
I’ve been writing a LinkedIn Learning course on postmortems lately and digging into all the fun research on the topic (Dekker, Hollnagel, and so on), and deepening my knowledge on the things I hope most of you know (root cause is a myth, blaming “human error” is wrong…).
I came across an example that really brought it home to me why the continuous blaming of human error is wrong – not “mean,” not “unenlightened,” but just plain logically ineffective.
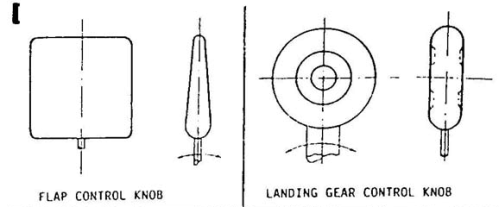
One of the classic examples of design choices contributing to aviation accidents is the similarity and close placement of landing gear and flap controls in an airplane cockpits. Pilots lower the landing gear, then when they land they pull the flaps – but a small miss has them retract the landing gear instead and they pancake in.
In fact, the US Air Force did a study at the close of World War II where they looked back at all kinds of “pilot error” crashes and identified a bunch of design problems that contributed, and the flap/landing gear confusion was #2 on the list, forming 16%
Then, 20 years later, a major study on the same topic
Well, there were very simple fixes mandated to this problem early on – the FAA now requires, for example, the landing gear control be shaped like a wheel and the flap control be shaped like a flap, so basic visual and tactile feedback is available to distinguish the two (especially at night, under stress, etc.).
There’s other simple tricks that greatly reduce these accidents, like putting a catch on the landing gear retraction. Suddenly the “human error” goes away (leading to the reasonable question of how broadly we define “human error…”
So why did this “known” problem persist – damaging planes and killing people I might add – for 33 years? In fact, it still happens, here’s a lovely writeup from 2015.
Basically, because all of the accidents where this happened continued to be declared “pilot error.” When there’s not any significant further inquiry (which to be fair, bothers people like airlines and the government and aircraft manufacturers and people with money), just saying it’s pilot error gets the problem over with by a minor sacrifice (a pilot) instead of doing any harder work.
At my new job, we’re doing risk analysis and commercial insurance for unmanned autonomous vehicles (drones). It’s interesting to now be working in a space that’s actually closer than tech to all this safety research. And you can see the same things happening.
Sure, actual research shows that it’s technical problems, not really human error, that is the problem most of the time – see
News article: More drone crashes caused by technical glitches, not human error, study shows.
Study: Exploring Civil Drone Accidents and Incidents to Help Prevent Potential Air Disasters
It cites technical problems as 64% of the time and frankly doesn’t really distinguish human error from design-induced human error.
But of course you can still just blame human error. I smelled something questionable in the recent news reports of how the crew was to blame for a UK Watchkeeper drone crash. Oh sure, the drone failed to land correctly so the crew intervened, so it’s their fault. I suspect if they had not intervened and it had continued to malfunction it would also be “their fault.” Here’s the full Ministry of Defense writeup, which goes to the “loss of situational awareness” synonym for human error. And here’s a later Register article with more details, like “The most appropriate [flight reference card] drill …stated: ‘If UA [unmanned aircraft] not maintaining centreline axis: Engine cut……..Command’.” and that they were under supervision of contractors from the drone manufacturer. Apparently following the actual designated drill recommendation of cutting the engine still makes it your fault.

Of course, “Five drones – almost 10% of a 54-strong fleet bought from French firm Thales – have been wrecked in mid Wales crashes.” Apparently they have a lot of navigation problems. So when one goes to land in a populated area and is clearly not navigating properly and goes off the runway and the crew cuts the engine… The crash is ‘their fault.’ Riiiiiight.
It’s actually a fascinating question – when drone operations are more and more autonomous, how long can we just hold the “crew” responsible for anything that goes wrong? It’s cheaper and less embarrassing, so I’m betting a good while.
For us in tech this opens up an interesting discussion, beyond the obvious statement of “if you do an incident postmortem and simply write it off to developer or operator error you aren’t doing your job”.
We can’t always fix all design issues immediately. At what point, though, does not prioritizing a better-than-bandaid fix become negligence? “Thirty years,” like with the flap/landing gear thing?
There’s a lot of legislation that tries to protect the powerful from lawsuits etc. – but as autonomy becomes more common, how long will that last for us? Technology firms have managed to get out of being held responsible for endemic security flaws (largely thanks to Microsoft) for decades.
You can see this beginning to crumble in aviation with things like the recent Boeing 737 Max crashes. “It’s human error!” declares the Boeing CEO. But people aren’t that dumb and the Internet helps information get out that was previously inaccessible. So the next tack is blame the software, but that’s also buck-passing… The software was the band-aid fix on top of the design issues.
When will our lovely band of insulation finally be whittled away in tech? Soon, I’d bet… “Oh sure let’s crank out some self driving cars, I’m sure it’ll be fine and we can just give the standard ‘what me worry’ face when our crappy design ends up killing some soccer mom that we use when we mess up a software patch nowadays.”
In the end, if you are motivated by actual safety, or uptime, or security instead of the CYA game of who to blame, you have to push beyond the nearest human, or the outermost band-aid on your Rube Goldberg system, to improve the system. You’re going to have to consider how your design and interfaces of your software and the tooling you use to operate it contribute. You’re going to have to use facts and numbers and not soothing opinions to say “you know what? That goes wrong more than our other systems – there’s something wrong with it, we have to dig in and figure out what.”
