
There’s a crop of great talks from this event, check them out here. If you look really hard you can see my talk too!
Containers, Configuration Management, and The Right Tool for the Right Job
Docker brings an incredibly appealing method of managing applications to the table, but also requires us to rebuild a lot of systems that aren’t broken. In this post I’m going to look at the pros and cons of Docker and its accompanying ecosystem, and take a look at how one might start to leverage the best parts of Docker without rewriting everything.
What is it about Docker that is so exciting? It was a moonshot experiment that struck home. Rather than providing an incremental improvement over existing infrastructure patterns, Docker takes several leaps forward by providing a fresh way of managing our applications and making them accessible to developers at the same time.
Part of Docker’s success relies on providing highly opinionated solutions to the problems that come with containerizing components in your system. While these solutions are invaluable in terms of accessibility and gaining adoption, they are neither the only solutions nor necessarily the best ones in every case. Even if you are sure you want to subscribe to the opinionated “Docker way” or think it’s a worthwhile trade-off, you will still be accepting a new set of problems in exchange for the old ones, but the new set doesn’t come with the benefit of a decade or so of tools and experience to leverage.
In this post I’m going to discuss what makes Docker attractive to me and what I’m not such a fan of. Then I’m going to explore a hybrid approach that seeks to take advantage of the best parts of Docker without locking me in to the not-so-great parts.
P.S. I was hoping to put together a working demo of the architecture I describe below, but the proposed integration is still not possible… so that’s not going to happen. I’ve sat on this post for a while hoping things would change, but they haven’t, and I’ve decided instead to put this out there as is, as a theoretical architecture.
The Good
Some aspects of docker are home runs. In a time where microservices rule and developing software for the cloud is an obvious choice, how can you pass up a tool that makes managing a gazillion apps as cheap and easy as managing your monolith? And it’s a DevOps game changer: In the same way that AWS removed the friction between dev and ops for provisioning a VM, Docker removes the friction of configuring an app’s dependencies and installation. What’s more, local dev of even dozens of applications can be kept lean, and we’re closer than ever to feeling confident in “it works on my laptop.”
In summary:
- Dense clouds
- Transactional installs
- Bundled dependencies
- Tools for packaging deterministic and repeatable deploys (and rollbacks)
- Developer workflow is simple and production-like
The Bad
A lot of the design decisions of Docker involve trade-offs, and networking is no exception.
For local dev, where managing many VMs is especially difficult and high availability isn’t important, Docker’s unique method of standing up a virtual bridge interface and allocating new IPs as containers are started is really convenient. But it is less than complete when you start worrying about high availability and exposing your services to external systems. Layering in additional networking or mapping ports to the bridge interface starts to solve this problem, but it also leaves you with a jumble.
Service discovery largely abstracts away this jumble, but at this point we’ve gone through at least three networking transformations to effectively address our services and we haven’t even started to integrate with non-Docker managed services.
Don’t get me wrong, I definitely think service discovery is the way to go. I just think that since Docker has coupled networking so tightly with its implementation, it should have made it more flexible and done more to make inter-host communication work the same as intra-host communication. Additionally, better hooks to integrate with existing software-defined networks would make all the integration work feel less like a yak shave.
Isolation security is also a concern, but it is easier to shrug off because it should be coming soon. For the time being, however, there is a lack of user namespaces in Docker containers, so UID 0 (root) in a container is also UID 0 (root) on the host machine and has all the access that comes with that.
Another concerning thing about Docker is the Docker hub. Although you don’t have to use this service or the images housed there in production, it’s presented in such a way that many people still do. Even with the addition of download signature checks, we are still left with an index of images that aren’t particularly well vetted or necessarily kept up to date. Many are built on top of full OSes that expose a larger attack surface than is necessary, and there is no established technique to ensure the base OS is up to date on its patches. There are great resources for building thin base OSes and ways to make sure they are kept up to date, but this is still more management left unaddressed.
In summary:
- User namespace security
- Docker hub security
- Networking
The Ugly
One of the first things you realize with Docker is that you have to rethink everything. One is drawn in by the prospect of encapsulating their apps in a clean abstraction, but after fooling around with Supervisord for a while, most people start down the slippery slope of rewriting their entire infrastructure to keep their implementation clean.
This is because Docker isn’t very composable when taken as a whole. If you want to talk to something in a docker container, you need an ambassador. If something in a docker container needs to talk to something not managed in docker, you need an ambassador. Sometimes, you even need an ambassador for two apps both running in containers. This isn’t the end of the world, but it’s more work and is a symptom of how the docker containers are really only composable with other Docker containers, not with our systems as a whole.
What this means is that to leverage the parts of docker we want (the transactional installs, bundled dependencies, and simplified local dev), we have to rewrite and rewire a whole lot of other stuff that wasn’t broken or giving us trouble. Even if it was, you’re still forced to tackle it all at once.
If we were being honest about the shipping container analogy, we’d end up with a container ship not just carrying containers but built with containers as well!
A lot of these problems come from the same thing that makes Docker so easy to use: the bundling (and resulting tight coupling) of all components needed to build, manage, and schedule containers.
This becomes especially clear when trying to place Docker on Gabriel Monroy’s Strata of the Container Ecosystem. Although he places Docker in layer 4 (the container engine), aspects of it leak into almost every layer. It’s this sprawl that makes Docker less composable and is why integrating with it often entails a huge amount of work.
Summary:
- Incompatibile with config management
- Not composable with existing infrastructure patterns and tools
If not Docker, Then What?!
I’m not saying we should forget about docker and go back to the tried-and-true way of doing things. I’m not even saying to wait for the area to mature and produce better abstractions. I’m simply suggesting you do what you’ve always done: Choose the right tool for the right job, pragmatically apply the parts of Docker that make sense for you, and remember that the industry isn’t done changing, so you should keep your architecture in a state that allows for iteration.
Other players in this space
Part of Docker’s appeal is its dirt simple bundling of a new approach that removes a lot of pain we’ve been having. But there are other tools out there that solve these same problems.
- System containers like OpenVZ or LXD provide similar cloud density characteristics
- rkt is (almost ready to be) a competing application container that promises to implement a more composable architecture
- Snappy Ubuntu offers an alternative model for transactional installs, bundling dependencies, and isolation
- Numerous SDN technologies
- Config management (Puppet, Chef, Ansible) provides deterministic and repeatable deploys
- Vagrant simplifies local development in production-like environments
I have no doubt that we will look back and see Docker as the catalyst that led to a very different way of treating our software, but it isn’t going to stay the only major player for long, and some of the old rules still apply: Keep your architecture in a place that allows for iteration.
Lxd, cfg mgmt, docker, and the next generation of stateless apps
So what would a cloud architecture that adopts just the good parts of Docker look like?
First off, here are the characteristics that are important to me and that I would like to support:
- The density and elasticity of containers.
- Transactional installs and rollbacks for my applications.
- The ability to develop locally in a near production environment (without near production hardware).
- Ephemeral systems.
- Managed systems (I’m not comfortable making them immutable because I trust config management tools more than a home-built “re-roll everything” script to protect me against the next bash vulnerability.).
- A composable platform that doesn’t rely on the aspects of Docker (like networking) that would make iterating on it difficult.
One way to accomplish this it is to replace our traditional VMs with a system containers like LXD, continue managing infrastructure on those nodes the same way we always have with tools like Puppet, and start installing the service each node maintains in an application container like Docker.
I wish I could put together a demo to illustrate this, but right now running Docker on LXD is infeasible.
With this setup, we would have to change relatively little: We can expose our application on known ports to abstract away nonstandard networking; we only have one app so the namespace security vulnerability isn’t a problem; and our infrastructure only needs incremental updates to support a container instead of a process.
Scaling can be achieved by adding new system container instances, and, while not as fast as spinning a new application container, it’s still something that can be automated. We also don’t have quite the same density, but we’ve retained most of the benefits there as well.
With this as a starting point, we can build out more twelve-factor cloud support based on what’s most important to us: Service discovery, externalized config, software-defined networking, etc.
Conclusion
The tired old debate of “Containers vs. Configuration Management” is rooted in fallacy. We’ve never tried to solve all of our problems with one technology before (You wouldn’t pull down your Java libraries with Puppet, or keep your load balancer config in Maven Central), so why do we have to start now?
Instead, I recommend we do what we always do: Choose the right tool for the right job.
I think there is definitely room for system containers, application containers, and configuration management to coexist. Hopefully more work will be done to make these two great technologies play nicely together.
I (Ben Schwartz) am a software architect at Kasasa by BancVue where lately I’ve been spending most of my time standing on the shoulders of our awesome DevOps culture to play with emergent infrastructure tools and techniques. Sometimes my experimentation makes it to my blog (including the original posting of this article) which can be found at txt.fliglio.com.
This article is part of our Docker and the Future of Configuration Management blog roundup running this November. If you have an opinion or experience on the topic you can contribute as well!
Filed under DevOps
Docker: Service Management Trumps Configuration Management
Docker – It’s Lighter, Is That Really Why It’s So Awesome?
When docker started to hit so big, I have to admit I initially wondered why. The first thing people would say when they wanted to talk about its value is “There’s slightly less overhead than virtualization!” Uh… great? But chroot jails etc. have existed for a long time, like even back when I got started on UNIX,and fell out of use for a reason, and there also hadn’t been a high pressure rush of virtualization and cloud vendors trying to keep up with the demand for “leaner” VMs – there was some work to that end but it clearly wasn’t a huge customer driver. If you cared too much about the overhead, you had the other extreme of just jamming multiple apps onto one box, old school style. Now, you don’t want to do that – I worked in an environment where that was the policy and I developed my architectural doctrine of “sharing is the devil” as a result. While running apps on bare metal is fast and cost effective, the reliability, security, and manageability impediments are significant. But “here’s another option on the spectrum of hardware to VM” doesn’t seem that transformative on its face.
OK, so docker is a process wrapper that hits the middle ground between a larger, slower VM and running unprotected on hardware. But it’s more than that. Docker also lets you easily create packaged, portable, ready to run applications.
The Problems With Configuration Management Today
The value proposition of docker started to become more clear once the topic of provisioning and deployment came up. Managing systems, applications and application deployments has been at worst a complicated muddle of manual installation, but at best a mix of very complex configuration management systems and baked images (VMs or AMIs). Engineers skilled in chef or puppet are rare. And developers wanted faster turnaround to deploy their applications. I’ve worked in various places where the CM system did app deploys but the developers really, really wanted to bypass that via something like capistrano or direct drop-in to tomcat, and there were always continuous discussions over whether there should be dual tooling, a CM system for system configuration and an app deployment system for app deploys. And if you have two different kinds of tooling controlling your configuration (especially when, frankly, the apps are the most important part) leads to a lot of conflict and confusion and problems in the long term.
And many folks don’t need the more complex CM functionality. Many modern workloads don’t need a lot of OS and OS software – the enterprise does that, but many new apps are completely self-contained, even to the point of running their own node.js or jetty, meaning that a lot of the complexity of CM is not needed if you’re just going to drop a file onto a vanilla box and run it. And then there’s the question of orchestration. Most CM systems like to put bits on boxes, but once there’s a running interconnected system, they are more difficult to deal with. Many discussions about orchestration over the years were frankly rebuffed by the major CM vendors and replied to with “well, then integrate with something (mcollective, rundeck).” In fact, this led to the newer products like ansible and salt arising – they are simpler and more orchestration focused.
But putting bits on boxes is only the first step. Being able to operate a running system is more important.
Service Management
Back when all of the agile admins were working at National Instruments, we were starting a new cloud project and wanted to automate everything from first principles. We looked at Chef and Puppet but first, we needed Windows support (this was back in 2008, and their Windows support was minimal), and second, we had the realization that a running cloud, REST services type system is composed of various interdependent services, and that we wanted to model that explicitly. We wanted more than configuration management – we wanted service management.
What does it look like when you draw out your systems? A box and line diagram, right? Here’s part of such a diagram from our systems back then.
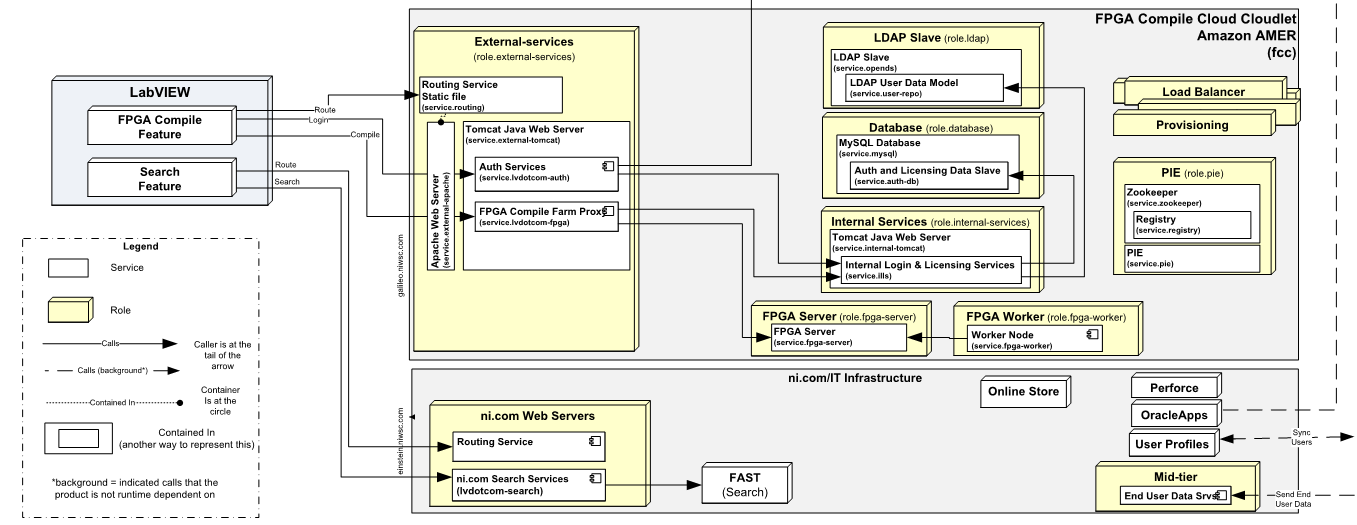
Well, not to oversimplify, but when you use something like CloudFormation, you get the yellow boxes (hardware, VMs, cloud instances). When you use something like chef or puppet, you get the white boxes (software on the box). But what about the lines? The point of all those bits is to create services, which are called by customers and/or other services, and being able to address those services and the relationships between them is super important. And trying to change any of the yellow or white boxes without intelligent orchestration to handle the lines – what makes your services actually work – is folly.
In our case, we made the Programmable Infrastructure Environment – modeled the above using XML files and then added a zookeeper-based service registry to handle the connections, so that we could literally replace a database server and have all the other services dependent on it detect that, automatically parse their configurations, restart themselves if necessary, and connect to the new one.
This revolutionized the way we ran systems. It was very successful and was night and day different from the usual method of provisioning, but more importantly, controlling production systems in the face of both planned and unplanned changes. It allowed us to instantiate truly identical environments, conduct complex deployments without downtime, and collaborate easily between developers and operations staff on a single model in source control that dictated all parts of the system, from system to third party software to custom applications.
That, in conjunction with ephemeral cloud systems, also made our need for CM a lot simpler – not like a university lab where you want it to always be converging to whatever new yum update is out, but creating specifically tooled parts for one use and making new ones and throwing the old ones away as needed. Since we worked at National Instruments, this struck us as on the same spectrum the difference from hand-created hardware boards to FPGAs to custom chips – the latter is faster and cheaper and basically you throw it away for a new one when you need a change, though those others are necessary steps along the path to creating a solid chip.
We kept wondering when the service management approach would catch on. Ubuntu’s Juju works in this way, but stayed limited to Ubuntu for a long time (though it got better recently!) and hasn’t gotten much reach as a result.
Once docker came out – lo and behold, we started to see that pattern again!
Docker and Service Management
Dockerfiles are simple CM systems that pull some packages, install some software, and open some ports. Here’s an example of a dockerfile for haproxy:
# # Haproxy Dockerfile # # https://github.com/dockerfile/haproxy # # Pull base image. FROM dockerfile/ubuntu # Install Haproxy. RUN \ sed -i ‘s/^# \(.*-backports\s\)/\1/g’ /etc/apt/sources.list && \ apt-get update && \ apt-get install -y haproxy=1.5.3-1~ubuntu14.04.1 && \ sed -i ‘s/^ENABLED=.*/ENABLED=1/’ /etc/default/haproxy && \ rm -rf /var/lib/apt/lists/* # Add files. ADD haproxy.cfg /etc/haproxy/haproxy.cfg ADD start.bash /haproxy-start # Define mountable directories. VOLUME [“/haproxy-override”] # Define working directory. WORKDIR /etc/haproxy # Define default command. CMD [“bash”, “/haproxy-start”] # Expose ports. EXPOSE 80 EXPOSE 443
Pretty simple right? And you can then copy that container (like an AMI or VM image) instead of re-configuring every time. Now, there are arguments against using pre-baked images – see Golden Image or Foil Ball. But at scale, what’s the value of conducting the same operations 1000 times in parallel, except for contributing to the heat death of the universe? And potentially failing from overwhelming the same maven or artifactory server or whatever when massive scaling is required? There’s a reason Netflix went to an AMI “baking” model rather than relying on config management to reprovision every node from scratch. And with docker containers each container doesn’t have a mess of complex packages to handle dependencies for; they tend to be lean and mean.
But the pressure of the dynamic nature of these microservices has meant that actual service dependencies have to be modeled. Bits of software like etcd and docker compose are tightly integrated into the container ecosytem to empower this. With tools like this you can define a multi-service environment and then register and programmatically control those services when they run.
Here’s a docker compose file:
web:
build: .
ports:
- "5000:5000"
volumes:
- .:/code
links:
- redis
redis:
image: redis
It maps the web server’s port 5000 to the host port 5000 and creates a link to the “redis” service. This seems like a small thing but it’s the “lines” on your box and lines diagram and opens up your entire running system to programmatic control. Pure CM just lets you change the software and the rest is largely done by inference, not explicit modeling. (I’m sure you could build something of the sort in Chef data bags or whatnot, but that’s close to saying “you could code it yourself” really.)
This approach was useful even in the VM and cloud world, but the need just wasn’t acute enough for it to emerge. It’s like CM in general – it existed before VMs and cloud but it was always an “if we have time” afterthought – the scale of these new technologies pushed it into being a first order consideration, and then even people not using dynamic technology prioritized it. I believe service management of this sort is the same way – it didn’t “catch on” because people were not conceptually ready for it, but now that containers is forcing the issue, people will start to use this approach and understand its benefit.
CM vs. App Deployment?
In addition, managing your entire infrastructure like a build pipeline is easier and more aligned with how you manage the important part, the applications and services. It’s a lot harder to do a good job of testing your releases when changes are coming from different places – in a production system, you really don’t want to set the servers out there and roll changes to them in one way and then roll changes to your applications in a different way. New code and new package versions best roll through the same pipeline and get the same tests applied to them. While it is possible to do this with normal CM, docker lends itself to this by default. However, it doesn’t bother to address this on the core operating system, which is an area of concern and a place where well thought out CM integration is important.
Conclusion
The future of configuration management is in being able to manage your services and their dependencies directly, and not by inference. The more these are self-contained, the more the job of CM is simpler just as now that we’ve moved into the cloud the need for fiddling with hardware is simpler. Time spent messing with kernel configs and installing software has dropped sharply as we have started to abstract systems at a higher level and use more small, reusable bits. Similarly, complex config management is something that many people are looking at and saying “why do I need this any more?” I think there are cases where you need it, but you should start instead with modeling your services and managing those as the first order of concern, backing it with just enough tooling for your use case.
Just like the cloud forced the issue with CM and it finally became a standard practice instead of an “advanced topic,” my prediction is that containers will force the issue with service management and cause it to become more of a first class concern for CM tools back even in cloud/VM/hardware environments.
This article is part of our Docker and the Future of Configuration Management blog roundup running this November. If you have an opinion or experience on the topic you can contribute as well!
Filed under DevOps
Docker and the Future of Configuration Management – Coming In November!
All right! We have a bunch of authors lined up for our blog roundup on Docker and the future of CM. We’ll be publishing them throughout the month of November. But it’s not too late to get in on the action, speak up and you can get a guest post too! And have a chance to win that sweet LEGO Millenium Falcon…
To get you in the mood, here’s some good Docker and CM related posts I’ve read lately:
- Swarm v. Fleet v. Kubernetes v. Mesos – Comparing different orchestration tools
- RedHat’s Docker Build Method – S2I (Source to Image)
- Docker Container for IO Benchmarking
- Managing Mesos, Chronos, and Docker with Puppet – from PuppetCon 2015
And a video, Immutable Awesomeness – I saw John and Josh present this at DevOps Enterprise Summit and it’s a must-watch! Using containers to create immutable infrastructure for DevOps and security wins.
Filed under DevOps
Agile Organization: Project Based Organization
This is the fourth in the series of deeper-dive articles that are part of Agile Organization Incorporating Various Disciplines.
The Project Based Organization Model
You all know this one. You pick all the resources needed to accomplish a project (phase of development on a product), have them do it, then reassign them!
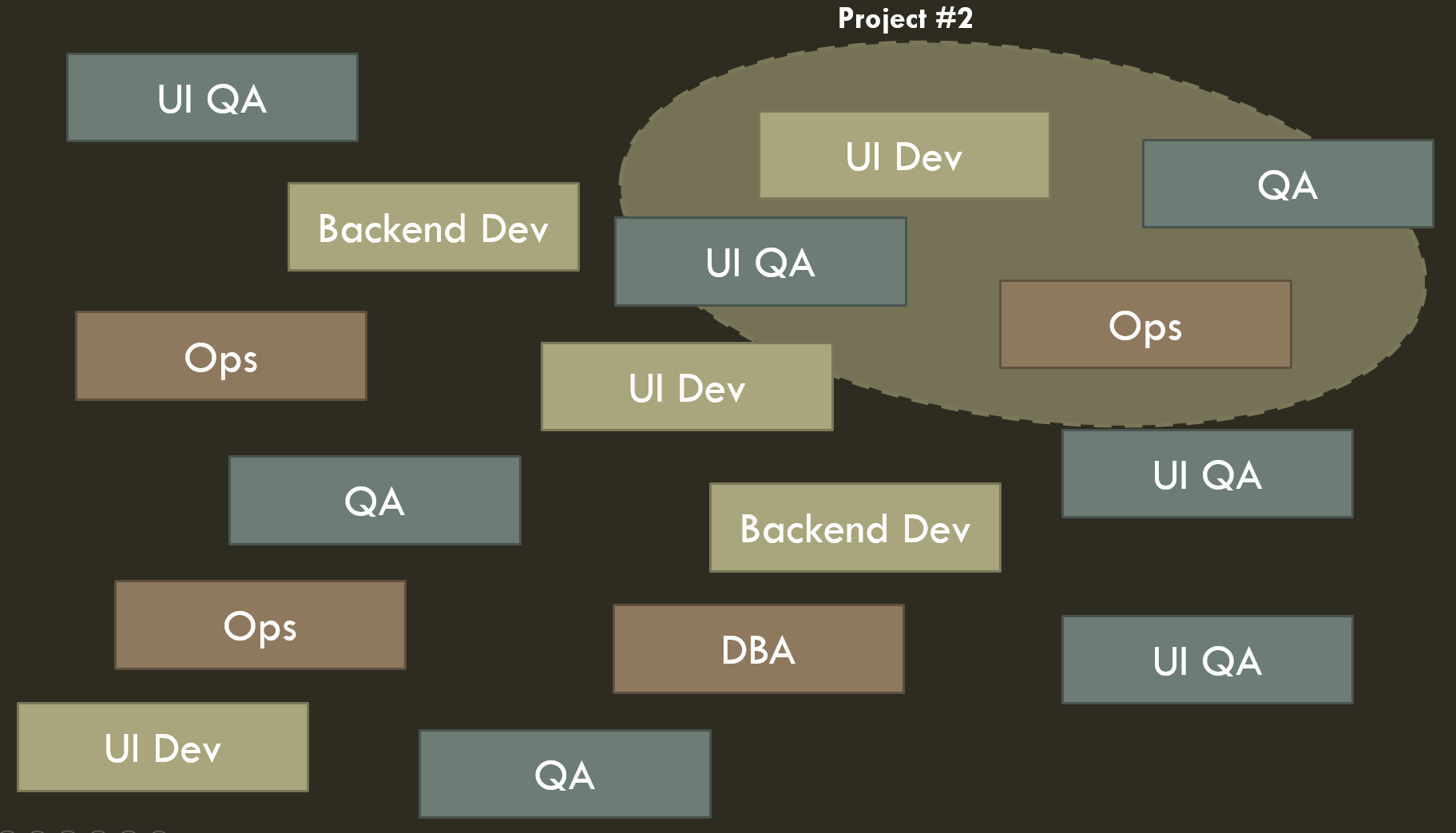
Benefits Of The Project Based Model
- The beancounters love it. You are assigning the minimum needed resource to something “only as long as it’s needed.”
Drawbacks Of The Project Based Model
Where to even begin?
- First of all, teams don’t do well if not allowed to go through the Tuckman’s stages of development (forming/storming/norming/performing); engineer satisfaction plummets.
- Long term ownership isn’t the team’s responsibility so there is a tendency to make decisions that have long term consequences – especially bearing on stability, performance, scalability – because it’s clear that will be someone else’s problem. Even when there is a “handoff” planned, it’s usually rushed as the project team tries to ‘get out of there’ from due date or expenditure pressures. More often there is a massive generation of “orphans” – services no one owns. This is immensely toxic – it’s a problem with shipping software, but with a live service it’s awful, as even if there’s some “NOC” type ops org somewhere that can get it running again if there’s an issue, chronic issues can’t be fixed and problems cause more and more load on service consumers, support, and NOC staff.
- Mentoring, personnel development, etc. are hard and tend to just be informal (e.g. “take more classes from our LMS”).
Experience With The Project Based Model
At Bazaarvoice, we got to where we were getting close to doing this with continued reorganization to gerrymander just the right number of people onto the projects with need every month. Engineer satisfaction tanked to the degree that it became an internal management crisis we had to do all kinds of stuff to dig ourselves back out of.
Of course, many consulting relationships work this way. It’s the core behind many of the issues people have with outsourced development. There are a lot of mitigations for this, most of which are “try not to do it” – like I’ve worked with outsourcers trying to ensure lower churn on outsource teams, try to keep teams stable and working on the same thing longer.
It does have the merit of working if you just don’t care about long term viability. Developing free giveaway tools, for example – as long as they’re not so bad they reflect poorly on your company, they can be problematic and unowned in the long term.
Otherwise, this model is pretty terrible from a quality results perspective and it’s really only useful when there’s hard financial limitations in place and not a strong culture of responsibility otherwise. It’s not very friendly to agile concepts or devops, but I am including it here because it’s a prevalent model.
Agile Organization: Fully Integrated Service Teams
This is the third article in the series of deeper-dive articles that are part of Agile Organization Incorporating Various Disciplines.
The Fully Integrated Service Team Model
The next step along the continuum of decentralization is complete integration of the disciplines into one service team. You simply have an engineering manager, and devs, operations staff, QA engineers, etc. all report to them. It’s similar to the Embedded Crossfunctional Team model but you do away with the per-discipline reporting structure altogether.
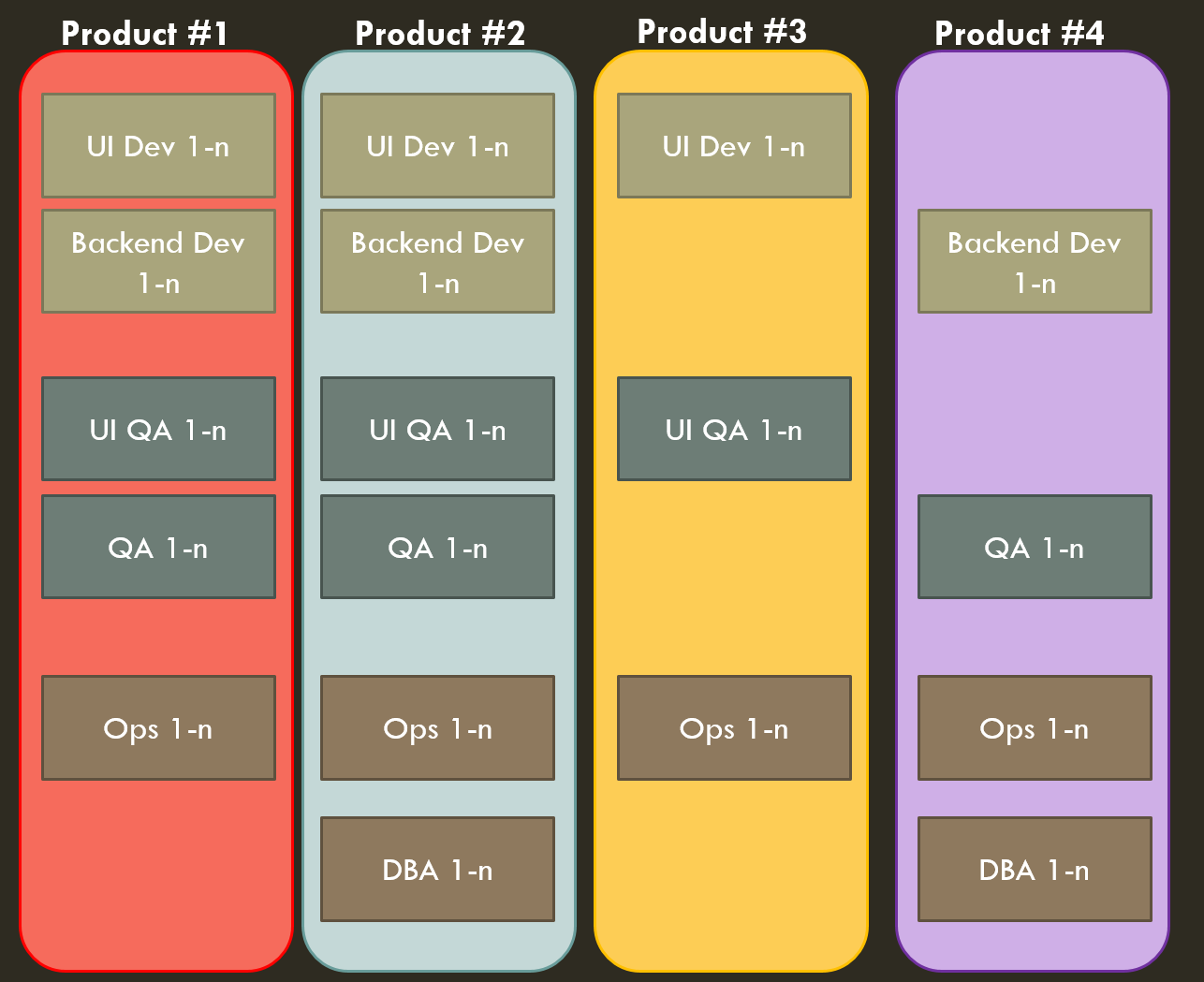
Benefits Of Integrated Service Teams
This has the distinct benefit of end to end ownership. Engineers of every discipline have ownership for the overall product. It allows them to break out of their single-discipline shell, as well – if you are good at regression testing but also can code, or are a developer but strong in operations, great! There’s no fence saying whose job is whose, you all pull tasks off the same backlog. In general you get the same benefits as the Crossfunctional Team model.
Drawbacks of Integrated Service Teams
This is theoretical nirvana, but has a number of challenges.
First, a given team manager may not have the knowledge or experience in each of those areas. While you don’t need deep expertise in every area to manage a team, it can be easy to not understand how to evaluate or develop people from another discipline. I have seen dev managers, having been handed ops engineers, fail to understand what they really do or they value, and lose them as a result.
Even more dangerous is when that happens and the manager figures they didn’t need that discipline in the first place and just backfills with what they are comfortable with. For a team to really own a service from initiation to maintenance, the rest of the team has to understand what is involved. It’s very easy to slip back into the old habits of considering different teams first class vs second class vs third class citizens, just making classes of engineer within your team. And obviously, disenfranchising people works directly against energizing them and giving them ownership and responsibility.
Mitigations for that include:
- Time – over time, a team learns the basics of the other branches and what is required of them.
- Discipline “user groups” (aka “guilds”) – having a venue for people from a horizontal discipline to meet and share best practices and support each other. When we did this with our ops team we always intended to set up a “DevOps user group” but between turnover and competing priorities, it never happened – which reduced the level of success.
A second issue is scaling. Moving from “zone” to “man” coverage, as this demands, is more resource intensive. If you have nine product teams but five operations engineers, then it seems like either you can’t do this or you can but have to “share” between several teams. Such sharing works but directly degrades the benefits of ownership and impedance matching that you intend to gain from this scheme. In fact, if you want to take the prudent step of having more than one person on a team know how to do something – which you probably should – then you’d need 18 and not just nine ops engineers.
Mitigations for this include:
- Do the math again. If the lack of close integration with that discipline is holding back your rate of progress, then you’re losing profits to reduce expenditures – a bad bet for all but the most late-stage companies.
- Crosstraining. You may have one ops, or QA, or security expert, but that doesn’t (and, to be opinionated, shouldn’t) mean that they are the only ones who know how to perform that function. When doing this I always used the rule “if you know how to do it, you’re one of the people that should pull that task – and you should learn how to do it.” This can be as simple as when someone wants the QA or ops or whatever engineer to do something, to instead walk the requestor through how to do it.
Experience with Integrated Service Teams
Our SaaS team at NI was fully integrated. That worked great, with experienced and motivated people in a single team, and multiple representatives of each discipline to help reinforce each other and keep developing.
We also fully integrated DevOps into the engineering teams at Bazaarvoice. That didn’t work as well, we saw attrition from those ops engineers from the drawbacks I went over above (managers not knowing what to do with/how to recruit, retain, develop ops engineers). In retrospect we should not have done it and should have stayed with an embedded crossfunctional team in that environment – the QA team did so and while collaboration on the team was slightly impeded they didn’t see the losses the ops side did.
Agile Organization: Embedded Crossfunctional Service Teams
This is the second in the series of deeper-dive articles that are part of Agile Organization Incorporating Various Disciplines. Previously I wrote about the “traditional” siloed model as Agile Organization: Separate Teams By Discipline.
Basic agile doctrine, combined with ITSM thinking, strongly promulgate a model where a team owns a business service or product. I’ll call this a “service team” for the sake of argument, but it applies to products as well.
The Embedded Crossfunctional Team Model
Simply enough, a service team has specialists from other groups – product, QA, Ops, whatever – assigned to it on an exclusive basis. They go sit with (where possible) and participate with the group in their process. The team then contains all the resources required to bring their service or product to completion (in production, for services). The mix of required skills may vary – in this diagram, product #4 is probably a pure back end service and product #3 is probably a very JavaScriptey UI product, for example.
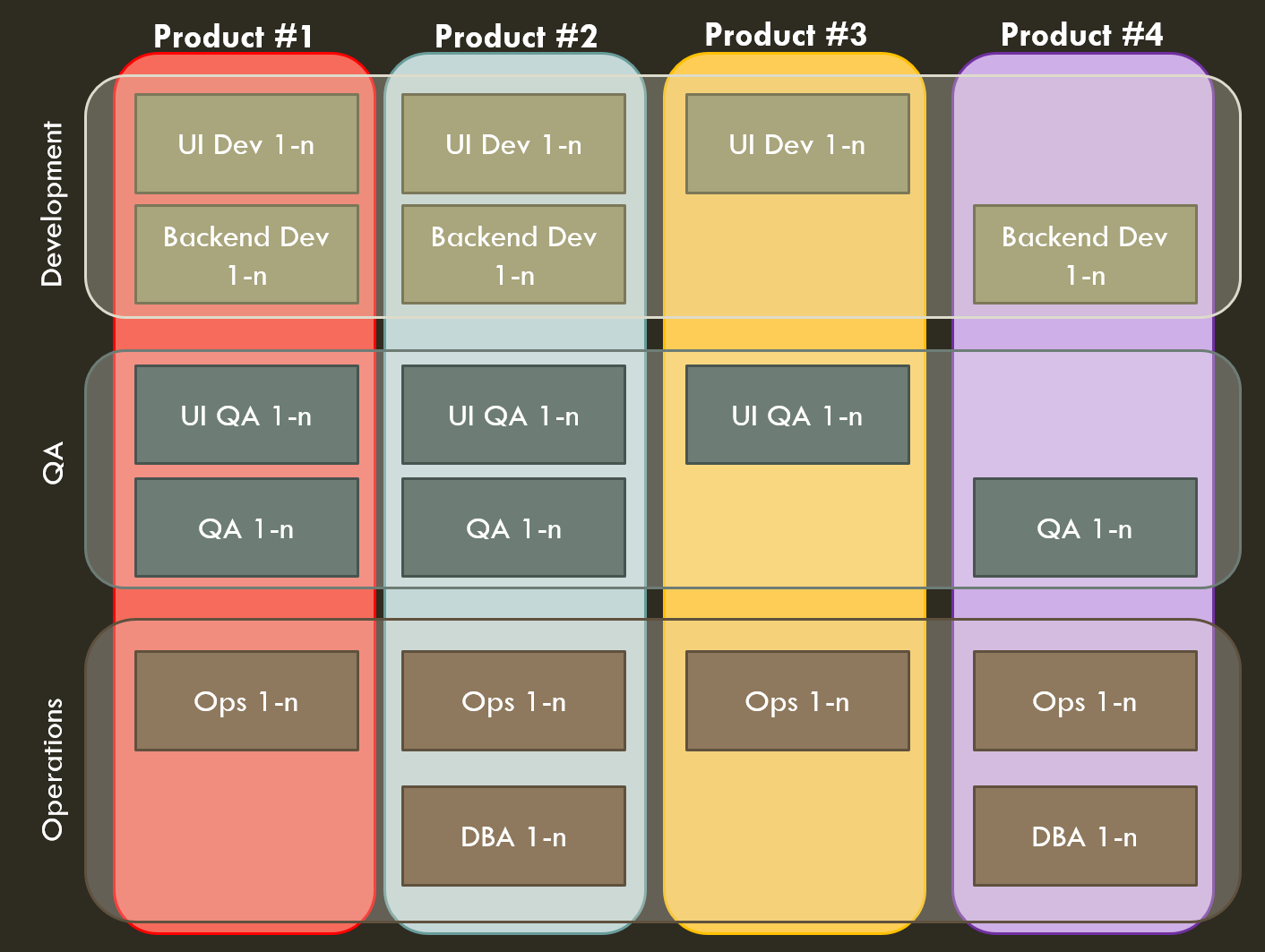
Benefits of Embedded Crossfunctional Teams
This model has a lot of benefits.
- Since team members are semi-permanently assigned into the team, they don’t have conflicting work and priorities. They learn to understand what the needs are of that specific product and collaborate much more effectively with all the others working on it.
- This leads to removal of many bottlenecks and delays as the team, if it has all the components it needs to deliver its service, can organically assign work in an optimal way.
- It is amazing how much faster this model is in practice than the separate teams by discipline model in terms of time to delivery.
- Production uptime and performance are improved because the team is “eating its own dog food” and is aware of production issues directly, not as some ticket from some other team that gets routed, ignored, finger-pointed…
Drawbacks of Embedded Crossfunctional Teams
- Multiple masters is always an issue for an engineer. Are you trying to please the service team’s manager or your “real” manager, especially when their values seem to conflict? You have to do some political problem-solving then, and engineers hate doing that. It also provides some temptation to double-resource or otherwise have the embedded engineer “do something else” the ops team needs done, violating the single service focus.
- It’s more expensive. Yes, if you do this, you need at least one specialist per service team. You have to play man-to-man, not zone, to get the benefits of the approach. This should make you think about how you create your service teams; if you define a service as one specific microservice and you have teams with e.g. 2 devs on them, then embedding specialists is way more expensive. Consider basing things on the business concept of a service and having those devs working on more than one widget, targeting the 2-pizza team size (also those devs will be supporting/sustaining whichever services aren’t brand new). (Note that this is only “more expensive” in the sense that doesn’t bother with ROI and just takes raw costs as king – you get stuff out and start making revenue faster, so it’s really less expensive from a whole-company POV, but from the IT beancounter perspective “what’s profit?”)
- While you get benefits of crosstraining across the disciplines, the e.g. ops folks don’t have regular all-day contact with other ops folks and so you need to take care to set up opportunities for the “ops team” to get together, share info, mentor each other, etc. as well. Folks call these “tribes” or “guilds” or similar.
Experience with Crossfunctional Teams
It can be hard at the beginning, when teams don’t understand each others’ discipline or even language yet. I had a lengthy discussion with an application architect on one team – he felt that having ops people in the design reviews he was holding was confusing and derailing. The ops people spoke some weird moon-man language to him and it made the reviews go longer and require a lot more explanation. I said “Yes, they do. But we have two choices – keep doing it together, have people learn each others’ concerns and language, and start a virtuous cycle of collaboration, or split them apart and propagate the vicious cycle we know all too well where we have difficulty working together.” So we powered through that and stayed together, and it all worked out well in the end.
When we piloted this at Bazaarvoice, one of the first ops to embed got in there, worked with the devs, and put all his work into their JIRA project. The devs got sticker shock very quickly once they saw how much work there was in delivering a reliable service – and when they dug into those tickets, they realized that they weren’t BS or busywork, but that when they thought about it they said “yeah… We certainly do need that, all this is for real!” The devs then started pulling tickets on monitoring, backups, provisioning, etc. because they realized all that workload on one person would put their delivery date behind. It was nice to see devs realize all the work that really went into doing ops – “out of sight, out of mind,” and too often devs assume ops don’t do anything except move their files to production on occasion. The embedding allowed them to rally to control their own delivery date instead of just “be blocked on the ops team.”
No one approach is “best,” but in general my experiences so far lead me to consider this one of the better models to use if you can get the organizational buy-in to the fundamental “you built it, you run it” concept.
Docker and The Future of Configuration Management – Call For Posts
Docker Docker Docker
![]() Docker is taking the DevOps world by storm. It has moved from “cool DevOps tool” to “lots of attention at the highest levels in the enterprise” in record time. One of the key discussion points when introducing docker, however, is how that will interact with the rest of your configuration management picture. Some people have claimed that the docker model greatly reduces the need for traditional CM; others disagree and feel that’s too simplistic an approach. (If you aren’t sure what docker is yet, check out Karthik’s recent Webcast Why To Docker? for an intro.)
Docker is taking the DevOps world by storm. It has moved from “cool DevOps tool” to “lots of attention at the highest levels in the enterprise” in record time. One of the key discussion points when introducing docker, however, is how that will interact with the rest of your configuration management picture. Some people have claimed that the docker model greatly reduces the need for traditional CM; others disagree and feel that’s too simplistic an approach. (If you aren’t sure what docker is yet, check out Karthik’s recent Webcast Why To Docker? for an intro.)
What we want to do here at the Agile Admin is collect a diversity of experiences on this! Therefore we are declaring a blog roundup on this topic where we’ll publish a bunch of articles on the topic. And we’d love for any of you out there to participate!
Come Blog With Us
Just email us (ernest dot mueller at theagileadmin.com works) or reply in the comments to this post saying “I will write something on this!” and we’ll publish your thoughts on the topic here on The Agile Admin. We’ll be starting this roundup in about a week and looking to finish up by the end of November. We’re specifically soliciting some authors to write on the topic, but we also want all of you in the DevOps community to get your say in. We can set you up as an author here in our WordPress, or you can write in Word or whatnot and mail it in, either way. Make sure and include a brief blurb about who you are at the end!
Fun and Prizes!
 StackEngine has generously agreed to sponsor this roundup, and the best community post (we’ll choose one) by Nov 30 will win a LEGO Millenium Falcon to show off their geek cred! And very soon even your kids will know what it is.
StackEngine has generously agreed to sponsor this roundup, and the best community post (we’ll choose one) by Nov 30 will win a LEGO Millenium Falcon to show off their geek cred! And very soon even your kids will know what it is.
So please let us know you’d like to participate, and then write an article – really anything touching on docker and config management is fine, even “we started to look into docker and stopped because we couldn’t figure out how to slot it in with our existing CM,” or “the simplicity of dockerfiles makes me swear off CM forever” or “golden images are the way to go” or “who needs docker anyway if you have a stellar chef implementation you get the same benefits…” No restrictions (other than those good taste and professionalism dictate). Heck, other containerization technologies than docker per se are fine too. “Containers, CM, what do you know?” No length requirements, and you can have images and videos and stuff, that’s all great.
We know keeping up a whole blog is a lot of work many technologists don’t have time for, so this is our first experiment in letting other great DevOps folks who may want to write an article every once in a while without the hassle of running their own thing use The Agile Admin to get their post out to a decent-sized audience. Come on down, we’re friendly!
 And thanks to StackEngine for sponsoring the roundup! They are an Austin startup that’s all about Docker tooling. Fellow Agile Admin Karthik and Boyd, who many of you know from the Austin-and-wider DevOps scene, are part of the SE team, which vouches for their awesomeness.
And thanks to StackEngine for sponsoring the roundup! They are an Austin startup that’s all about Docker tooling. Fellow Agile Admin Karthik and Boyd, who many of you know from the Austin-and-wider DevOps scene, are part of the SE team, which vouches for their awesomeness.
Filed under DevOps
The Agile Admin, Now Also On Tumblr
For all the under-18 DevOps fans out there, The Agile Admin is now available via Tumblr too at http://theagileadmin.tumblr.com/! Get your parents’ permission…
Filed under General
Innotech Austin Continuous Delivery Summit
Last week we had a DevOps track branded “CD Summit” at Innotech Austin, run by devops.com, and the agile admins were there!
I did a presentation about the various DevOps transformations I had a leadership role in at National Instruments and Bazaarvoice:
And James Wickett did a presentation on Application Security Epistemology in a Continuous Delivery World:
Jez Humble also spoke, as well as a batch of other folks including Austinite Boyd Hemphill and “our friend from Chicago” JP Morgenthal. Once those slides are all posted I’ll pass the link on to you all!
Filed under Conferences, DevOps
