
Docker – It’s Lighter, Is That Really Why It’s So Awesome?
When docker started to hit so big, I have to admit I initially wondered why. The first thing people would say when they wanted to talk about its value is “There’s slightly less overhead than virtualization!” Uh… great? But chroot jails etc. have existed for a long time, like even back when I got started on UNIX,and fell out of use for a reason, and there also hadn’t been a high pressure rush of virtualization and cloud vendors trying to keep up with the demand for “leaner” VMs – there was some work to that end but it clearly wasn’t a huge customer driver. If you cared too much about the overhead, you had the other extreme of just jamming multiple apps onto one box, old school style. Now, you don’t want to do that – I worked in an environment where that was the policy and I developed my architectural doctrine of “sharing is the devil” as a result. While running apps on bare metal is fast and cost effective, the reliability, security, and manageability impediments are significant. But “here’s another option on the spectrum of hardware to VM” doesn’t seem that transformative on its face.
OK, so docker is a process wrapper that hits the middle ground between a larger, slower VM and running unprotected on hardware. But it’s more than that. Docker also lets you easily create packaged, portable, ready to run applications.
The Problems With Configuration Management Today
The value proposition of docker started to become more clear once the topic of provisioning and deployment came up. Managing systems, applications and application deployments has been at worst a complicated muddle of manual installation, but at best a mix of very complex configuration management systems and baked images (VMs or AMIs). Engineers skilled in chef or puppet are rare. And developers wanted faster turnaround to deploy their applications. I’ve worked in various places where the CM system did app deploys but the developers really, really wanted to bypass that via something like capistrano or direct drop-in to tomcat, and there were always continuous discussions over whether there should be dual tooling, a CM system for system configuration and an app deployment system for app deploys. And if you have two different kinds of tooling controlling your configuration (especially when, frankly, the apps are the most important part) leads to a lot of conflict and confusion and problems in the long term.
And many folks don’t need the more complex CM functionality. Many modern workloads don’t need a lot of OS and OS software – the enterprise does that, but many new apps are completely self-contained, even to the point of running their own node.js or jetty, meaning that a lot of the complexity of CM is not needed if you’re just going to drop a file onto a vanilla box and run it. And then there’s the question of orchestration. Most CM systems like to put bits on boxes, but once there’s a running interconnected system, they are more difficult to deal with. Many discussions about orchestration over the years were frankly rebuffed by the major CM vendors and replied to with “well, then integrate with something (mcollective, rundeck).” In fact, this led to the newer products like ansible and salt arising – they are simpler and more orchestration focused.
But putting bits on boxes is only the first step. Being able to operate a running system is more important.
Service Management
Back when all of the agile admins were working at National Instruments, we were starting a new cloud project and wanted to automate everything from first principles. We looked at Chef and Puppet but first, we needed Windows support (this was back in 2008, and their Windows support was minimal), and second, we had the realization that a running cloud, REST services type system is composed of various interdependent services, and that we wanted to model that explicitly. We wanted more than configuration management – we wanted service management.
What does it look like when you draw out your systems? A box and line diagram, right? Here’s part of such a diagram from our systems back then.
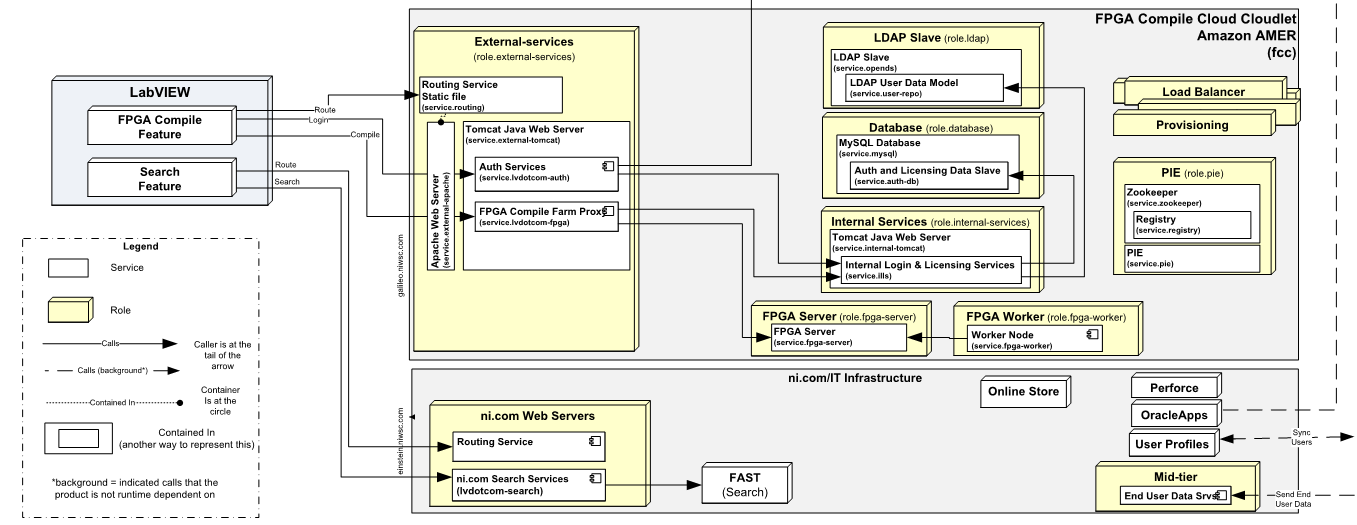
Well, not to oversimplify, but when you use something like CloudFormation, you get the yellow boxes (hardware, VMs, cloud instances). When you use something like chef or puppet, you get the white boxes (software on the box). But what about the lines? The point of all those bits is to create services, which are called by customers and/or other services, and being able to address those services and the relationships between them is super important. And trying to change any of the yellow or white boxes without intelligent orchestration to handle the lines – what makes your services actually work – is folly.
In our case, we made the Programmable Infrastructure Environment – modeled the above using XML files and then added a zookeeper-based service registry to handle the connections, so that we could literally replace a database server and have all the other services dependent on it detect that, automatically parse their configurations, restart themselves if necessary, and connect to the new one.
This revolutionized the way we ran systems. It was very successful and was night and day different from the usual method of provisioning, but more importantly, controlling production systems in the face of both planned and unplanned changes. It allowed us to instantiate truly identical environments, conduct complex deployments without downtime, and collaborate easily between developers and operations staff on a single model in source control that dictated all parts of the system, from system to third party software to custom applications.
That, in conjunction with ephemeral cloud systems, also made our need for CM a lot simpler – not like a university lab where you want it to always be converging to whatever new yum update is out, but creating specifically tooled parts for one use and making new ones and throwing the old ones away as needed. Since we worked at National Instruments, this struck us as on the same spectrum the difference from hand-created hardware boards to FPGAs to custom chips – the latter is faster and cheaper and basically you throw it away for a new one when you need a change, though those others are necessary steps along the path to creating a solid chip.
We kept wondering when the service management approach would catch on. Ubuntu’s Juju works in this way, but stayed limited to Ubuntu for a long time (though it got better recently!) and hasn’t gotten much reach as a result.
Once docker came out – lo and behold, we started to see that pattern again!
Docker and Service Management
Dockerfiles are simple CM systems that pull some packages, install some software, and open some ports. Here’s an example of a dockerfile for haproxy:
# # Haproxy Dockerfile # # https://github.com/dockerfile/haproxy # # Pull base image. FROM dockerfile/ubuntu # Install Haproxy. RUN \ sed -i ‘s/^# \(.*-backports\s\)/\1/g’ /etc/apt/sources.list && \ apt-get update && \ apt-get install -y haproxy=1.5.3-1~ubuntu14.04.1 && \ sed -i ‘s/^ENABLED=.*/ENABLED=1/’ /etc/default/haproxy && \ rm -rf /var/lib/apt/lists/* # Add files. ADD haproxy.cfg /etc/haproxy/haproxy.cfg ADD start.bash /haproxy-start # Define mountable directories. VOLUME [“/haproxy-override”] # Define working directory. WORKDIR /etc/haproxy # Define default command. CMD [“bash”, “/haproxy-start”] # Expose ports. EXPOSE 80 EXPOSE 443
Pretty simple right? And you can then copy that container (like an AMI or VM image) instead of re-configuring every time. Now, there are arguments against using pre-baked images – see Golden Image or Foil Ball. But at scale, what’s the value of conducting the same operations 1000 times in parallel, except for contributing to the heat death of the universe? And potentially failing from overwhelming the same maven or artifactory server or whatever when massive scaling is required? There’s a reason Netflix went to an AMI “baking” model rather than relying on config management to reprovision every node from scratch. And with docker containers each container doesn’t have a mess of complex packages to handle dependencies for; they tend to be lean and mean.
But the pressure of the dynamic nature of these microservices has meant that actual service dependencies have to be modeled. Bits of software like etcd and docker compose are tightly integrated into the container ecosytem to empower this. With tools like this you can define a multi-service environment and then register and programmatically control those services when they run.
Here’s a docker compose file:
web:
build: .
ports:
- "5000:5000"
volumes:
- .:/code
links:
- redis
redis:
image: redis
It maps the web server’s port 5000 to the host port 5000 and creates a link to the “redis” service. This seems like a small thing but it’s the “lines” on your box and lines diagram and opens up your entire running system to programmatic control. Pure CM just lets you change the software and the rest is largely done by inference, not explicit modeling. (I’m sure you could build something of the sort in Chef data bags or whatnot, but that’s close to saying “you could code it yourself” really.)
This approach was useful even in the VM and cloud world, but the need just wasn’t acute enough for it to emerge. It’s like CM in general – it existed before VMs and cloud but it was always an “if we have time” afterthought – the scale of these new technologies pushed it into being a first order consideration, and then even people not using dynamic technology prioritized it. I believe service management of this sort is the same way – it didn’t “catch on” because people were not conceptually ready for it, but now that containers is forcing the issue, people will start to use this approach and understand its benefit.
CM vs. App Deployment?
In addition, managing your entire infrastructure like a build pipeline is easier and more aligned with how you manage the important part, the applications and services. It’s a lot harder to do a good job of testing your releases when changes are coming from different places – in a production system, you really don’t want to set the servers out there and roll changes to them in one way and then roll changes to your applications in a different way. New code and new package versions best roll through the same pipeline and get the same tests applied to them. While it is possible to do this with normal CM, docker lends itself to this by default. However, it doesn’t bother to address this on the core operating system, which is an area of concern and a place where well thought out CM integration is important.
Conclusion
The future of configuration management is in being able to manage your services and their dependencies directly, and not by inference. The more these are self-contained, the more the job of CM is simpler just as now that we’ve moved into the cloud the need for fiddling with hardware is simpler. Time spent messing with kernel configs and installing software has dropped sharply as we have started to abstract systems at a higher level and use more small, reusable bits. Similarly, complex config management is something that many people are looking at and saying “why do I need this any more?” I think there are cases where you need it, but you should start instead with modeling your services and managing those as the first order of concern, backing it with just enough tooling for your use case.
Just like the cloud forced the issue with CM and it finally became a standard practice instead of an “advanced topic,” my prediction is that containers will force the issue with service management and cause it to become more of a first class concern for CM tools back even in cloud/VM/hardware environments.
This article is part of our Docker and the Future of Configuration Management blog roundup running this November. If you have an opinion or experience on the topic you can contribute as well!

In Twitter there was an insightful comment – “but aren’t dockerfiles a form of configuration management?” Well, yes of course. But they are distinguished from Configuration Management ™ the way that has become implemented in existing frameworks.
I remember similarly twitching and getting agitated when Adrian Cockroft said “we don’t have ops at Netflix” and then later when I heard him say “we don’t have process at Netflix” I squirmed in my seat like an itchy bear cub – they had ops, and they had process (there’s no such thing as no process, just crappy undefined process); what he meant was that “these things don’t exist in their usual form.”
And that IMO is the problem with the CM world right now, I think it’s lost sight of the truism that different problems need different solutions. If I have a big university lab full of systems that need to just yum update themselves to keep up on security patches and whatnot – then traditional chef/puppet running in “do it whenever” master mode is great. If I have a n-tier Web application that needs rolling deploys and restarts to maintain uptime, then maybe something more like ansible that has orchestration as a top level concern is better, or if I want to still be bought in to one of the frameworks I need to do chef-solo or masterless puppet on the nodes and use something else to control them. If I have a bunch of dockery microservices then perhaps something else is better… Although then you do have the issue of “too many solutions.” I hope all these docker service management solutions quickly grow to not just support containers!
(Feel free and discuss in the comments, I’m happy to chat!)
Pingback: Top 10 links for the week of Nov 2 - HighOps
Pingback: Top 10 links for the month of Nov + week of Nov 30 - HighOps
Pingback: The Present and Future of Configuration Management | Nordic APIs |