I’m working for a startup right now and we don’t have a huge excess of development staff. Our devs have been implementing UI testing in Cypress, but we also need some wide cross-browser testing of our front end Angular apps – we’d already found a couple blocker bugs on Edge and IE largely by accident. The devs are all busy devving, so I figured I’d take that on. I said, “Well, there’s products where you can just click to record a UI session and replay it in other browsers without writing a bunch of code, let’s try that out.” Most everyone has a free trial nowadays so I could see which ones were best. Then the pain began.
Sauce Labs – Part 1
I had used Sauce in a previous life, when we had a bunch of Robot Framework/Selenium tests and I liked it. So I went there first. Unfortunately, they have no record/replay capability, verified by their support, so I moved on.
But I came back later because I had found that there was a Selenium IDE that’s a record and playback tester that you can integrate with Sauce by using selenium-side-runner.
Selenium IDE is very cool, its killer feature is that as it records it copies various ways to address an item on the screen – css, xpath, full xpath – and when it replays if the first one doesn’t work it tries the next one and if that works tells you “hey you should update this test.” That’s great because UI testing is shitty and unreliable at best, and once you have Angular generating ever-changing ids for elements it is even worse. The only bad thing is you have to go add assertions in manually afterwards.
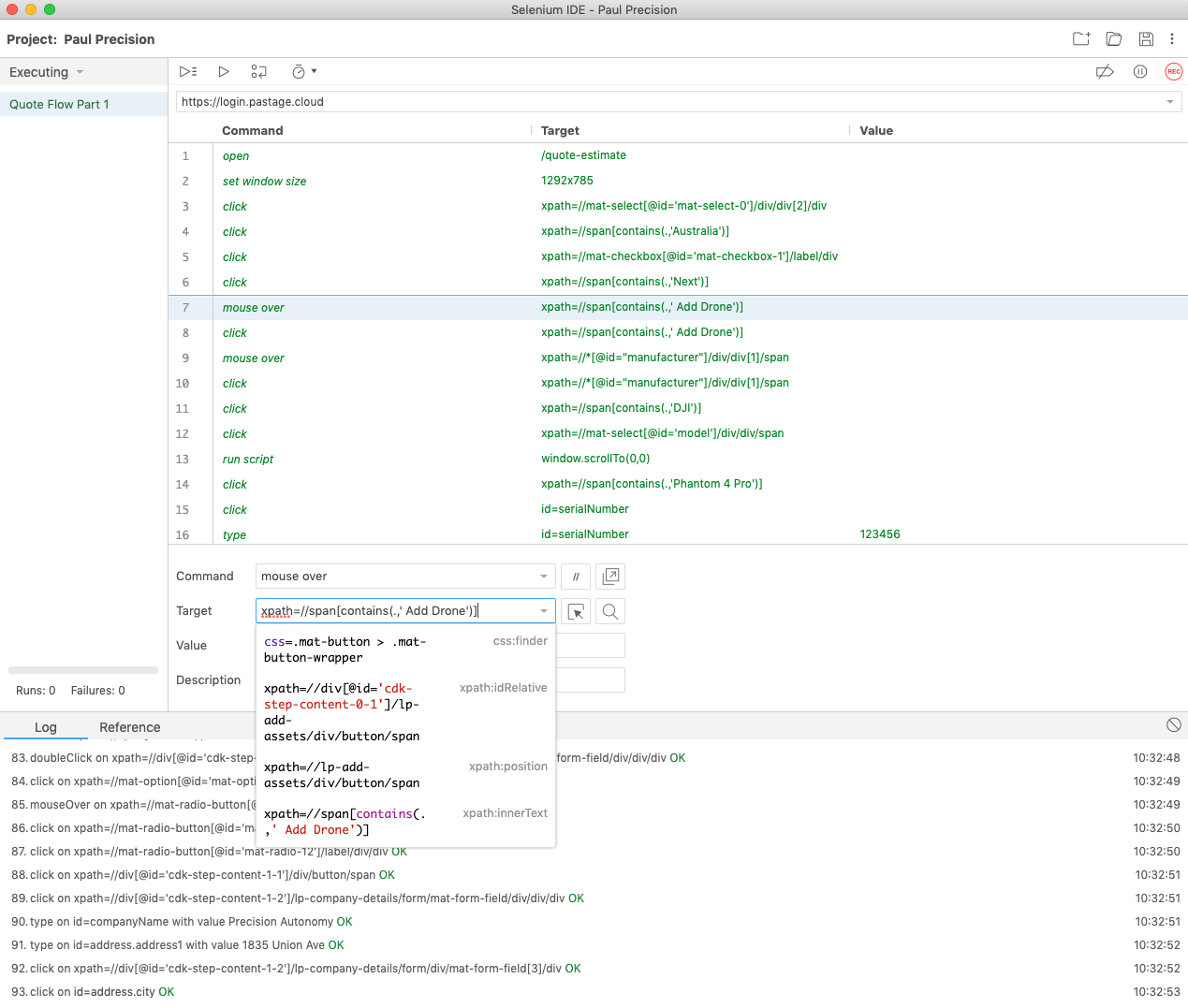
So in fairly short order, I managed to get a reproducible Selenium IDE script that exercised our Angular app and works. The app’s just like 7 screens of form fill, it’s not crazy.
Well, then I tried to save it as a “.side” project and feed it through Sauce by using selenium-side-runner, which is just:
npm install -g selenium-side-runner
selenium-side-runner –server <sauce-url> -c “browserName=’chrome’ version=’latest’ platform=’macOS 10.14′” ‘Paul Precision.side’
You get that sauce URL that has credentials embedded under User Settings/Driver Creation in their UI.
Unfortunately once I push it to sauce (starting on the same OS/browser, which you go get the tokens for from their Platform Configurator) – problems. The player is great, it shows the video (even live while testing) synced to the step taking place (unfortunately since I’m piping it in, it’s not showing the steps in the test syntax, but in raw Selenium execution syntax).
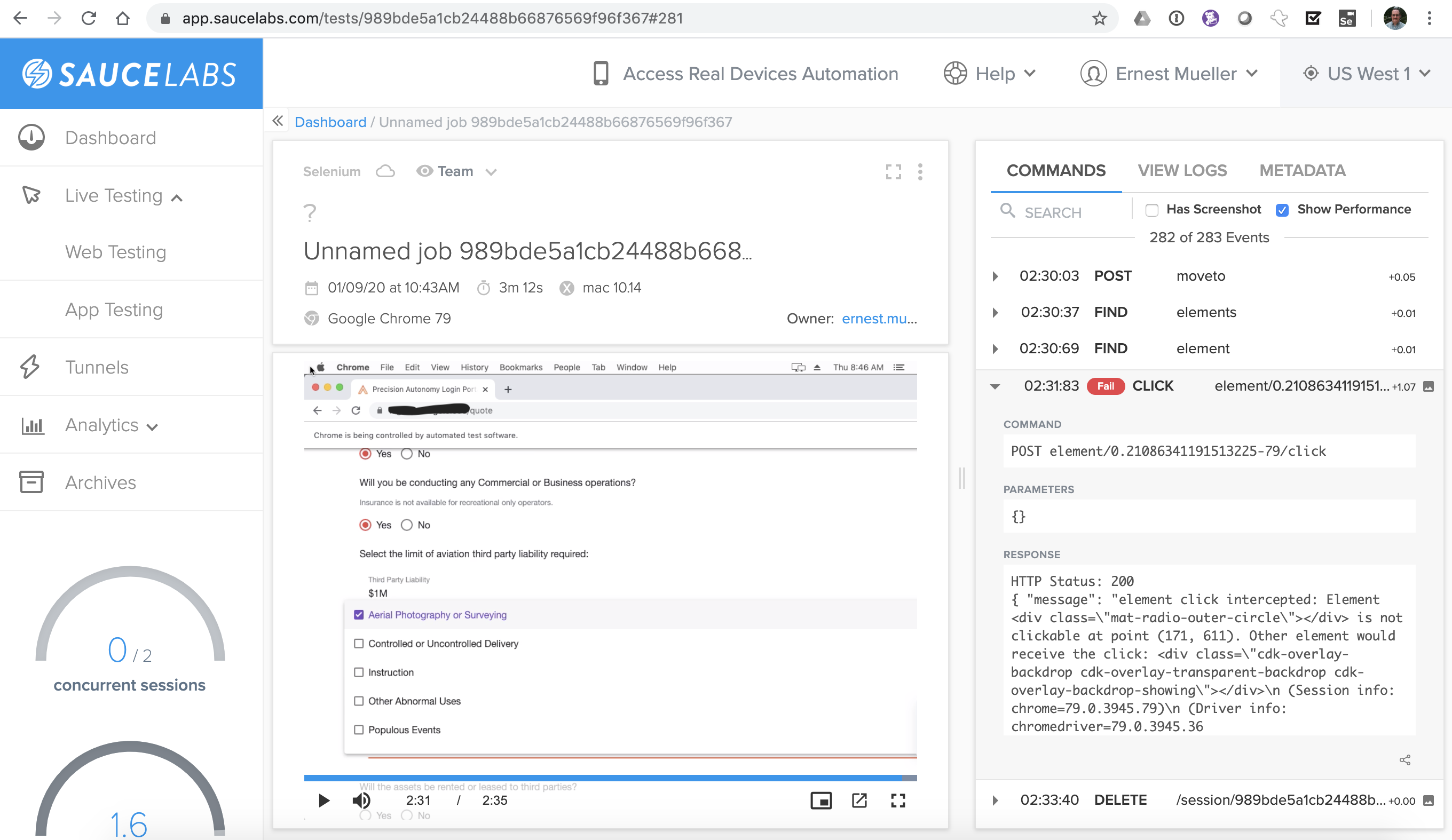
I fixed most of them by going and changing selectors away from CSS to xpath, then sitting there iterating with chrome dev tools and the IDE trying new ways to use an item that works in chrome then works in selenium IDE and then… Doesn’t work on Sauce. I have gotten it 90% working but the last 10% is blocking me.
CrossBrowserTesting
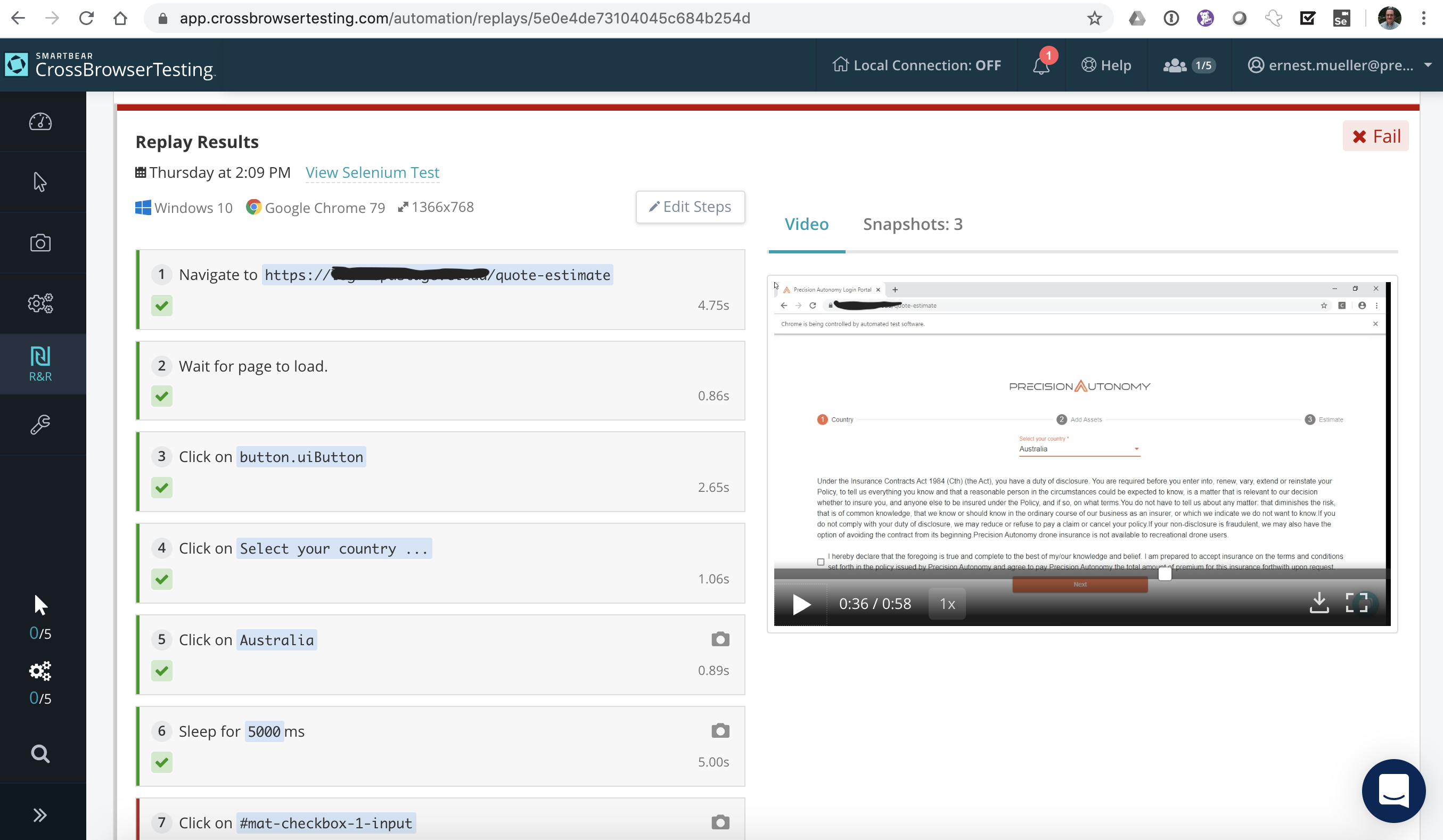
Next I tried SmartBear’s CrossBrowserTesting.com. An all-in-browser recorder that worked great! And then the replays didn’t work. I messed with it a while and contacted their support, who said “Oh yeah it doesn’t do angular, it’s for static pages.” So on to the next one. Who uses static pages, this is 2020?
The interface is nice enough, editable steps next to a running video (though not synced up).
Actually looking at it closer I bet I could do the same “edit all the locators” deal and try to get it to work but… My 7 day trial is over (a week shorter than the other options) so I guess I can’t try. It didn’t do the nice multi-locator guessing Selenium IDE did but it does seem to have several options in a dropdown while I edit the tests, and the recorder is integrated into the offering so that’s nice – the UI was good overall. Unfortunately the super short trial and the presales support saying “Angular? Go away!” prevented me from really seeing if it can work for us.
GhostInspector
Demoralized, I head to Twitter, and someone recommends GhostInspector. You record it with a Chrome plugin and then replay in the browser – video, but then it shows the editable steps next to a screenshot showing % change from the last screenshot (the steps aren’t synced to the video, which would be better) . You can do assertions while you’re recording. And the replay works the first time and every time – Hallelujah!
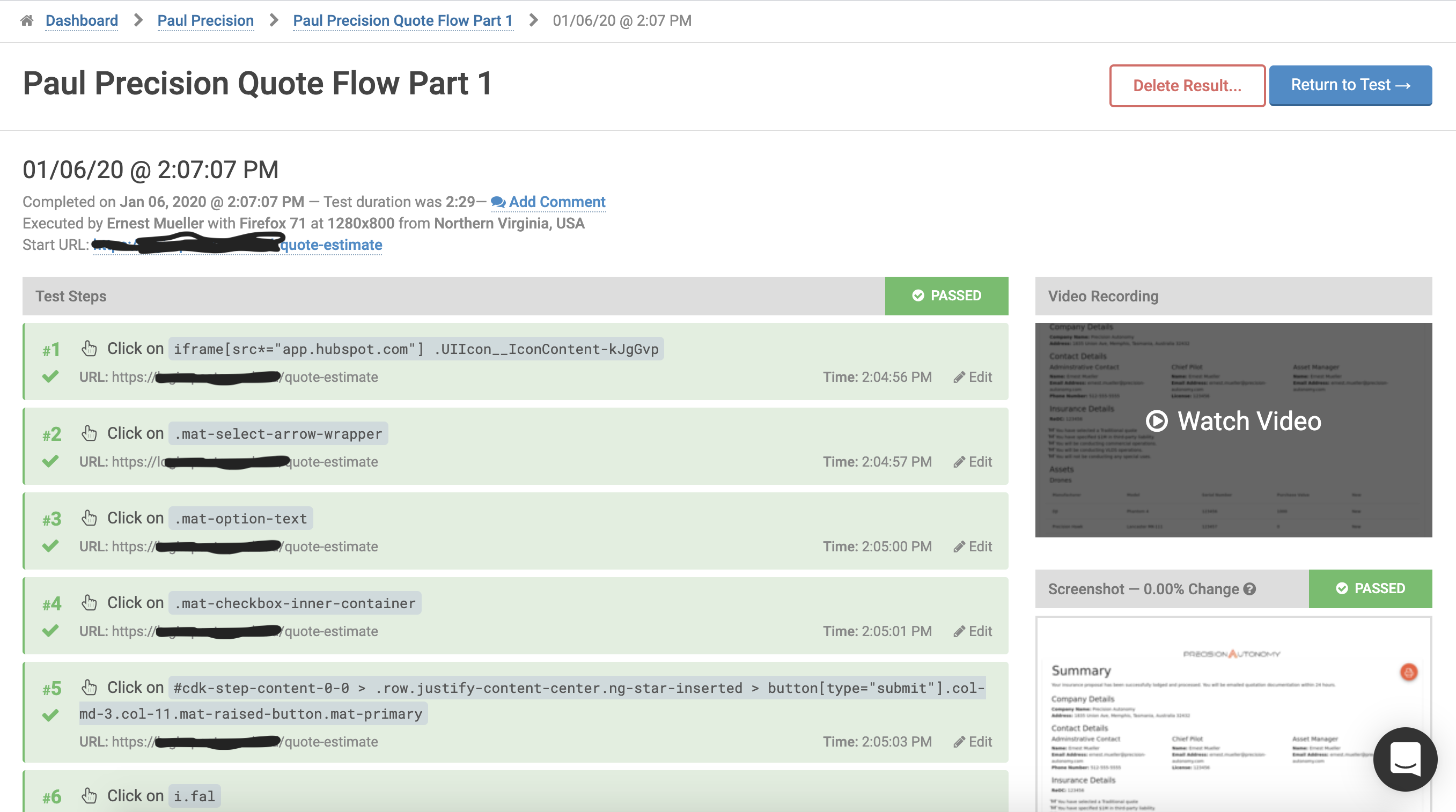
And then I look to set up cross-browser and discover they only support Chrome and Firefox, and to even do that in an automated manner you have to duplicate the entire test suite. I was so disappointed, it worked perfectly otherwise.
Seriously y’all if you add more browsers I’ll pay you immediately for this.
EndTest
Determined to make this happen I find EndTest and, after verifying they support a full OS/browser matrix, try them. They also use a browser plugin recorder like GhostInspector.
I’ll be honest, the UX is terrible. Besides the 1990s colored icons, everything is always a click away – you have to watch the replay video separately from looking at the logs from looking at the steps from editing the steps. Everyone, the magic combination is editable steps to the left, running video and logs to the right, highlight the step you’re on as it plays. Anything else harms your usability. And also while editing steps you can’t add a step in just anywhere, you have to add it at the end of your 100 steps and then drag it up page by page… And often when you do that you just get “error saving test” messages for no reason. Argh.
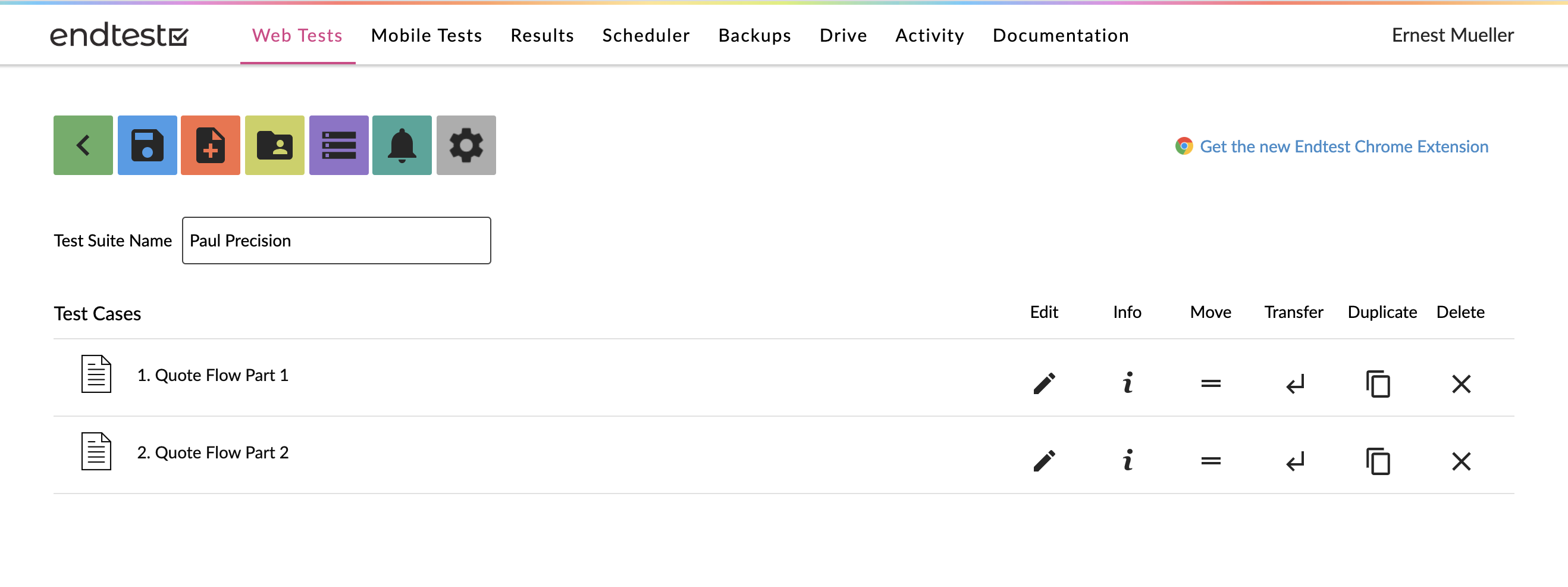
But… The recording is quick and then it is semi working. Tempting. Now I start the iterative edit-replay-debug cycle. It is slow. You get to give your steps a name but those names don’t show up in the test output, because why would they. After an afternoon of fiddling, I’m halfway through a 7 screen flow. Their support was nicely proactive and reached out to me about an error (I was looking for text with a $ in it and you can’t do that, but you can define a variable and then use that…)
It’s at this point I also find the Selenium IDE and bring Sauce back into the mix.
Keep Trying – Sauce and EndTest
Next, what I was doing was fiddling with the steps in the Selenium IDE, then pumping those changes both into Sauce via CLI and manually editing them into EndTest’s UI, desperately hoping to get one to pass (they don’t act the same under the same inputs for whatever reason).
Locator by locator I grind through making the test work. I have a lot of trouble where we use multiple option mat-selects, because they “stay open” while you select items and I can’t get them to close. I try sending ESCAPE keys but can’t get that to work, I try double clicking on other things… One of our devs figured out the magical thing to click on was the overlay backdrop (css=.cdk-overlay-backdrop) to close the damn multiselect box.
This takes several grueling days. I ask support folks for help but don’t really get any useful traction. Finally, I get a magic combination in the Selenium IDE that also works in Sauce! I try the same ones in EndTest and they don’t work.


It’s super frustrating. The same locator doesn’t work in all 3 tools, often forcing me to choose a less portable option – instead of something resilient to change like “xpath=//span[contains(.,’Visual Line of Sight’)]” – which works in some cases – I end up having to use something like like xpath=//mat-option[@id=’mat-option-87′]/mat-pseudo-checkbox (and sadly in angular material those IDs randomize unpredictably). Like, there will literally be two identical-except-for-the-text-and-ids-in-them widgets one after the another and one kind of locator works on the first one and not on the second. No idea why.
Sauce Labs – Part 2
OK, so of all the options the only one that actually works for me and will allegedly do crossbrowser testing is an unsupported combo of Selenium IDE and Sauce run off the command line. A couple sources I found over the course of this:
Not optimal, but at this point I’m a week in and taking what I can get. Let’s try an actual crossbrowser matrix now. Bonus hacky Bash script:
#!/usr/bin/env bash
tests=("Paul Precision.side")
platforms=("browserName='chrome' version='latest' platform='macOS 10.14'"
"browserName='chrome' version='latest' platform='Windows 10'"
"browserName='chrome' version='latest' platform='Linux'"
"browserName='MicrosoftEdge' version='latest' platform='Windows 10'"
"browserName='safari' version='latest' platform='macOS 10.14'"
"browserName='firefox' version='latest' platform='macOS 10.14'"
"browserName='internet explorer' version='latest' platform='Windows 10'")
for test in "${tests[@]}"
do
for platform in "${platforms[@]}"
do
echo Running "${test}" "${platform}"
echo
selenium-side-runner --server https://<secrets>@ondemand.saucelabs.com:443/wd/hub -c "${platform}" "${test}"
done
done
Chrome on MacOS – works. Chrome on Windows – works. Chrome on Linux – for some reason can’t find a selector early on. Edge on Windows – weird proxy 400 error, won’t even load the page. Pretty sure that’s not my fault. Safari on MacOS – can’t click on the first things it needs to click on. Firefox on MacOS – same error? Really? Now IE… Out of minutes (despite the UI telling me .6 automated hours remain).
I have tried all these os/browser combos manually and they work.
So my conclusion is all these suck and I guess I just need to pay manual QA people to click on our app. Great. Or for Cypress to get off their butts and add cross-browser support, which they say “is coming” for three years now.
We’re a startup and time is money, so in the end cross-browser testing is not worth the hassle in all these solutions. But it is important and I’d love someone to make a solution that actually works for it.
P.S. Please do not suggest another solution unless it has a) UI record and replay capability and b) is cross browser (Chrome/Firefox/Safari/IE/Edge on Windows/MacOS/Linux). I know there’s a million browser automation testing tools out there, that’s not what I need.
Update
I put some more time into this and got some working options – see Record and Replay Browser Testing, Take 2!







 The businesses aren’t just for the residents – you can go there to the garage and pay to get your oil changed. You can go attend their movie nights (the Alamo donated a projector) that are open to the public like any movie night in any park. They do things like a trail of lights during the holidays. There’s plenty of reasons for non-residents to go there, it’s not a “camp.” It’s just a subdivision, really, like any other one you’d drive through in Austin.
The businesses aren’t just for the residents – you can go there to the garage and pay to get your oil changed. You can go attend their movie nights (the Alamo donated a projector) that are open to the public like any movie night in any park. They do things like a trail of lights during the holidays. There’s plenty of reasons for non-residents to go there, it’s not a “camp.” It’s just a subdivision, really, like any other one you’d drive through in Austin. Heck, you can go live there. 170 of the occupants are former homeless, but there are also many “
Heck, you can go live there. 170 of the occupants are former homeless, but there are also many “ You can help even by just going there, using the businesses, interacting with the residents to weave them into the fabric of Austin. Go on a tour to see what they’re doing out there. Bring your kids! We all had a great and deeply moving family outing in our visit to the Village.
You can help even by just going there, using the businesses, interacting with the residents to weave them into the fabric of Austin. Go on a tour to see what they’re doing out there. Bring your kids! We all had a great and deeply moving family outing in our visit to the Village. I know we’ve been quiet on the blog, all four agile admins have been busy – several of us moved to new jobs, everyone has a lot going on.
I know we’ve been quiet on the blog, all four agile admins have been busy – several of us moved to new jobs, everyone has a lot going on. And I just went and filmed an Incident Management course. Incident Response, really, I’m hoping for a subsequent course that focuses on retrospectives (each class is only like an hour long and retros are a huge fun topic so I wanted to give them enough time on their own).
And I just went and filmed an Incident Management course. Incident Response, really, I’m hoping for a subsequent course that focuses on retrospectives (each class is only like an hour long and retros are a huge fun topic so I wanted to give them enough time on their own).



 And of course Carpinteria is beautiful, right on the beach, extremely temperate. It’s between Ventura and Santa Barbara, just north of LA. If you go out there, my hot tips are the nearby
And of course Carpinteria is beautiful, right on the beach, extremely temperate. It’s between Ventura and Santa Barbara, just north of LA. If you go out there, my hot tips are the nearby 