
An article I wrote for InfoWorld’s New Tech Forum on all the various monitoring techniques: Know your options for infrastructure monitoring
July 3, 2014 · 2:43 pm
DevOpsDays Silicon Valley 2014 Day Two Notes
Day Two
 First, a public shaming. Some goober from Merantis left this spam on everyone’s car. Bah.
First, a public shaming. Some goober from Merantis left this spam on everyone’s car. Bah.
Presentations
@bridgetkromhout spoke on “how I learned to stop worrying and love devops” and @benzobot spoke on onboarding and mentoring apprentices. DoD SV certainly made a strong effort to get more female speakers this year! We tried in Austin (I personally wrote like every local techie woman group I could find) but we only had like one.
Then there were two super bad ass presentations back to back. I can’t find the slides online yet.
The Future of Configuration Management
Mark Burgess (@markburgess_osl), aka “The CFEngine Guy” and noted Promise Theory advocate, spoke. Chef and Puppet had eclipsed CFEngine for a while but it turns out as the Internet of Things and containers and stuff are arriving that maybe many of his design decisions were actually prescient and not retro. Here it is broken down into wise sayings.
- Why do we not have CAD for IT systems?
- Orchestration is not bricklaying.
- We need the equivalent of style sheets for servers.
- We are entering a world of decentralized smart infrastructure.
- Scale, complexity, and knowledge increase as our desire for flexibility increases.
- Separation of concerns adds complexity and fragility.
- To handle complexity – atomize and untether.
- 3D printed datacenters are coming.
DevOps as Relationship Management
James Urquhart (@jamesurquhart) spoke about the interconnectedness of our systems. The SEC, post flash crash, added circuit breakers, defined rollback protocols, inserted agents into the flow of the stock exchange trading systems to prevent uncontrolled cascading.
One simple rule – visualize the whole system (monitor your outside relationships) but take action at the agent level. “How are you doing today?” “Good.” Monitoring is going well, new approaches in the space look at policies and interactions and performance and business medtrics – but need to differentiate reductionist vs expansionist approaches.
Michal Nygard’s book Release It! is full of great patterns, and Netflix’ open sourced Hystrix is an example of the kind of relational system safeguards you can build off it.
Ignite Block
- Tips for Introverts (at Conventions) by Tom Duffield – They include find a role, don’t fear failure, attend preconference activities, go to lunch early and sit, engage, share interests, find a comfortable setting, take time to recharge. As someone initially introverted myself (no one believes that now) I like that this has actual tips to get past it; in some circles “introversion” has become the new “Asperger’s” as a blanket excuse for not wanting to bother to relate to people.
- Mike Place on scalable container management – Google kubernetes is an example. Don’t just provision your systems, you need to manage them too. Images came and went and came back now, but you also can’t ignore what’s onboard the image. It’s time to join image and config management.
This was really good and the world should listen. On the one hand, conducting CM operations on 1000 servers in parallel is contributing unnecessarily to the heat death of the universe. On the other hand, you need to build those images in a non-manual way in the first place! And too many systems worry about the configuration but not the runtime operation. Amen brother! - Finally (well, there were two more, but I didn’t care for them so took no notes), John Willis (@botchagalupe) did [Darwin to] Deming to DevOps, a burst-fire reading list of nondeterminism tracing from Darwin through various scientists to the Deming/TPS stuff through into the DevOps world with Gene Kim and Patrick Debois. It was pimp. Here it is when he gave it at another venue:
Conclusions
Here’s some big themes from the week.
- Deterministic, reductionist, and centralized are for suckers.
- Complexity is the enemy. Systems thinking is necessary.
- We love continuous deployment. But DevOps is not just about delivering code to production.
- Women exist in DevOps and are cool. More would be great.
- Most vendors have figured out to just relax and talk to techies in a way they might listen to. Some haven’t.
It was a great event, kudos to Marius and the other organizers who put in a lot of work to wrangle 500 people, nearly 30 sponsors, food, venue, and the like. If you haven’t been to a DevOpsDays, look around, there may be one near you! I help organize DevOpsDays Austin (just had our third annual) and there’s ones coming this year from Tel Aviv to Minneapolis.
If you went to DoD SV, feel free and comment below with your thoughts (linking any posts you’ve made, slides, etc. is welcome too)!
Filed under Conferences, DevOps
DevOpsDays Silicon Valley 2014 Day One Notes
I have more notes from Velocity, but thought I’d do DevOpsDays first while it’s freshest in my brain. This isn’t a complete report, it’s just my thoughts on the parts I felt moved to actually write down or gave me a notable thought. More notes when I was learning, less when I wasn’t (not a reflection on the quality of the talk, just some things I already knew a bit about).
DevOpsDays Silicon Valley 2014 was June 27-28 at the San Jose Computer Museum. 500 people registered; not sure how many showed but I’d guess definitely in excess of 400.
Day One
State of the Union
First we had John Willis (@botchagalupe) giving the DevOps State of the Union. Here’s the slides (I know it says Amsterdam, he gave it there too.) This consisted of two parts – the first was a review of Gene Kim et al’s 2014 State of DevOps Report – go download it if you haven’t read it, it’s great stuff.
The second part is about how we are moving towards software defined everything – robust API driven abstractions decoupled from the underlying infrastructure. John’s really into software defined networking right now as it’s one of the remaining strongholds of static-suckiness in most infrastructures. A shout out to the blog at networkstatic.net and tools like mesos and Google’s kubernetes that are making computing even more fluid (see this article for some basics). “Consumable, composable infrastructure.”
Saying No
Next, our favorite Kanban expert Dominica DeGrandis (@dominicad) spoke on “Why Don’t We Just Say No?” Here’s the slides. As a new product manager, and as a former engineering manager who had engineers that would just take on work till they burst even with me standing there yelling “No! Don’t do it!”, it’s an interesting topic.
Why do you take on more work than you have capacity to do? She cites The Book Of No by Susan Newman, Ph. D and a very recent Psychology Today “Caveman Logic” post called Why So Many People Just Can’t Say No. She proposes that it is easier for devs to say no; ops have more pressing demands and are forced into too much yes. Some devs took exception to this on twitter – “our product people make us do all kinds of stuff we don’t like to” – but I think that’s different from the main point here. It’s not that “you have to do something you don’t like and are overruled when you say no” but that “you become severely over-committed due to requests from many quarters and being unwilling to say no.”
She goes through a great case study of changing over a big ops shop to a more modern “SRE” model and handle both interrupt and project work by getting metrics, having a lower WIP limit, closing out >90 day old tickets, and saying no to non-emergency last minute requests. In fact, the latter is why I prefer scrum over kanban for operations so far – she contended that devs have an easier time saying no to interrupt work because of the sprint cadence. OK, so adopt a sprint cadence! Anyway, by having some clear definitions of done for workflow stages they managed to improve the state of things considerably. Use kaizen. The book about the Pixar story, Creativity Inc., talks about how the Pixar folks were running themselves ragged to try to finish Toy Story, till someone left their baby in a car because they were too frazzled. “Asking this much of people, even when they wanted to give it, was not acceptable.” What should your WIP level be? The level of “personal safety” would be a great start!
It’s interesting – I did some of these things at Bazaarvoice and tried to do some other ones too. But often times the resistance would be from the engineers that the current process was working to death. “We can’t close those old tickets! They have valuable info and analysis and it’s something that needs to happen!” “Yes, but our rate of work done and rate of work intake proves mathematically that they’ll never get done. Keeping them open is therefore us making a false promise to whoever logged those tickets.” Not everyone is able to ruthlessly apply logic to problems – you’d think that would be an engineer attribute but in my experience, not really any more than the general population. But given that “not acceptable” quote above, I really struggled with how to get engineers who were burning themselves out to quit it. It’s harder than you’d think.
Agile at Scale
Next was a fascinating case study from Capital One’s transformation to an agile, BDD, devops-driven environment given by Adam Auerbach (@bugman31). The slides are available on Slideshare. They used the Scaled Agile Framework (SAFe) and BDD/acceptance test driven development with cucumber as well as continuous integration. In a later openspace there were people from Amex, city/state/federal governments, etc. trying to do the same thing – Agile and DevOps aren’t just for the little startups any more! He reported that it really improved their quality. Hmm, from the Googles it looks like the consulting firm LitheSpeed was involved, I met one of their principals at Agile Austin and he really impressed me.
Sales and Marketing Too
Sarah Goff-DuPont (@devtoolsuperfan) spoke about having sales and marketing join the agile teams as well. Some tips included cross-pollinating metrics and joining forces on customer outreach.
Ignites
Just some quick thoughts from the day one Ignites.
- @eriksowa on OODA and front end ops and screaming at your team in German (I am in favor of it)
- Aater (futurechips) on data acquisition and multitenancy with docker
- Jason Walker on LegoOps
- Ho Ming Li on Introducing DevOps
- @seemaj from Enstratius on classic to continuous delivery – slides. Pretty meaty with lots of tool shout-outs – grunt, bowler, angular, yo, bootstrap, grails, chef, rundeck, hubot, etc. I don’t mind a good laundry list of things to go find out more about!
- Matt Ho on Docker+serf – with Docker there is a service lookup challenge. AWS tagging is a nice solution to that. Serf does that with docker like a peer-to-peer zookeeper. Then he used moustache to generate configs. This is worth looking at – I am a big fan of this approach (we did it ourselves at National Instruments years ago) and I frankly think it’s a crime that the rest of the industry hasn’t woken up to it yet.
Openspaces
If you haven’t done openspaces before, it’s where attendees pitch topics and the group self-organizes into a schedule around them. Here’s some pics of part of the resulting schedule:



I went to two. The first was a combination of two openspace pitches, “Enterprise DevOps” and “ITIL, what should it be?” This was unfortunately a bad combination. Most folks wanted to talk about the former, and the Capital One guy was there and people from Amex etc. were starting to share with the group. But the ITIL question was mostly driven by a guy from the company that “bought ITIL” from the UK government and he had a bit of a vendory agenda to push. So most of the good discussion there happened between smaller groups after it broke up.
The second was a CI/CD pipeline one, and I got this great pic of what people consider to be “the new standard” pipeline.
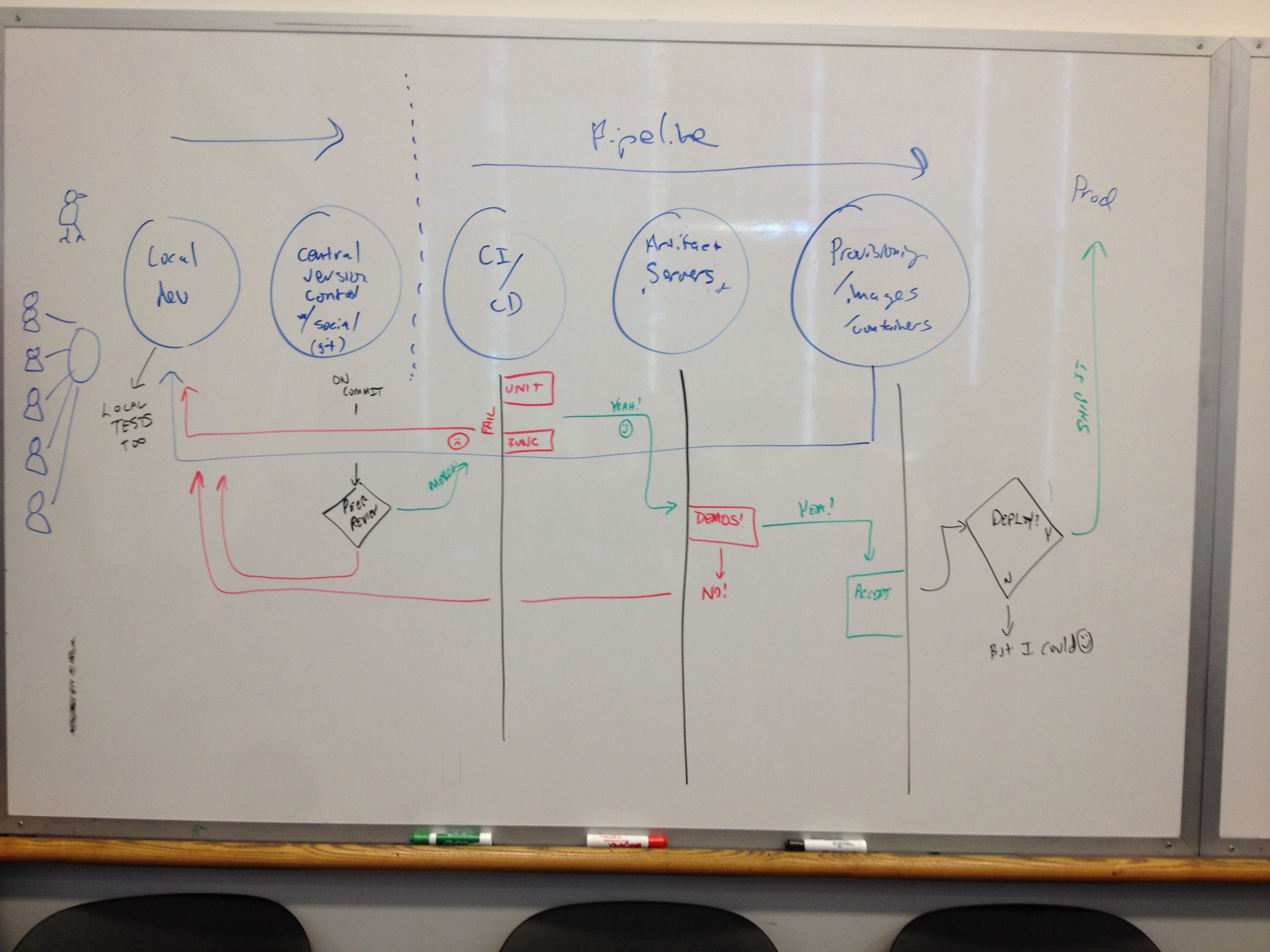
Generally Accepted Continuous Integration and Delivery Pipeline
Next, Day 2 and wrap-up!
Filed under Conferences, DevOps
Opening Velocity 2014
All right, I’m here in sunny San Jose for Velocity, the three-day Web operations and performance conference. It’s my first time attending as a sponsor type which is interesting. We have a whole cadre going; I flew in with Jenny and Lauren from Copperegg as part of the advance squad. Because I just got in on this gig recently, I am out at the Avatar while they’re at the Hilton nearby. On the cab ride, they got a bit agitated over a tweet claiming we’re being exclusionary over our “The Dude” promos; I guess I can see the misunderstanding but it’s a Big Lebowski theme specifically cooked up by the women in our Marketing department.
Some IHOP breakfast, a long walk from the Avatar to the convention center, and then speaker checking, where I got to chat with Mandy Walls, Vladimir Vuskan, and Andrew “Clay” Shafer. Apparently there’s a two person limit on booth setup so I don’t have to help with that. I’ll go report on Andrew’s talk, though will have to duck out early for speaker orientation for my talk.
Remember, if you can’t make it they’ll be streaming the morning keynotes on Wed/Thurs. If you are here, grab me and say “Hi!”
Filed under Conferences
Meet The Agile Admins At Velocity/DevOpsDays Silicon Valley!
Three of the four agile admins (James, Karthik, and myself) will be out at Velocity and DevOpsDays this week. Say hi if you see us!
James will be doing a workshop with Gareth Rushgrove on Tuesday 9-10:30 AM, “Battle-tested Code without the Battle – Security Testing and Continuous Integration.” Get hands on with gauntlt and other tools! [Conference site] [Lanyrd]
Ernest is doing a 5 minute sponsor keynote on Thursday, “A 5 Minute Checklist for Application Monitoring.” OK, so it’s during the USA vs Germany game – come see me anyway! I hate keynote sales pitches so I’m not doing one, I’ll be talking about a Lean approach to monitoring and stuff to cover in your MVP. There’s a free white paper too since what can you really say in 5 minutes? And so you know what to expect, the hashtag you’ll want to use is #getprobed! [Conference site] [Lanyrd]
Filed under Conferences
Monitoring and the State of DevOps
If you haven’t read the new 2014 State of DevOps Report from Puppet Labs and other luminaries, check it out now!
I also pulled out some of their findings on monitoring to inspire a post for the Copperegg blog, Monitoring and the State of DevOps, which I thought I’d mention here too.
Filed under DevOps, Monitoring
Filtering Your Datadog Event Stream
At both NI and Bazaarvoice I was a Datadog user; I wrote a piece for them on filtering the event stream that has just been published on the Datadog blog. Check it out!
Filed under DevOps
Agile Organization: Separate Teams By Discipline
This is the first in the series of deeper-dive articles that are part of Agile Organization Incorporating Various Disciplines. It’s very easy to keep reorganizing and trying different models without actually learning from the process. I’ve worked with all of these so am trying to condense the pros and cons to help people understand the implications of the type of organizational model they choose.
The Separate Team By Discipline Model
Separate teams striated by discipline is the traditional method of organizing technical teams – segmented horizontally by technical skill. You have one or more development teams, one or more operations teams, one or more QA teams. In larger shops you have even more horizontal subdivisions – like in an enterprise IT shop, under the banner of Infrastructure you might have a data center team, a UNIX admin team, a SAN team, a Windows admin team, a networking team, a DBA team, a telecom team, applications administration team(s), and so on. It’s more unusual to have the dev side specifically segmented horizontally by tech as well (“Java programmers,” “COBOL programmers,” “Javascript programmers”) but not unheard of; it is more commonly seen as “UX team, services team, backend team…”
 In this setup in its purest form, each team takes on tasks for a given product or project inside their team, works on them, and either returns them to the requester or passes them through to yet another team. Team members are not dedicated to that product or effort in any way except inasmuch as the hours they spend working on the to-do(s). Usually this is manifested as a waterfall approach, as a product or feature is conceived, handed to developers to develop, handed to QA to test, and finally handed to Operations to deploy and maintain.
In this setup in its purest form, each team takes on tasks for a given product or project inside their team, works on them, and either returns them to the requester or passes them through to yet another team. Team members are not dedicated to that product or effort in any way except inasmuch as the hours they spend working on the to-do(s). Usually this is manifested as a waterfall approach, as a product or feature is conceived, handed to developers to develop, handed to QA to test, and finally handed to Operations to deploy and maintain.
This model dates back to the mainframe days, where it works pretty well – you’re not innovating on the infrastructure side, the building’s been built, you’re moving your apps into the pre-built apartment units. It also works OK when you have heavy regulation requirements or are constrained to extensively documenting requirements, then design, etc. (government contracts, for example).
It works a lot less well when you need to move quickly or need any kind of change or innovation from the other teams to achieve your goal. Linking up prioritization across teams is always hard but that’s the least of the issues. Teams all have their own goals, their own cadences, and even their own cultures and languages. The oft-repeated warning that “devs are motivated to make changes and ops is motivated by system stability” is a trivial example of this mismatch of goals. If the shared teams are supporting a limited number of products it can work. When there are competing priorities, I’ve seen it be extremely painful. I worked in a shop where the multiple separate dev teams were vertical (line of business organized) but the operations teams were horizontal (technical specialty organized) – and frankly, the results of trying to produce results with the impedance mismatch generated by that setup was the nightmare that sent me down the Agile and DevOps path initially.
Benefits of Disciplinary Teams
The primary benefit of this approach is that you tend to get stable teams of like individuals, which allows them to bond with those of similar skills and experience organizational stability and esprit de corps. Providing this sense of comfort ends up being the key challenge of the other organizational approaches.
The second benefit is that it provides a good degree of standardization across products – if one ops team is creating the infrastructure for various applications, then there will be some efficiencies there. This is almost always at least partially, and sometimes more than entirely, counteracted in value by the fact that not all apps need the same thing and that centralized teams bottleneck delivery and reduce velocity. I remember the UNIX team that would only provide my Web team expensive servers, even though we were highly horizontally scaled and told them we’d rather have twice as many $3500 servers instead of half as many $7000 servers as it would serve uptime, performance, etc. much better. But progress on our product was offered up upon the altar of nominal cost savings from homogeneity.
The third benefit is that if the horizontal teams are correctly cross-trained, it is easier avoid having single points of failure; by collecting the workers skilled in something into one group, losses are more easily picked up by others in the group. I have to say though, that this benefit is often more honored in the breach in my experience – teams tend to naturally divide up until there’s one expert on each thing and managers who actively maintain a portfolio and drive crosstraining are sadly rare.
Drawbacks of Disciplinary Teams
Conway’s Law is usually invoked to worry about vertical divisions in a product – one part of the UI written by one team, another by another, such that it looks like a Frankenstein’s monster of a product to the end user. However, the principle applies to horizontal divisions as well – these produce more of a Human Centipede, with the issue of one phase becoming the input of the next. The front end may not show any clear sign of division, but the seams in quality, reliability, and agility of the system can grow like a cancer underneath, which users certainly discover over time.
This approach promotes a host of bad behaviors. Pushing work to other people is always tempting, as is taking shortcuts if the results of those shortcuts fall on another’s shoulders. With no end to end ownership of a product, you get finger pointing and no one taking responsibility for driving the excellence of the service – and without an overall system thinking perspective, attempts at one of the teams in that value chain to drive an improvement in their domain often has unintended effects on the other teams in that chain that may or may not result in overall improvement. If engineers don’t eat their own dog food, but pass it on to someone else, then chronic quality problems often result. I personally spent years trying to build process and/or relationships to try to mitigate the dev->QA->ops passing of issues downstream with only mixed success.
Another way of stating this is that shared services teams always provide a route to the tragedy of the commons. Competing demands from multiple customers and the need for “nonfunctional” requirements (performance, availability, etc.) could potentially be all reconciled in priority via a strong product organization – but in my experience this is uncommon; product orgs tend to not care about prioritization of back end concerns and are more feature driven. Most product orgs I have dealt with have been more or less resistant to taking on platform teams, managing nonfunctional requirements, and otherwise interacting with that half of demands on the product. Without consistent prioritization, shared teams then become the focus of a lot of lobbying by all their internal customers trying to get resource. These teams are frequently understaffed and thus a bottleneck to overall velocity.
Ironically, in some cases this can be beneficial – technically, focusing on cost efficiency over delivering new value is always a losing game, but some organizations are self-unaware enough that they have teams continuing to churn out “stuff” without real ROI associated (our team exists therefore we must make more), in which case a bottleneck is actually helpful.
Mitigations for the weaknesses of this approach (abdication of responsibility and bottlenecking constraints) include:
- Very strong process guidance. “If only every process interface is 100% defined, then this will work”, the theory goes, just as it works on a manufacturing line. Most software creation, however, is not similar to piecing components together to make an iPod. In one shop we worked for years on making a system development process that was up to this task, but it was an elusive goal. This is how, for example, Microsoft makes the various Office products look the same in partial defiance of Conway’s Law – books and books of standards.
- Individuals on shared teams with functional team affinities. Though not going as far as embedding into a product team, you can have people in the shared teams who are the designated reps for various client teams. Again, this works better when there is a few-to-one instead of a many-to-one relationship. I had an ops team try this, but it was a many-to-one environment and each individual engineer ended up with three different ownership areas, which was overwhelming. In addition, you have to be careful not to simply dedicate all of one sort of work to one person, as you then create many single points of failure.
- Org variation: Add additional crossfunctional teams that try to bridge the gap. At one place I worked, the organization had accepted that trying to have the systems needs of their Web site fulfilled by six separate infrastructure teams was not working well, so they created a “Web systems” team designed to sit astride those, take primary responsibility, and then broker needs to the other infrastructure teams. This was an improvement, and led to the addition of a parallel team responsible for internal apps, but never really got to the level of being highly effective. In addition those were extremely high-stress roles, as they bore responsibility but not control of all the results.
Conclusion
Though this is the most typical organization of technology teams historically, that history comes from a place much different than many situations we find ourselves in today. The rapid collaboration approach that Agile has brought us, and the additional understanding that Lean has given us in the software space, tells us that though this approach has its merits it is much overused and other approaches may be more effective, especially for product development.
Next, we’ll look at embedded crossfunctional service teams!
Use Gauntlt to test for Heartbleed
Heartbleed is making headlines and everyone is making a mad dash to patch and rebuild. Good, you should. This is definitely a nightmare scenario but instead of using more superlatives to scare you, I thought it would be good to provide a pragmatic approach to test and detect the issue.
@FiloSottile wrote a tool in Go to check for the Heartbleed vulnerability. It was provided as a website in addition to a tool, but when I tried to use the site, it seemed over capacity. Probably because we are all rushing to find out if our systems are vulnerable. To get around this, you can build the tool locally from source using the install instructions on the repo. You need Go installed and the GOPATH environment variable set.
go get github.com/FiloSottile/Heartbleed
go install github.com/FiloSottile/Heartbleed
Once it is installed, you can easily check to see if your site is vulnerable.
Heartbleed example.com:443
Cool! But, lets do one better and implement this as a gauntlt attack so that we can make sure we don’t have regressions and so that we can automate this a bit further. Gauntlt is a rugged testing framework that I helped create. The main goal for gauntlt is to facilitate security testing early in the development lifecycle. It does so by wrapping security tools with sane defaults and uses Gherkin (Given, When, Then) syntax so it easily understood by dev, security and ops groups.
In the latest version of gauntlt (gauntlt 1.0.9) there is support for Heartbleed–it should be noted that gauntlt doesn’t install tools, so you will still have to follow the steps above if you want the gauntlt attacks to work. Lets check for Heartbleed using gauntlt.
gem install gauntlt
gauntlt --version
You should see 1.0.9. Now lets write a gauntlt attack. Create a text file called heartbleed.attack and add the following contents:
@slow
Feature: Test for the Heartbleed vulnerability
Scenario: Test my website for the Heartbleed vulnerability (see heartbleed.com for more info)
Given "Heartbleed" is installed
And the following profile:
| name | value |
| domain | example.com |
When I launch a "Heartbleed" attack with:
"""
Heartbleed <domain>:443
"""
Then the output should contain "SAFE"
You now have a working gauntlt attack that can be hooked into your CI/CD pipeline that will test for Heartbleed. To see this example attack file on github, go to https://github.com/gauntlt/gauntlt/blob/master/examples/heartbleed/heartbleed.attack.
To run the attack
$ gauntlt ./heartbleed.attack
You should see output like this
$ gauntlt ./examples/heartbleed/heartbleed.attack
Using the default profile...
@slow
Feature: Test for the Heartbleed vulnerability
Scenario: Test my website for the Heartbleed vulnerability (see heartbleed.com for more info) # ./examples/heartbleed/heartbleed.attack:4
Given "Heartbleed" is installed # lib/gauntlt/attack_adapters/heartbleed.rb:4
And the following profile: # lib/gauntlt/attack_adapters/gauntlt.rb:9
| name | value |
| domain | example.com |
When I launch a "Heartbleed" attack with: # lib/gauntlt/attack_adapters/heartbleed.rb:1
"""
Heartbleed <domain>:443
"""
Then the output should contain "SAFE" # aruba-0.5.4/lib/aruba/cucumber.rb:131
1 scenario (1 passed)
4 steps (4 passed)
0m3.223s
Good luck! Let me (@wickett) know if you have any problems.
Amazon Cuts Prices Too
Well, if nothing else I’m happy to have Google Cloud around to provide some competition to push Amazon Web Services. Immediately after Google announced dramatic price drops, Amazon has responded doing the same!
Now if they can only also shame them into dropping their whole crazy reserve instance scheme and go to progressive discounts like Google just did too, the world will be better.
March 27, 2014 · 7:10 am
