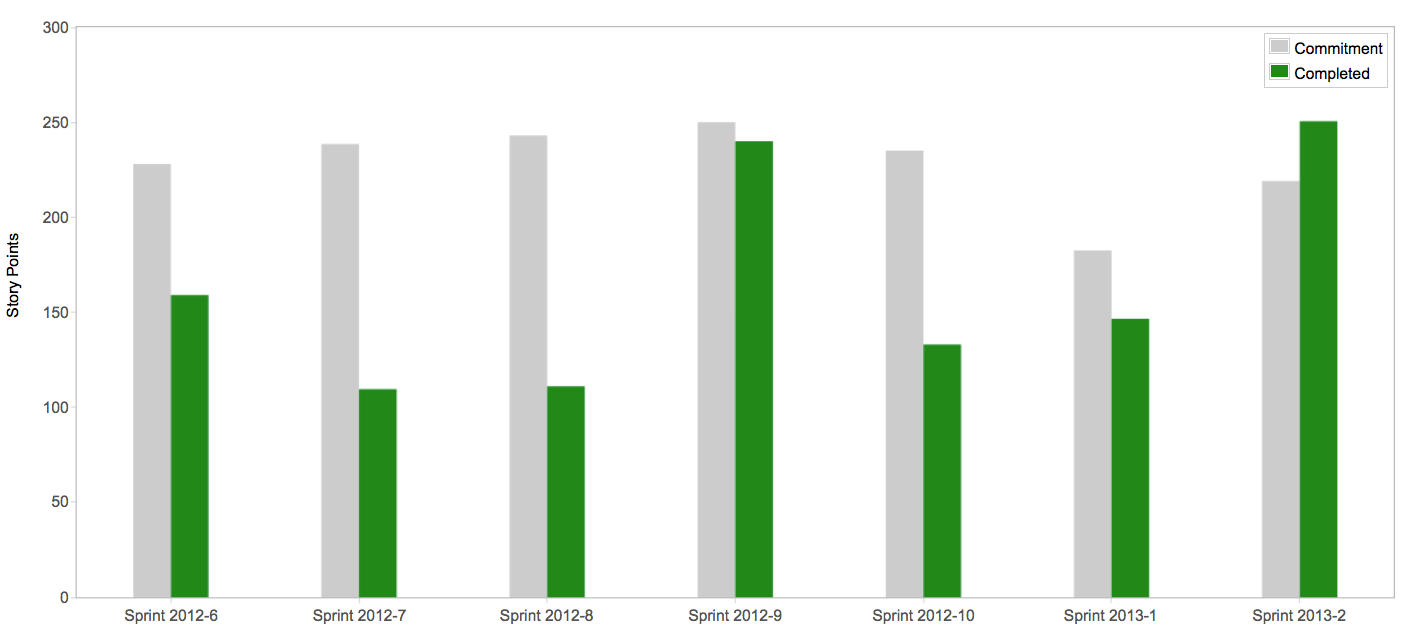 This is our 6th and following sprints; you see how our average velocity was still increasing (a bit spikily) but in that last sprint we finally got to where we weren’t overpromising and underdelivering, which was an important milestone I congratulated the team on. Nowadays their committed/completed numbers are always very close, which is a sign of maturity.
This is our 6th and following sprints; you see how our average velocity was still increasing (a bit spikily) but in that last sprint we finally got to where we weren’t overpromising and underdelivering, which was an important milestone I congratulated the team on. Nowadays their committed/completed numbers are always very close, which is a sign of maturity.
Just Add Devs – False Start!
After the holiday rush, they asked me and another manager, Kelly, to take over the dev side of PRR as well, so we had the whole ball of wax (doubling the number of people I was managing). We tried to move them straight to full Scrum and also DevOps the team up using the embedded ops engineer model we were using on the other 2.0 teams. PRR is big enough there were enough people for four subteams, so we divided up the group into four sprint teams, assigned a couple ops engineers to each one, and said “Go!”.
This went over pretty much like a lead balloon. It was too much change too fast. Most of the developers were not used to Agile, and trying to mentor four teams at once was difficult. Combined with that was the fact that most of the ops staff was remote in Ukraine, what happened was each Austin-BV-employee-led team didn’t really consider “those ops guys” part of their team (I look around from my desk and see four other devs but don’t see the ops people… Therefore they’re not on my team.) And that ops team was used to working as one team and they didn’t really segment themselves along those lines meaningfully either. Since they were mostly remote, it was hard to break that habit. We tried to manage that for a little while, but finally we had to step back and try again.
Check back soon for Scrum for Operations: Just Add DevOps, where I reveal how we got Agile and DevOps to work for us after all!

Thanks for sharing your experience on applying Agile to Ops! I’m looking forward to the follow-on post on how you got it to work for DevOps.
Are you using the latest Greenhopper plug-in for Jira? It’s been awhile since I used Greenhopper and it looks like the latest updates have made it a much more useful tool.
Thanks! Semi latest I think; Jira 5.2 and Greenhopper 6.1.6. I think JIRA 6 and Greenhopper 6.2 are the latest ATM. It’s pretty handy, definitely has some things you have to get used to but a super useful tool.
Hi Ernest,
Thanks for sharing this real life story, it helped me a lot in understanding how to truly integrate the dev and ops teams.
One question:
Did you end up by embedding all ops guys into the dev teams or was there still a dedicated/cross-functional ops team left?
It makes a lot of sense for me to integrate “application support” people into the dev teams, as they are focused on one business domain anyway. But would you also embed more infrastructure-minded people (network, storage, UNIX sysadmins, …)? Their value is in their deep knowledge of a cross-functional domain so there it may make less sense.
Niek.
A good question. We completely distributed all technical specialties and here’s why. Each team should be providing a service, in an ITSM sense. So we have a service team that runs our main user generated data store. They have some devs and some data experts (it’s Cassandra so I don’t say DBA, but same deal). We have other teams like our team that runs a Hadoop cluster that has a lot of Hadoop experts along with their programmers. But they are joined in responsibility for providing a service. I have to say, most of my experience with “technology specialist teams” has been largely hateful. I’ve often found them to have no interest in understanding the business drivers or application needs and simply are the Keepers of the Temple. In my previous Web ops gig, the worst roadblocks to getting work done wasn’t the “business” or even the “devs,” it was those other infrastructure teams.
In each of our teams there’s software engineers (devs) and devops engineers (ops). Some of those have dba skill sets, pretty much all of them have unix admin skill sets, a couple have network skill sets. Note I don’t say “some of the devops,” as we have software engineers with those skills as well. If one team has a network expert and someone else needs some more-expert networking guidance, they just ask for some help. Asking a peer product team for help is oddly more effective than asking the “centralized technology specialists” for help – those often have forgotten how to talk to those outside the priesthood.
You don’t have a team of “Java developers” or even more rarefied “Scala developers” or “UI developers.” (At least probably…) You put the programmers with the skills you need in the places you need them. Doing differently for infrastructure technologies is only done for invalid historical reasons, and cheapness (well certainly we can’t hire 10 sysadmins for 10 product teams, it’d be more “efficient” to have three!). People do this and then complain about the “ops bottleneck…” “Doctor, it hurts when I do this!” Well – don’t do that. It comes from the culture of “infrastructure is IT” and “IT is a cost center” and all that 1980s junk.
We put on each team the people they need – programmers of various stripes, people with UNIX, cloud, networking, data/nosql, whatever. Then those teams are free to innovate and produce without blockers, generating a huge amount of additional productivity. We also compensate by being very selective in our hiring, and have a reasonable expectation that our engineers can pick up a technical skill they don’t have. So many people running a mySQL database aren’t dedicated “DBAs,” they are an engineer that also has that skill. Siloed teams keep the knowledge inside them, this practice distributes it widely making for fewer bottlenecks.
I’ll be honest, we are a little short on ops folks right now and we have like 3 teams without an embedded one, and they all desperately want one because they have come to see what a force multiplier it is to their productivity. (Send me your resumes!)
Now, I don’t want to give a false impression by not listing the two down sides we do have from this scheme.
First, we did have all the ops folks embedded but reporting to a separate ops manager. We since have completely embedded them into the teams. This has caused some problems because not all software dev managers know anything about operations or how to attract, retain, or develop operations professionals. We had planned to address this with cross-cutting internal SIGs but we never seem to have time for that.
Second, not every developer is on board with this. We have a couple that, I’ll be honest, cop a bit of an attitude and look down on the “non-coders” regardless of how much technical expertise they have in UNIX/DBA/etc (because of course to some developers, everything they don’t do must be easy). That’s just a continuing personnel/culture management issue; with DevOps as with Agile you have people that find it difficult to respect people of different specialties that need coaching.
So I’m not saying “you shouldn’t” have dedicated technology silo teams – I just know that I wouldn’t want to go back to work for a place that does.
Because in the end… What are you supposed to be doing other than ‘application’ support? Application is a code word for “things people want to use those systems they spent a lot of the company’s money on to do.” A siloed infrastructure team might be able to work if they broke out of the typical mindset. I grew to really dislike some of those teams who support ‘the database’ for its own sake or ‘the UNIX systems’ for their own sake – to the degree that you couldn’t actually use those systems and databases to accomplish business goals. IF they were super aligned with the real business goals and IF they were super collaboration oriented, maybe not fully embedded but at least having reps for each client team that they go spend significant time with – but I have yet to hear from anyone who’s doing that well.
Super interesting!
I have a background in traditional enterprise IT environments so I know what you mean with these siloed infrastructure teams.
So if I understand well, the main reason for embedding ops people in the dev teams is not to optimize the communication lines (domain knowledge vs technical knowledge) but rather to avoid a dependency on a non-responsive infrastructure service?
I hear a lot of good stuff about the organizations that have cut their business processes in many atomic business services, an approach where teams become smaller and more decoupled but that still relies on dependencies between teams. So here one particular team will not need the services from the UNIX team, but from the “user management” team.
Thinking about it I don’t really see a huge difference between both types of teams: somehow they should both be motivated to provide a decent service to the other teams.
Curious to get your view on this.
Thanks,
Niek.
Oh, the main reason is still optimizing communication, but there are many other benefits including removing blockers. As we went to our distributed service team scheme, there are a couple subtleties about it, including what’s an acceptable service (service-washing a tech group is no help). “User management” is on the line, “We provide builds” is over it on the bad side – but at least if the team understands they’re providing a service to someone it’s a step forward from the common case. Also you’ll want to mix devs and ops there too; most ops teams work with horrible tools. In fact, related to your user management example, here at BV the engineering team was managing LDAP which all the product stuff uses while IT was managing AD for internal use. We merged them into one user management thing but we put dev resources onto writing non-junk tooling and integration for all of it – add once, common groups, hook to HR system for deprovisions, etc. Part of the adding dev to ops in devops is to eliminate manual work.
We do have a central tooling team, “cloud infrastructure,” that develops Netflix-like tooling for the other teams to use. Some of those are services but they’re delivered in self-serve manner as much as possible, and all the other teams are coached that they should not block on them and the interfaces should be loosely coupled so teams can release independently. If some platform team doesn’t have what you need yet, you do it yourself or do without. So no one’s sitting around waiting for that team to come up with a common deploy solution before they can deploy their code – that’s not there yet so they DIY. Other teams check in code to our code base, for example, if it’s not high enough on our backlog for us to do in a timely manner and they need it because we’re integrated. This does mean we don’t have a lot of up front standardization, but in reality lead solutions emerge and the technical leads converge on them. And the agility is more than worth it; shipping early and then refactoring to get more standardization is hugely preferable to shipping real late but all standardized, given the theory that your business exists to make money not to worship the god of standards.
This all makes a lot of sense indeed, although I still see value in more general usages of technical services/teams, given that they provide a good service. One way of getting there could be to make the service optional for the other teams. In that sense the technical team has to “earn” their clients. If no-one uses them then it’s time to abandon them.
I have seen new dev teams getting up to speed very quickly by simply re-using the existing infrastructure (assuming that they don’t have any particular needs that are not supported yet).
So maybe it’s a decision that the team has to make for each particular case, weighing between the effort it would take to in-source the knowledge, build and maintenance on one side and the quality of the shared service on the other side.
Sure, and everyone should do what works for them – what *really* works. Too many places accept crap results and think “it’s working” because it’s the historical way of doing it though; I think through DevOps we’re seeing huge value from breaking those old patterns. When I was at NI I went from running a WebOps team in a siloed infrastructure org to a greenfield “do everything yourself” org and we surpassed the results of the old way insanely quickly. The devs on our team just couldn’t believe the night and day. I remember in fact one time Karthik needed to change a http to a https call in his code. He needed to change it on our side and on the Oracle ERP side managed by IT. Time for our change: 5 minutes, I showed him where to change it in source control. Time for the other change: 2 weeks of phone calls explaining, begging, pleading the DBAs to make it. Afterwards he came to us and said “You guys are always babbling about DevOps and I wasn’t really sure why but now I get it.”
I do think the “earn it” approach makes sense. Team budgets should be under their control, and if it works better for them to spend one of their engineer slots on a DBA then great. (I begged for our own DBA on that WebOps team for years… “We can’t do that, it’ll irritate the DBAs” was the Orwellian reason why it was always declined.) If the central team earns their usage then that’s cool too. In fact that’s pretty much how we’re doing our platform teams; if people don’t like the Cloud Infra team’s monitoring solution they can use their own, etc.
But in the end, people have been trying to make the technical silo team approach work in Infrastructure for 30 years and it NEVER does. Everyone in it hates it, gets early ulcers and divorces and so on. Five or so years ago, ask any gathering of ops guys “who loves their job?” and they’d all just look at you like you were slow or insane. But the same wasn’t true with devs, was it? They’re going home at 5, having a beer, enjoying the creative aspect of their work… Some of my personal call to DevOps was frankly liberation of beaten down Ops folks from that legacy of pain. That’s why I’m passionate about it. So yes, the old model “can” work but it’s like communism – sounds great, for some reason implementations always turn out hateful. Consider whether making the better buggy-whip is worth the effort. I banged my head against the problem of trying to make ops exceptional for a decade with tools, process, etc. before realizing maybe I just had a bad approach that I could optimize till the cows came home and it’d still be bad.
Good discussion, thanks for talking with me!
Oh hey and if you haven’t read this previous post on this topic, check it out… https://theagileadmin.com/2010/03/12/before-devops-dont-you-need-opsops/
Thanks a lot Ernest for taking your time to describe your experiences, it h
as really opened my eyes as to how you should organize your IT department in order to prioritize speed of delivery over optimizing efficiency. I’m going to do some further reading now and I think I will start with reading all your previous posts first ;-).
Thanks again,
Niek.
Great Article! Can you explain how you handle the unplanned work that hits Ops on a day to day basis? How do you integrate or deal with that in Jira?
Hi! Sorry I didn’t get to this earlier. So I deal with unplanned work in a variety of ways.
First, reduce its amount. There is a certain amount of incident and interrupt work in life, but in a properly run ops team it shouldn’t be more than in a properly run dev team, especially if the devs are on call too. Most of your work should be planned and proactive. I find a lot of “unplanned” work is plannable, but teams just choose not to plan it and instead let it wash over them as people’s demands grow loud instead.
Second, if there’s a small enough amount, use the inevitable oncall rotation as an “interrupt shield.” This concept goes back to Tom Limoncelli’s book “Time Management For System Administrators.” Whoever’s on call, they are oncall during the day too and they handle the interrupt work. They don’t pull sprint tasks that sprint. If they get spare time they can learn or pilot things or do whatever!
Third, if there’s a bunch, then you need more of an expedite lane. When I was at Bazaarvoice we had a lot of flow work, but not enough to just punt on sprints for the whole team. So we had a daily triage meeting, put these in a separate “expedite” swimlane, and people on the teams would grab as needed to meet SLA – whenever they’d finish a sprint task, they’d look at the expedite queue to see if they should get something from there before picking the next backlog task.
Pingback: Scrum for Operations: Just Add DevOps | the agile admin
Would be very interested in methods used to break out work into stories, as well as how you actually handled daily injects – if someone reaches out to team directly, how do we get a light on that? If it’s several 1 – 2 hours tasks, it’s hard to get transparency to that.
Breaking ops work into stories is the same as breaking dev work into stories – you figure out what an actual small (couple day) increment of value is and use that. Normal agile story planning stuff, just the “functionality” is different from most dev-functional examples (maybe… As you get more mature your stories should start sounding more like “Internal user can click a button and get a working deployment of our product” and be somewhat indistinguishable from traditional dev stories).
As for injects, I just answered above how to work them into your process, but you seem to be asking about their visibility – there is no work that should not be tracked in your task management system. Even if it’s a “1-2 hours task” there should be a ticket for it. My current Jira sprints have a lot of short task requests – access requests, sales requests, operational requests – that we always put in Jira, using the Task type. Then we can see in everyone’s swimlane at daily standup what interrupts they’re working on along with planned tasks and I can report on how much of our time/effort in a sprint is planned vs unplanned work.