James and I are working on a LinkedIn Learning course entitled “DevOps for Managers” and I wanted to share some of the books we love that we’ve found helpful in preparing it! We’d love to hear books you think are indispensable for DevOps managers. We’ve generally omitted general management books like First, Break All The Rules and DevOps non-management-specific books like Continuous Delivery, trying to focus on the specific intersection of tech and management.
The Lean Mindset: Ask The Right Questions by Mary and Tom Poppendieck shows how to focus your thoughts and iterate towards good products, including your internal products and services.
I’ve heard about Camille Fournier’s The Manager’s Path, Julie Zhuo’s The Making of a Manager, and Lara Hogan’s Resilient Management but haven’t read any of them yet so can’t vouch.
Well, after ten years of running DevOpsDays Austin, James, Karthik, and I feel like it’s time to let a new generation of leaders have a crack at it!
DevOpsDays Austin 2023 planning is underway with a great organizer team – some experienced, some new. I’d like to introduce your new Austin core organizers to you!
Laura Santamaria is a Lead Developer Advocate at Dell and a long time supporter of the Austin tech user group scene, who’s been involved in running Austin DevOps and CloudAustin.
Daria Ilic is Director of People Operations at Six Nines IT (working with me, yay!) and has been an organizer for DevOpsDays Austin and CloudAustin.
Shaun Mouton is a Principal Software Engineer at Mastercard and has been an organizer with DevOpsDays Austin for many years.
All three are great people and we really look forward to seeing how the event continues to evolve under their able leadership! They’ve put together a great organizer team and are full speed ahead, so make sure and buy those sponsorships now and submit talks when they open up!
We also send out retrospective surveys to our attendees, speakers, sponsors, volunteers, and even our fellow organizers to find out how we’re doing and get an idea of what we should do better on (or keep doing) in the future!
To sum up, however, it’s looking good! Our last surveys were from 2019, from our last pre-pandemic DevOpsDays Austin, so we have a previous number to compare to.
Our attendee NPS was up to 77 (44 responses) from 62 (50 responses). And the things people loved were, basically, the personal interaction. Community, people, discussions, and openspaces were the most cited positives by far. We knew people had been missing that for a couple years now so our retrospective format and event plan were specifically designed to promote small group interactions.
The gripes were more varied. Primary was the food, which is fair enough. While we don’t intend to change from a boxed lunch format – it leaves so much more time for the actual conference, so we left fancy catered lunches behind long ago – we were forced to use the venue caterer and they ran out of food especially veggie options, and we had asked for breakfast tacos both mornings and on day two the breakfast was what I can only call “leftover meat bits.” So room for improvement, with the understanding that boxed lunches are here to stay, but we’ll definitely see what we can do about better options and especially making sure there’s not shortages of anyone’s dietary needs.
The other leading concern we’re just plain going to ignore, and here’s why. It was “the retro format – but what about technical talks, what about content for newbies?”
At DevOpsDays Austin we explicitly reject the assumption that all events must be the same generic thing every time. We specifically change our format every year. We’ve had the Monsters of DevOps where we went for flying in big keynoters (including all the authors of the DevOps Handbook) and doing everything up huge; we’ve had DevOps Unplugged where talks were voted in on site and there were no sponsor tables. This year we had a “class reunion” format with talks only being 20 minute “retrospectives” from what the speaker’s learned over their time in DevOps (some speakers were experienced, others were new voices). We very, very clearly talked about this format on our website, social media, and emails to attendees and sponsors. In the end, people just don’t read, and there’s nothing really to do about that. And we won’t be doing the retro format two years in a row, we’ll keep mixing it up!
Organizer feedback was good (we have 20 organizers), up slightly, with everyone enjoying working with the group, and some concerns about unclear roles and roles already taken. That’s always a challenge – we have a lot of organizers but not all of them are up to actually leading something. We have people volunteer to own roles and then encourage them to reach out to the others/the others to chip in when we need something, but that doesn’t always go well, which is frustrating for everyone. In the end, most roles need someone who can commit to consistent participation over the planning period (there’s a couple specialty roles like making signage that can be backloaded, but not many). But we want to be inclusive and not tell people “no, take the year off if you can’t be putting in a couple hours a week including making the organizer calls, and truly own something.” We’ve wrestled with this for 10 years, no clear answer is in sight.
Speakers love speaking at the event. NPS was 92, slightly up from 90 in 2019. They love the audience, how supportive and welcoming they are, and how low stress and chill the experience is. There’s always some AV issues as a fly in the ointment – we do AV checks but not everyone shows up for them.
Volunteers have a good experience too. NPS was 88, slightly down from 94 but still good; we try to make sure that the load isn’t too much on any given volunteer so they can also enjoy the event. Posting the openspace topics is always a challenge each year; we tweet out photos and then desperately type them into the sessionize, but a bunch of attendees are social media impaired I guess and it’s hard to get the schedule to everyone, but there’s not a lot of options given that openspaces are predicated on doing the agenda immediately previous; I’m not sure more time would help short of printing out copies or having live monitors everywhere.
Sponsor feedback was down from 60 to 50 NPS. They do like the audience and authentic content. The main problem was the new venue and unclear flow meant that the platinum sponsor rooms were more out of the way than we’d planned (we gave them tables in the gold area as well once this became clear). And then the general sponsor gripes about it not being a good lead gen event. We always tell sponsors this is a good participation event, not a good lead gen event, no badge scanners, no sponsor list, etc., but a previously mentioned people don’t read, plus the teams being sent out aren’t the people buying the sponsorships and often just assume they’ll be getting a standard conference experience. We sell out every year so I’ll worry about it when that stops.
There’s one other thing worth mentioning, which is that we did require masking at the event and asked people to either be vaccinated or test prior to the event.
One the one hand, a couple sponsors and attendees griped about the masking.
On the other hand, despite other events resulting in superspreading (Kubecon EU, RSA, even some DevOpsDays events):
So, with all due respect, we are very happy with our choice and that we had a safe event. No one likes wearing masks. If you don’t like it enough to not come – don’t come. Hopefully it won’t be necessary next year.
Everything was pretty good! There was one issue, though – in all the survey sub-questions, there was a drop in the perceived friendliness of the organizer team, so we’re going to make some changes there – stay tuned to hear what!
We were psyched to be back and meeting in person for DevOpsDays Austin 2022 this year! Charitable donation is a part of our Austin tech culture and very important to us, and since it was our 10th anniversary we aimed to hit a total of $100,000 in charitable donations since we started the event in 2012. And we did it! We’re happy to have $28,000 to give to local charities after our event this year.
That left us with the question of who to donate to. We like to choose things that fill the greatest need in our community at the time, and strongly bias towards supporting Austin area charities. Our state government decided to help us make our decision by starting a pogrom of discrimination against LGBTQ+ Texans.
Many of our colleagues in the Austin technology community are gay, lesbian, transgender, nonbinary, or identify with other nontraditional gender identities and sexual preferences, or have family members that are. I myself have a transgender son who I’ve loved and supported through his transition, and now he’s a happy, healthy adult. We find the attempts of the Texas government to institutionalize hostile behavior towards them deeply unacceptable and want to find ways to support them.
We looked initially at charities like Equality Texas that are working to ensure the rights of LGBTQ+ Texans, but as we discussed we wanted our funds to go directly to the benefit of people in need, and not all go to the lawyers fighting the long fight.
Since $28,000 is a lot, we decided to split it up into two $14,000 donations. After some research we nominated two recipients, Out Youth and The Trevor Project, and brought them to the DoDA organizer team for a vote, which they enthusiastically approved.
We selected Out Youth for our first donation as a deeply local Austin organization directly supporting LGBT youth.
For 32 years, Out Youth has supported Central Texas LGBTQIA+ youth and young adults by providing safe places where they are loved, acknowledged, and accepted for exactly who they are. Their life-saving and life-changing programs and services ensure these promising young people develop into happy, healthy, successful adults. Out Youth hosts a variety of programs to keep their youth mentally and physically safe such as drop-in times at their youth community center, by offering free individual counseling and group therapy sessions, and through their in-school-support services. To find out more information about ways to get involved and about their services, please visit outyouth.org today.
It’s funny that our relationships with these charities usually start with us showing up with a big surprise donation and then after that getting deeply involved with the organization; we plan to go tour their house and spread the word about volunteer opportunities with them to the Austin technology community.
Not only do I have a transgender son, but also fellow Agile Admin and conference organizer James lost a brother to suicide. So while The Trevor Project isn’t Austin based per se, it does help many Austinites, and its mission of suicide prevention among LGBTQ+ youth is deeply and personally meaningful to us both. Therefore we chose them for our second donation this year.
The Trevor Project has worked to save young lives by providing support through our free and confidential crisis programs on platforms where young people spend their time — online and on the phone: TrevorLifeline, TrevorChat and TrevorText. We also run TrevorSpace, the world’s largest safe space social networking site for LGBTQ youth, and operate innovative education, research, and advocacy programs.
The Trevor Project’s research has found that having at least one accepting adult in an LGBTQ young person’s life reduces their risk of suicide by 40%.
Transgender and nonbinary youth who reported having pronouns respected by all of the people they lived with attempted suicide at half the rate of those who did not have their pronouns respected by anyone with whom they lived.
“You are lovable” – this is one of the most common phrases The Trevor Project’s crisis counselors share with youth in crisis.
According to Trevor’s research 42% of LGBTQ youth seriously considered attempting suicide in the past year, including more than half of transgender and nonbinary youth.
You can sign up to become a volunteer counselor on their site; there’s extensive training and it requires a year commitment.
In closing, we appreciate the work Out Youth and The Trevor Project are doing and hope that others will look into finding ways to support them as well.
To the LBGTQ+ technologists in Austin, you are welcome, and both DevOpsDays Austin and other user groups we run like CloudAustin have published codes of conduct that don’t allow any hostile behavior towards you at our events, and we look forward to interacting with you there. Happy Pride Month!
Hey all! There are some stories that were foundational in my path to DevOps that I think illustrate larger issues pretty well. I use them a lot when I do talks or whatever but I figured I might as well put some of them down here to inspire readers.
I was working at National Instruments in the IT department back in the early 2000s. I ran the Web Systems team, alongside a bunch of technology focused teams – the UNIX Admins, the Windows Admins, Notes Admins, Network Admins, DBAs, and various others.
It took 6 weeks to get a new server for the Web. We’d say what we wanted, but then the UNIX admins would spec it out, and then order it from Dell, wait 2 weeks for fulfillment, then it’d come, then the network team would rack and jack it in the server room, the UNIX admins would put the OS on it, various other teams would get their pound of flesh, and then eventually it would get sent to us so we could put our software on it and then let the app teams use it. Not exactly quick turnaround.
Then came VMWare, the shining new star! Their sales rep showed up and said “You know, you can have a new server in 15 minutes.” We went out to a live sales demo and were like “this is very cool.” I asked the sales team, “so I could make the root read only for security reasons and write everything to external storage right?” They thought a minute, never having considered that. “Yes? That’s actually a really good idea.” A coworker and I fist-bumped each other.
Anyway, so we bought it, yet another technology vertical team was formed to own it, and after some degree of enterprise folderol it was in place.
So now when I needed a new server, guess how long it took me?
Four weeks. All we had removed was the 2 weeks of Dell fulfillment. Not 15 minutes.
When the procurement was slow anyway, it was just kind of accepted that 2 weeks turned into 6 weeks in the process. “Well, someone has to carefully assign an IP address, or else everything would be chaos!” But then when it was 15 minutes turning into 4 weeks purely based on our own internal friction (the actual work involved being much less than a day end to end) – suddenly it became clear how much of our own problem we were generating.
But it was hard to fix. There is inevitably niche protection in an environment like that. “Hey UNIX admins, you put cfengine on the boxes to manage them? Can we use that to load on our software too?” “No.” “Hey, can we get our own Web DBA so Web initiatives aren’t always bottom-feeding off the big ERP initiatives?” “No.” Tossing a ball over walls from silo to silo inevitably resulted in complex handoff processes and wait times and resource contention.
So then when we moved to the R&D department and started working up some SaaS products, and we were faced with the option of using our own integral IT department – we said “Absolutely not. There’s this new Amazon Web Services thing and we’re going to do it all ourselves.” “But what about all the value those specialists bring?”
Well, it’s not the specialists’ fault – but the one day worth of specialty benefit they brought was stapled to 4 weeks of sitting on hands, and no one felt it was their role to fix that endemic process problem in the org. I don’t care if you’re offering me Linus Torvalds to fix my Linux problems, if you offer me “a day of Linus and then 4 weeks in solitary,” I’ll do without, thank you very much.
This was 2009, it was before “DevOps,” but we immediately realized that having a product team responsible end to end for the product – code, systems, security, etc. – allowed us to deliver high quality in a fraction of the time that we were used to. It was intoxicating. That’s actually where we Agile Admins met and why we still hang out together today, because we all went through the experience of the gig actually becoming fun again!
DevOpsDays Austin believes in supporting the local community that supports us, the techies of Austin. As we’ve grown and we’ve been able to end some of our years with extra money from our sponsors. We are careful to be thrifty with the event and rely on our volunteers to do a lot, and all DevOpsDays events run on a nonprofit basis; one of the few core rules of all DevOpsDays is that the events are not for individual or corporate profit.
The Austin technical community is a cross-section of, and part of, our community. We have a diverse set of individuals from many backgrounds and neighborhoods all around the area. As technologists we are largely blessed with decent salaries and technology companies have lots of money, and many of the keenest needs in the area need relatively little funding to make a real difference. We believe it’s our responsibility as a part of the community to use part of what we make to give back to support the most vulnerable among us. Therefore we’ve made it a point to use our excess funds to give back to charities that directly help those most in need.
We started DevOpsDays Austin in 2012 from nothing, and relied on a free venue (courtesy of my employer at the time, National Instruments). We made enough to make a down payment on a venue in 2014, and by 2015 we were confident enough of our finances that we considered our first charitable donation.
The Charity Page In Our 2022 Yearbook
The natural choice was the Central Texas Food Bank (at the time, known as the Capital Area Food Bank), a well known long time Austin charity that combats hunger in the area. We gave $5000, and we also did a charity drive at the event, handing out leftover t-shirts and swag from the previous two years to those who made a donation of their own, which sent another $2600 to the food bank.
In 2016 we moved to a new, larger, much more expensive venue (the Darrell K. Royal Texas Memorial Stadium out at UT Austin) so we could let more people attend DevOpsDays. That put us at the limit of our finances for a couple years, especially with our 2017 “Monsters of DevOps” blowout conference with many international speakers and great fun events. But by 2018 we had that venue dialed in as well and had $20,000 left over that we decided to donate to charity. That year, instead of sending all the donation to one charity, we let each of our 20 organizers send $1000 to a charity of their choice. This ended up driving our helpful accountant Laura at ConferenceOps batty trying to get proper tax receipts from everyone, however, and we promised her we wouldn’t do that again.
Then in 2019 we had a great event, sponsors were in a right frenzy to get in and we had to add more sponsor booths to accommodate them – which was a lot of work, but left us also with a lot of leftover money ($25,000, off a conference with only a $200k total budget). We weren’t sure how we could be the most effective with a gift like this, and one of our organizers said “Did you know… There’s a new project here in Austin that builds miniature houses for the homeless in a beautiful community?” And that’s how we were introduced to the Community First! Village, a quickly growing and very effective outgrowth of Mobile Loaves and Fishes to house the homeless. And it turns out $25,000 is exactly how much it takes to build one of those homes. Our organizers enthusiastically approved the donation and we went out and did a great tour of the site, and many of us have returned as volunteers since.
And then the hard times came. During the pandemic, DevOpsDays Austin was on ice. In fact, we had planned on moving to an even more expensive hotel venue and had a down payment in place when the lockdown came, and we had to get a lawyer into play to get our deposit back.
But the needs of the community weren’t on hold. We have many Black and brown technologists in our community, and the high profile brutality directed at them was completely unacceptable. Long time friend of DevOpsDays Austin, John Wills, started a fundraiser for Black Lives Matter around making a quilt with all his DevOpsDays shirts (many of which were from Austin) in 2020, and we felt compelled to donate $2000 of the more than $12,000 he raised.
DevOpsDays Shirt Quilt
Then we were in the long night of lockdown. We weren’t doing anything from a DevOpsDays Austin perspective in 2021, though there was a virtual DevOpsDays Texas conference to fill in some of the gap. But as jobs and aid dried up, hunger became a critical need again in Austin. Fellow organizer Boyd Hemphill encouraged people to help out and volunteer during a virtual meetup, and his words made my conscience burn till I brought it to my fellow DevOpsDays Austin organizers to see if we could dip into our reserves and help. They all enthusiastically approved a $10,000 donation to our old friends the Central Texas Food Bank again.
Two donations without any revenue, that’s good enough till we can have an event again, right? Well, you’d think, and then Russia went and invaded Ukraine.
While we’re an Austin organization and we’ve always given to help out in Austin directly, we have many Ukrainians as part of our local tech community. I worked with many of them hand in hand while I was running teams at Bazaarvoice, as we had a great relationship with the Ukrainian consulting company Softserve. We brought many of them here to Austin to work with us, we went out together, I had toasted them with “Slava Ukraini!” Many of our organizers had similar experiences. And since we don’t like bullies around here, that riled us up. After a discussion along the lines of “well, we started from nothing once, we can do it again if we have to,” we donated $10,000 to Ukrainian relief organizations Razom for Ukraine and Nova Ukraine.
And that brings us up to date with the past, but we finally managed to have DevOpsDays Austin again! In May, we got a great venue (the University of Texas Alumni Center, at half price courtesy of Bill our venue lead being an UT alum) and planned for a slightly smaller than usual (350 masked attendees, to hedge against super-spreading) conference on our 10 year anniversary – the DevOpsDays Austin 10 Year Class Reunion.
Since it was our 10th anniversary, we did a yearbook. And when I put the charitable donation page together for the yearbook, I realized we’d given $72,000 to charity over the years. 10 years and an even $100,000 sounded mighty nice.
The conference went great, and all those sponsors have been saving up their marketing money wondering what to do with it. After some laborious running of numbers I realized we could free up the $28,000 donation to get to that bar and leave enough for us to make a venue down payment the next year.
As we contemplated this year’s donation our Texas state government decided to openly attack the LGBT+ citizens of our state. Many of those in our technical community we meet with every month in user groups are gay, lesbian, transgender, binary, and so on, and this is a direct attack on many of our coworkers, colleagues, and friends. And not just them, but their children.
As a result we gave $14,000 to The Trevor Project, a national service that provides suicide prevention hotlines for LGBT+ youth, $14,000 to Out Austin, a local place for youth of all sexual orientations and gender identities. I’ll write a separate post about those organizations and why them, and more importantly how you can help.
But in the end we’ve been very happy that we’ve been able to use our position as techies in the tech hotspot of Austin to consistently give back. We’d challenge other conferences, tech companies, and individual technologists to do so as well – especially to reputable charities that directly help those who need it.
I hope that DevOpsDays Austin can continue to give back in this way over the next ten years too!
Well, we had to skip 2 years in a row due to the pandemic, but we were finally able to have DevOpsDays Austin in person again in 2022! It’s our tenth anniversary of DoD Austin, we had the first one at National Instruments back in 2012, one of the early DevOpsDays in the US.
We had to move to a new venue, and used the beautiful University of Texas Etter-Harbin Alumni Center (our site lead Bill is a UT alum which makes it half price!). The Etter-Harbin Center is right across from the stadium where we had DoDA in the years leading up to the hiatus. It has plenty of great outdoor spaces, which we used for lunches and happy hours, as well as a great main ballroom with views of the outside. It worked great for our target of 350 attendees, and we think we could make it work for more in the future.
Etter-Harbin Alumni Center
We were thinking and came across the perfect theme – it’s our tenth anniversary, and we’re just back from the pandemic, and DevOps is also just a little more than ten years old and at a weird inflection point that has people asking “is DevOps dead? Where does DevOps go from here?” So we decided that since we were also in the Alumni Center, the obvious theme was our 10 Year Class Reunion!
We don’t take our themes lightly at DevOpsDays Austin. We settled on a new theme for our talks – instead of the normal RFC for whatever technical and culture topics, we required all talks to be a retrospective format – reflecting on what you’ve learned over the years of DevOps and what you think the future holds. We had lots of great speakers, many of whom are long time parts of the DoD Austin community, both locals like Rob Hirschfeld, Christa Meck, Ross Dickey, and Victor Trac, as well as folks from other parts of the Earth like Patrick Debois, Damon Edwards, J. Paul Reed, Pete Cheslock, and Michael Cote, who all frequently come to Austin to share with us.
And we printed a yearbook, with pics of speakers from all the events, our tshirts over the years, and more! Very snazzy, and we had people sign each others’ yearbooks to add some fun to the hallway track. In fact, you can view the yearbook online and buy a hardcopy here if you want!
The DevOpsDays 2022 Yearbook
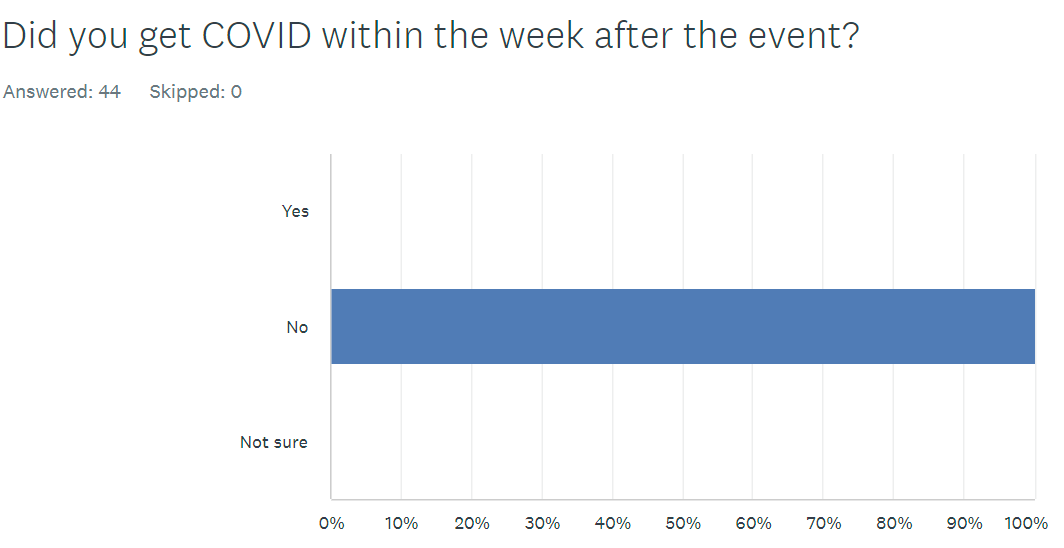
We did require COVID protocols – masking inside and (honor system) vaccine or test, and while it is a bummer to not see each others’ faces, it also resulted in only one person I know of getting COVID the week after, so well worth it.
We didn’t have to worry about sponsor interest! We sold out quickly. Here’s the ones I got snaps of!
Our Sponsors
Everything went great, and it was super to finally get back together and interact with our local DevOps community. J. Paul Reed led a great session where a retro was done on DevOps in general!
And one of the best things is that we managed to carry on our tradition of giving our excess proceeds to charity! I’ll do a separate post on that, but the short form is that we contributed $28,000 to LGBT-supporting charities, half to The Trevor Project and half to Out Youth here in Austin, bringing us to $100,000 given to charity over our 10 years in existence! Stay tuned for more details on that…
Hello Austin area tech professionals, and happy holidays. We weren’t able to have DevOpsDays Austin in 2020 due to the pandemic, though we did manage to get our money back from our venue and refund all the attendees and sponsors fully. But what’s going on with DevOpsDays Austin now?
OK, the bad news up front – we don’t believe we will be having DevOpsDays Austin in 2021. Given the current projections of the pandemic, vaccine distribution, remaining unanswered questions about how long social distancing measures will be required (through the summer at least, longer depending on how many anti-vaxxers are literally infecting our society) and the 6 month lead time required to book venues and plan and execute a show like DoD Austin, we are not going to have our usual event this year, instead planning to come roaring back with a big, fun 10th anniversary DoD Austin in our usual May time slot in 2022.
We don’t want DoD Austin to be the “first one out of the gate” to test large events. The organizers (who are also involved with various smaller events and user groups) will be staying on top of things to have smaller gatherings later into 2021 to gauge risks, response, and so on.
But, there are two pieces of good news.
The first is that since Houston, Dallas, and Austin are all in the same boat, in March of 2021 there will be instead a DevOpsDays Texas virtual conference! Some of the organizers from those three cities are banding together to try this out, with Discord-based openspaces and all kinds of innovation, based on how the team with Matt and Sasha and folks put on DevOpsDays Chicago virtually this year. Ticket sales and CFP are open, so if you are hankering for some Texas style tech, that’s your hot ticket in 2021!
The second is that DevOpsDays Austin is donating $10,000 to the Central Texas Food Bank to help fill the dramatic need the pandemic has inflicted upon our community’s families.
A little story time on this one. We hadn’t thought about doing anything at all this year in terms of DevOpsDays Austin – we are still a little touchy after having to bring lawyers into play to get our venue money back when we couldn’t have the event due to COVID, and we ran a real risk of getting completely busted out this year. So in our minds we’re just sitting hard on our nest egg waiting for winter to lift, and with our (and everyone’s) next event more than a year away to be honest DoD isn’t the top of our list of things to even think about in a given week.
But one of our DoDA organizers, Boyd Hemphill, also runs the Austin DevOps meetup, and their meetup joined our CloudAustin meetup this year for our annual “12 Clouds of Christmas” lightning talk event (also being held virtually for the first time ever). During the announcements he made an impassioned plea for people in general to help out their local communities by donating with their time, treasure, and talent; even in the relatively affluent Austin suburb of Pflugerville they are distributing food to hundreds of families a week now through his church and network of local charities because the need is so high right now.
Over the next couple days, Boyd’s words continued to sear my conscience in an attempt to spur me into action. I finally resolved that while it was lean times for DevOpsDays Austin as well, that while it’s easier to give in fat times than in lean, the need is most in the lean times. So I took the idea to James and Karthik, my fellow core organizers. They went through the same cycle I had, from “But there’s a lot of risk and uncertainty and we just fought to get that money back” to “This is totally the right thing to do” in a short amount of time.
We already had a DoD Austin organizer meeting scheduled for last Friday, to touch base after a long time apart and talk about our plans and come to terms with “no 2021” and “plug into DoD Texas if you want to help with a virtual event” and all. This is a big financial decision so we brought it onto the agenda and put it to the whole organizer team to vote, and everyone was extremely in favor. Boyd was there and was surprised by it too, having no idea what his words had set in motion! Someone noted “we started DevOpsDays Austin from $0 before, we can do it again if we have to.” Luckily this isn’t busting us out and we’ll have enough for a venue down payment in 2022, but the sentiment is appreciated.
So I wanted to thank Boyd for the spark, all the DevOpsDays Organizers for setting the fire, and also all our previous DevOpsDays Austin organizers and attendees for providing the fuel. We really appreciate all the participants in our local tech community and love its passion for giving back and helping Austin and the surrounding area.
This morning I spoke to a lady from the Central Texas Food Bank and she said that donations are currently being tripled due to matches from a new donor that just came on, their Web site only says doubled but even getting your Web site updated promptly is difficult right now during the holidays and a pandemic!
In closing I’d like to encourage you to also consider if you can help others right now as well. It’s hard times, but we in tech are mostly pretty well off; there are many unemployed or having to work hard, public jobs during a plague to make ends meet. The generous nature of the Austin tech scene is one of the best and most distinct things about it – the sharing, collaboration, and openness are what makes it better and stronger IMO than some other areas’ tech communities. Help keep Austin weird and help your fellow humans this holiday season!
And James, Karthik, and I are hosting the Modern Infrastructure track again this year! ADDO is a free, 24 hour, multi-track online conference with a lot of great speakers. More info follows…
On November 12th, we will be supporting the 5th Anniversary Celebration for All Day DevOps. This is a 24 hour event with 6 simultaneous tracks, delivering 180+ sessions, live online. Session tracks include CI/CD Continuous Everything, Cloud Native Infrastructure and Monitoring, DevSecOps, Cultural Transformation, Site Reliability Engineering and Government.
Virtual Viewing Parties: Hosting a virtual viewing party is free for anyone in the community you supply the group and the connection while All Day DevOps provides the content. Here are some guidelines that will provide detailed information and tips to assist you with your party planning.
Hey loyal admineers! (I just made that up.) I wanted to toss a question out to our readers. I’m working on a Change Management course for LinkedIn Learning right now to join my other courses, and I was hoping to hear some good new techniques people are using to do it that a) ensure compliance but b) are not super heavy and lame.
My current approach is to mention the ITIL, COBIT, ISO 27000-1, etc. approaches but then come in with a practical approach inspired by Visible Ops and leavened with DevOps innovation.
Chime in in the comments – how do you do change management? What compliance regimes do you have to fulfill? Are you using one of the ITSM frameworks? Are you using a tool (ServiceNow aka “ServiceNo” followed by JIRA were the two most popular when I asked at the latest CloudAustin meeting)? Are you using any techniques that you think are excellent and would like others to hear about? I’d love to hear from you!